
Ciągłe przewijanie i pustka GSC: czy wprowadzenie ciągłego przewijania w wynikach wyszukiwania Google na komputerze wpłynęło na wyświetlenia i kliknięcia? [Badanie]
Opublikowany: 2023-01-25
5 grudnia 2022 r. firma Google wprowadziła ciągłe przewijanie wyników wyszukiwania w języku angielskim na komputery w przypadku zapytań w języku angielskim. Ciągłe przewijanie umożliwia użytkownikom płynne przechodzenie do drugiej strony i dalej bez konieczności klikania przycisku „Dalej” u dołu wyników . Nastąpiło to po wprowadzeniu przez Google ciągłego przewijania wyników na urządzeniach mobilnych w październiku 2021 r. (ponownie, tylko w USA dla zapytań w języku angielskim).
Oto ogłoszenie Google dotyczące wdrożenia na komputer na początku grudnia (z gifem ciągłego przewijania w akcji):
Po wprowadzeniu na komputer wiele osób zastanawiało się, jak ciągłe przewijanie wpłynie na widoczność rankingów wykraczających poza pierwszą stronę. Na przykład w przypadku witryn z adresami URL w rankingu na drugiej stronie, a może nawet na górze strony, możliwość łatwego przewijania przez użytkowników do dodatkowych stron wyników wyszukiwania powinna prowadzić do większej liczby wyświetleń, kliknięć i konwersji. W każdym razie taki jest pomysł i coś, co postanowiłem przeanalizować.
Zanim ciągłe przewijanie zostało wprowadzone w SERP, ranking na drugiej stronie i później oznaczał, że Twoje wpisy prawdopodobnie nie byłyby zbyt często widoczne. Jasne, niektórzy odważą się przejść na stronę drugą i dalej, ale większość zostanie na stronie pierwszej (i po prostu zawęzi wyszukiwanie, jeśli po zeskanowaniu wyników nie znajdzie tego, czego szuka). Ale dzięki ciągłemu przewijaniu użytkownicy mogą łatwo przejść do drugiej strony wyników bez konieczności klikania przycisku. Nowe wyniki pojawiają się po prostu, gdy zbliżasz się do dolnej części początkowego zestawu wyników.
Analizowanie ciągłego przewijania w wynikach wyszukiwania komputerowego w Stanach Zjednoczonych:
Zaraz po wprowadzeniu ciągłego przewijania na komputery stacjonarne opublikowałem post wyjaśniający, jak analizować zmiany w wyświetleniach, kliknięciach i współczynniku klikalności na podstawie tego, że użytkownicy mogą bezproblemowo przeglądać więcej ofert w wynikach wyszukiwania. Mój samouczek wyjaśnia, jak używać GSC API i Analytics Edge w Excelu do masowego eksportowania danych z GSC, filtrowania według komputerów tylko ze Stanów Zjednoczonych, porównywania ram czasowych, a następnie filtrowania według wyników ze strony drugiej i trzeciej. Powstałe arkusze robocze szybko przedstawiają zmiany w metrykach podczas porównywania ram czasowych przed i po wdrożeniu ciągłego przewijania.
Po opublikowaniu tego postu niecierpliwie czekałem na zgromadzenie większej ilości danych, aby móc zagłębić się w raportowanie w różnych witrynach. Dokładnie to zrobiłem dla wielu witryn z różnych branż. Wiedziałem, że witryny będą miały mnóstwo danych do przeanalizowania i to w różnych branżach, więc powinno być łatwiej dostrzec różnice w oparciu o ciągłe przewijanie w SERP na komputery stacjonarne w Stanach Zjednoczonych.
Poniżej omówię zastosowaną przeze mnie metodologię, przeanalizowane dane, kilka interesujących (i przerażających) ustaleń dotyczących danych GSC oraz wpływ lub jego brak ciągłego przewijania w wynikach wyszukiwania na komputerze. Wskoczmy.
Metodologia:
Najpierw wybrałem dwanaście różnych witryn, które mają stały i znaczny ruch z bezpłatnych wyników wyszukiwania Google. Niektóre z nich to witryny na dużą skalę generujące wiele kliknięć z bezpłatnych wyników wyszukiwania Google, podczas gdy inne to witryny niszowe generujące mniejszy ruch (ale nadal dużą liczbę kliknięć). Upewniłem się, że witryny znajdują się w różnych branżach i że święta nie miały dużego wpływu na te branże (na tyle, na ile mogłem). Skoncentrowałem się również na wynikach ze Stanów Zjednoczonych, ponieważ ciągłe przewijanie nie zostało jeszcze wprowadzone na całym świecie.
Następnie wykorzystałem proces, który opisałem w moim samouczku, do analizy zmian metryk w oparciu o zbiorcze eksportowanie danych z GSC, filtrowanie według komputerów stacjonarnych tylko z USA, porównywanie ram czasowych, a następnie filtrowanie według wyników ze strony drugiej i trzeciej. Możesz sprawdzić mój samouczek, jak to zrobić za pomocą GSC API, Excela i Analytics Edge.
Analizując dane, upewniłem się, że przejrzałem zapytania, w których średnia pozycja była mniej więcej taka sama przed i po wprowadzeniu ciągłego przewijania. Na przykład nie przeglądałbym zapytania, które miało ranking 24 przed aktualizacją, a następnie 16 po. To duża różnica i oczywiście może mieć wpływ na dane. Szukałem zapytań, w których witryna zajmowała mniej więcej tę samą pozycję, aby móc lepiej przeanalizować, czy ciągłe przewijanie ma wpływ na widoczność i zaangażowanie.
Jeśli chodzi o ruch w bezpłatnych wynikach wyszukiwania Google dla dwunastu witryn, podałem liczbę kliknięć w ciągu ostatnich trzech miesięcy dla każdej z analizowanych witryn (tak, abyś mógł wyczuć, jaki ruch generował ostatnio ruch z Google).
Witryny uzyskały od 89 mln kliknięć do 1,4 mln kliknięć w ciągu ostatnich trzech miesięcy i obejmowały szereg branż:
- Witryna 1: 89 mln kliknięć
- Witryna 2: 31 mln kliknięć
- Witryna 3: 8,6 mln kliknięć
- Witryna 4: 4,8 mln kliknięć
- Witryna 5: 3,8 mln kliknięć
- Witryna 6: 3,4 mln kliknięć
- Witryna 7: 2,8 mln kliknięć
- Witryna 8: 1,4 mln kliknięć
Pustka GSC: ciemna, mętna i niejednoznaczna
Po pierwsze, rzeczywistość filtrowanych danych GSC mocno uderzyła po wyeksportowaniu danych na podstawie zapytania. Barry Schwartz opisał to w lipcu 2022 r. po tym, jak Patrick Stox napisał post wyjaśniający, co widzi w witrynach z danymi filtrującymi GSC. Niesamowite było zobaczyć, jak wiele danych zostało przefiltrowanych dla niektórych witryn…
Kiedy sprawdzałem w tym czasie różne witryny, zauważyłem również ogromne luki w danych podczas eksportowania na podstawie zapytania. Na przykład suma u góry raportu Skuteczność w GSC może być znacznie większa niż po wyeksportowaniu danych według zapytania (a następnie zsumowaniu kliknięć i wyświetleń). I mam na myśli WAY OFF. W przypadku niektórych witryn, które analizowałem w tym czasie, po wyeksportowaniu danych widziałem tylko 20% całości. Tak, to oznacza, że 80% danych zostało przefiltrowanych.
Powodem jest to, że Google filtruje zapytania na podstawie obaw o prywatność. W swojej dokumentacji, którą udoskonalił po badaniu Patricka, Google wyjaśnia, że filtruje „zanonimizowane zapytania”, aby chronić prywatność użytkowników. W przypadku niektórych witryn może to być mnóstwo danych. Warto zauważyć, że eksport według strony da pełne wyniki (lub zamknięcie), ale eksport według zapytania podkreśla to, co nazywam pustką GSC.

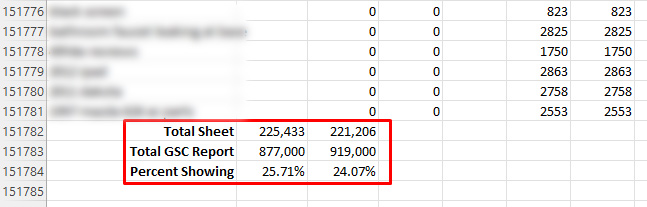
Powrót do ciągłego przewijania danych… W przypadku dwunastu analizowanych przeze mnie witryn niektóre usługi GSC dostarczały tylko 20-30% wszystkich danych raportowanych w raportach dotyczących wydajności ze względu na filtrowanie. Dobrze to przeczytałeś. Oznacza to, że 70-80% zostało odfiltrowanych pod kątem tych witryn.
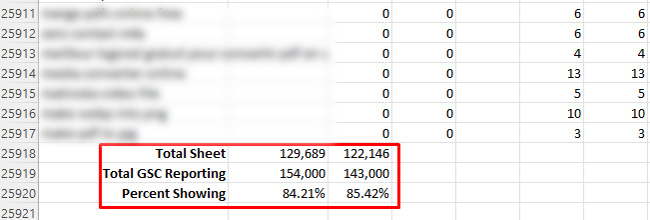
Z drugiej strony widziałem aż 84% wyświetlanych danych (czyli 16% przefiltrowanych), ale to było najwięcej, co mogłem znaleźć na podstawie przeglądu wielu właściwości w GSC. Nie zrozumcie mnie źle, to znacznie lepiej niż 24%!
Kiedy zobaczyłem ilość filtrowania, wiedziałem, że mam dość pracy związanej z analizą danych. Miałem nadzieję, że wystarczy, aby zobaczyć zmiany oparte na ciągłym rozwijaniu zwoju… Jedno było pewne, pustka GSC była ciemna i mętna.
Ciemne i mętne: analiza wpływu na wyświetlenia, kliknięcia i współczynnik klikalności.
Po pierwsze, „Dark and Murky” nie jest nazwą nowego, modnego napoju, który można zamówić przy basenie w kurorcie. To tylko pierwsza rzecz, jaką powiedziałem po przejrzeniu danych z analizowanych witryn. Kiedy minąłem pierwszą stronę wyników, liczba w większości witryn gwałtownie spada. Spadają tak bardzo, że prawie niemożliwe jest wyciągnięcie jakichkolwiek wniosków na temat tego, jak ciągłe przewijanie wpływa na kliknięcia i współczynnik klikalności z SERP na komputery stacjonarne.
Z punktu widzenia wyświetleń nie widziałem spójnego trendu ze wzrostem liczby wyświetleń. W przypadku niektórych zapytań liczba wyświetleń wzrosła. Dla innych spadły. I znowu, kliknięcia i współczynnik klikalności były bardzo trudne do przeanalizowania ze względu na niesamowicie niskie liczby poza pierwszą stroną.
Na przykład, gdy tylko sprawdziłem w arkuszu kalkulacyjnym wyniki drugiej strony w kilku witrynach, liczba kliknięć była nieistotna. Nawiasem mówiąc, to pokazuje, ile danych jest filtrowanych… Na pierwszej stronie niektóre zapytania generują dziesiątki tysięcy kliknięć lub więcej. Potem strona druga spada prawie do zera? Więc tak, pustka GSC jest prawdziwa i może poważnie utrudnić twoją analizę.
Oto kilka zrzutów ekranu z arkuszy kalkulacyjnych dla drugiej strony wyników wyszukiwania. Przygotuj się na rozczarowanie z punktu widzenia kliknięć. :)
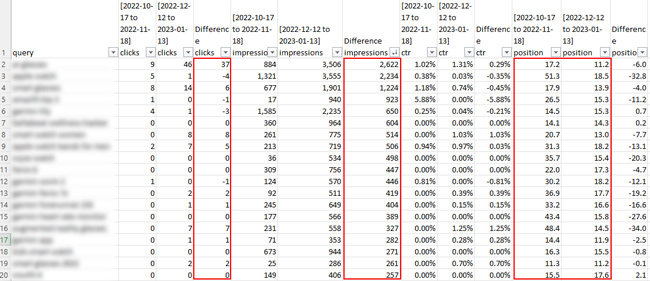
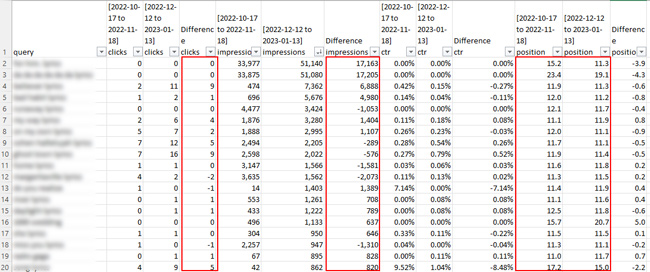
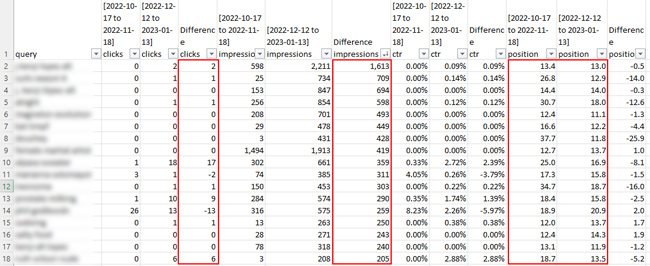
Wspomniałem jednak o jednej witrynie, w której przefiltrowano tylko 16% danych (co było najlepszym wynikiem, jaki znalazłem spośród dwunastu). W przypadku tej witryny można by pomyśleć, że mam wystarczająco dużo danych, aby wyciągnąć pewne wnioski… ale tak naprawdę nie. Kliknięcia były bardzo niskie po przeanalizowaniu strony drugiej i dalszych. Zauważyłem, że liczba wyświetleń wzrosła w przypadku wielu zapytań, ale liczba kliknięć nie. A ponieważ liczba kliknięć była tak niska, że przekroczyła pierwszą stronę, różnica we współczynniku klikalności nie miała sensu analizować.
Oto zrzut ekranu ze strony, która została odfiltrowana tylko w 14%:
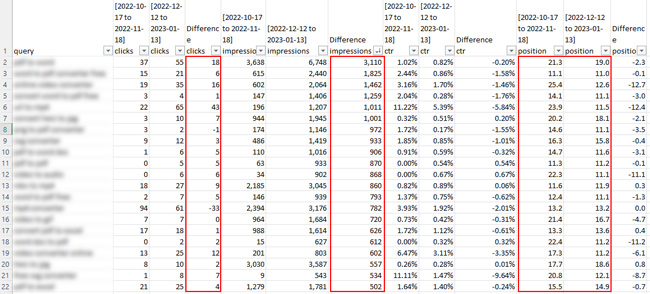
Na przykład dla jednego zapytania liczba wyświetleń wzrosła o 3110, ale liczba kliknięć wzrosła tylko o 18. Średnia pozycja wzrosła z 21,3 do 19,0, czyli blisko, ale mogło to oznaczać skok z trzeciej strony wyników do drugiej. Najwyraźniej nie jest to wystarczająca ilość danych, aby wyciągnąć jakiekolwiek wnioski. Wzrost wyświetleń to jedno, ale kliknięć było tak mało, że niewiele to znaczyło. I szczerze mówiąc, komu naprawdę zależy na wzroście wyświetleń, jeśli nie ma kliknięć. Dla większości właścicieli witryn nie jest to tak naprawdę ćwiczenie promujące markę. Chcą kliknięć i kolejnych konwersji! :)
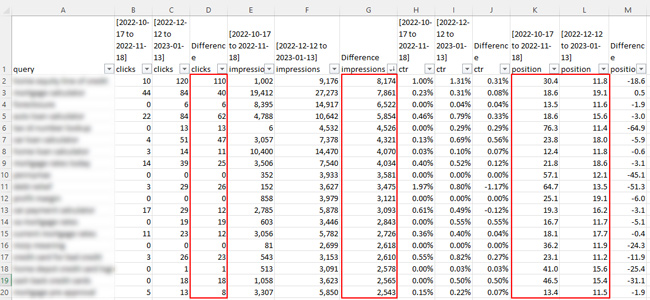
Oto kolejna witryna, w której nastąpił znaczny wzrost liczby wyświetleń w przypadku niektórych zapytań i zdecydowanie wzrost liczby kliknięć w przypadku niektórych zapytań. To powiedziawszy, niektóre wzrosty wynikały ze znacznie silniejszego rankingu witryny w ostatnich ramach czasowych. Nastąpił wzrost wyświetleń w przypadku niektórych zapytań, gdy witryna zajmowała mniej więcej tę samą pozycję w rankingu, ale po prostu nie ma wystarczającej liczby danych o kliknięciach, aby wyciągnąć jakiekolwiek poważne wnioski…
Kluczowe wnioski oparte na analizie ciągłego przewijania w wynikach SERP na komputery stacjonarne :
- Z moich analiz wynika, że na stronie drugiej i poza nią NIE ma zbyt wielu danych do przeanalizowania… Dotyczy to nawet dużych witryn z mnóstwem ruchu organicznego w Google. Jest to oparte na filtrowaniu anonimowych zapytań przez GSC.
- Zauważyłem wzrost liczby wyświetleń dla niektórych zapytań, ale trudno było mi wyciągnąć jakiekolwiek wnioski, ponieważ wiele z nich spadło, porównując również przedziały czasowe.
- Kliknięcia i współczynnik klikalności były jeszcze trudniejsze do analizy. Nie było zbyt wielu kliknięć do zgłoszenia poza pierwszą stroną, co bardzo utrudniało wyciągnięcie jakichkolwiek wniosków.
- Z punktu widzenia danych GSC miałem bardzo ograniczone dane oparte na filtrowaniu GSC. Zostało to zgłoszone wcześniej, a to badanie podkreśliło, jak bardzo filtrowanie ma miejsce. Na przykład niektóre eksporty dawały tylko 20-30% danych zgłoszonych w GSC w raportowaniu wydajności (podczas analizy według zapytania).
- Zalecam przejście przez ten proces dla własnych witryn, korzystając z opublikowanego przeze mnie samouczka (choćby z innego powodu niż zobaczenie surowego filtrowania danych GSC podczas eksportowania według zapytania). Uwaga: w przypadku eksportowania według stron powinieneś być w stanie zobaczyć pełne dane, ale istnieje wiele zapytań, które prowadzą do określonych stron (co może zamącić wody pod względem analizy).
Podsumowanie: Analiza limitów pustych GSC ciągłego przewijania w SERP
Po wprowadzeniu funkcji ciągłego przewijania w wynikach wyszukiwania na komputerze byłam bardzo podekscytowana analizą wpływu na wyświetlenia i kliknięcia na podstawie przewijania przez użytkowników do strony drugiej i dalszych. Niestety, filtrowanie danych GSC znacznie utrudniło moje wysiłki. Niektóre witryny zwracały tylko 20-30% wszystkich danych na podstawie filtrowania anonimowych zapytań przez GSC.
Z pewnością zaktualizuję ten post, jeśli natknę się na silniejsze ustalenia oparte na analizie ciągłego przewijania witryn. W międzyczasie zalecamy przejście przez ten proces we własnych witrynach. Nigdy nie wiadomo, GSC może nie filtrować tak wielu danych… Powodzenia.
GG