
用 R 挖掘 Emma Watson 的推文
已发表: 2018-02-03任何人的 Twitter 流都包含丰富的社交数据,可以揭示有关该人的很多信息。 由于 Twitter 数据是公开的,并且 API 对任何人开放,因此可以轻松应用数据挖掘技术来找出从时间模式和人们关注的主题到用于表达观点和想法的文本模式的所有内容。

在这项研究中,我们将使用R对最著名的名人之一(即 Emma Watson)发布的推文进行分析。 首先,我们将进行探索性分析,然后再进行文本分析。
提取 Emma Watson 的 Twitter 数据
Twitter API 允许我们下载 3,200 条最近的推文——我们需要做的就是创建一个 Twitter 应用程序来获取 API 密钥和访问令牌。 请按照以下步骤创建应用程序:
- 打开 https://apps.twitter.com
- 点击“创建新应用”
- 输入详细信息并单击“创建您的 Twitter 应用程序”
- 单击“密钥和访问令牌”选项卡并复制 API 密钥和秘密
- 向下滚动并单击“创建我的访问令牌”
有一个名为rtweet的R库,它将用于下载推文并创建数据框。 使用下面给出的代码继续:
[代码语言=“r”]
安装包(“httr”)
安装包(“rtweet”)
图书馆(“httr”)
图书馆(“rtweet”)
# 你创建的推特应用的名字
appname <-“推文分析”
# api 密钥(将以下示例替换为您的密钥)
键<-“8YnCioFqKFaebTwjoQfcVLPS”
# api 密码(将以下内容替换为您的密码)
秘密<-“uSzkAOXnNpSDsaDAaDDDSddsA6Cukfds8a3tRtSG”
# 创建名为“twitter_token”的令牌
twitter_token <- create_token(
应用程序 = 应用程序名称,
消费者密钥 = 密钥,
消费者秘密 = 秘密)
#下载艾玛·沃特森发布的推文
ew_tweets <- get_timeline(“EmmaWatson”,n = 3200)
[/代码]
探索性分析
在这里,我们将通过可视化以下内容来总结数据集:
- 2010 年至 2018 年发布的推文数量
- 几个月的推文频率
- 一周内的推文频率
- 一天的推文密度
- 转发推文和原始推文数量的比较
年度推文
我们将使用令人惊叹的ggplot2和lubridate库来绘制图表并处理日期。 继续并按照下面给出的代码安装和加载包:
[代码语言=“r”]
安装包(“ggplot2”)
安装包(“润滑”)
图书馆(“ggplot2”)
图书馆(“润滑”)
[/代码]
执行以下代码,通过分解为几个月来绘制多年来的推文数量:
[代码语言=“r”]
ggplot(数据 = ew_tweets,
aes(月(created_at,标签=真,缩写=真),
组=因子(年(created_at)),颜色=因子(年(created_at))))+
geom_line(stat=”count”) +
geom_point(stat=”count”) +
实验室(x=“月”,颜色=“年”)+
xlab(“月”) + ylab(“推文数”) +
主题最小()
[/代码]
结果如下图:
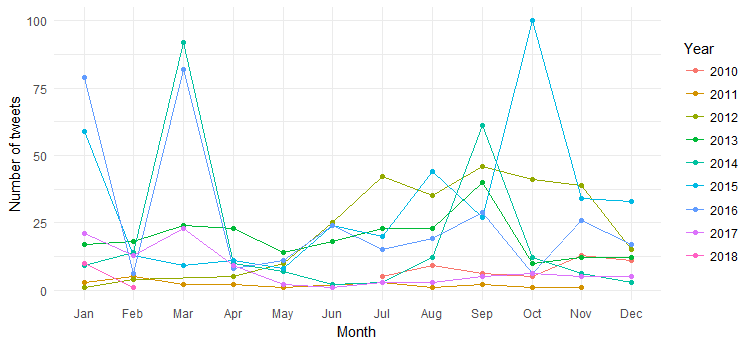
我们可以看到这些年来按月发布的推文(2014 年 3 月、2016 年 3 月和 2015 年 10 月的峰值)的中断,但很难解释。 现在让我们通过仅绘制逐年推文计数来简化图表。
[代码语言=“r”]
ggplot(data = ew_tweets, aes(x = year(created_at))) +
geom_bar(aes(fill = ..count..)) +
xlab(“年份”) + ylab(“推文数”) +
scale_x_continuous (breaks = c(2010:2018)) +
主题最小()+
scale_fill_gradient(低=“cadetblue3”,高=“chartreuse4”)
[/代码]
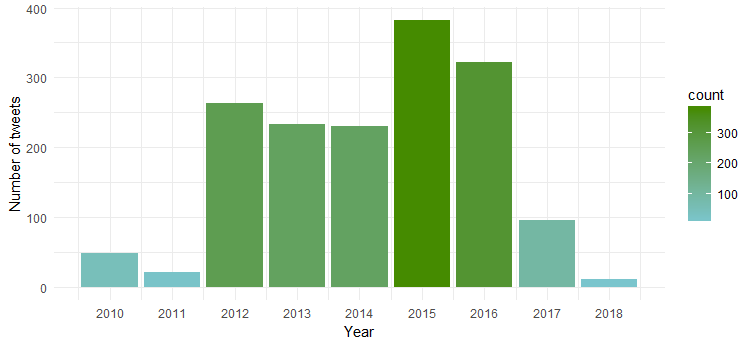
结果图表显示,她在 2015 年和 2016 年最活跃,而 2011 年的活动最少。
几个月的推文频率
现在让我们在 Emma Watson Twitter Data 中查找,看看她是否在一年中的几个月内发同样的推文,或者是否有任何特定月份她发推文最多。 使用以下代码创建图表:
[代码语言=“r”]
ggplot(data = ew_tweets, aes(x = month(created_at, label = TRUE))) +
geom_bar(aes(fill = ..count..)) +
xlab(“月”) + ylab(“推文数”) +
主题最小()+
scale_fill_gradient(低=“cadetblue3”,高=“chartreuse4”)
[/代码]
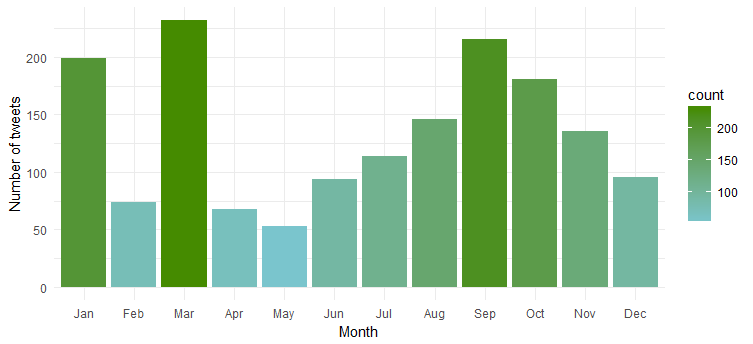
显然,她在“一月”、“三月”和“九月”期间最为活跃。
一周内的推文频率
一周中有没有哪一天是她最活跃的? 让我们通过执行以下代码来绘制图表:
[代码语言=“r”]
ggplot(data = ew_tweets, aes(x = wday(created_at, label = TRUE))) +
geom_bar(aes(fill = ..count..)) +
xlab(“星期几”) + ylab(“推文数”) +
主题最小()+
scale_fill_gradient(low = “turquoise3”, high = “darkgreen”)
[/代码]
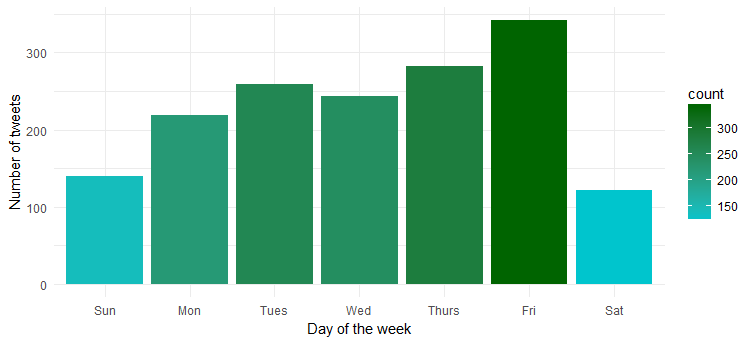
嗯……她周五最活跃。 可能正准备进入派对模式?
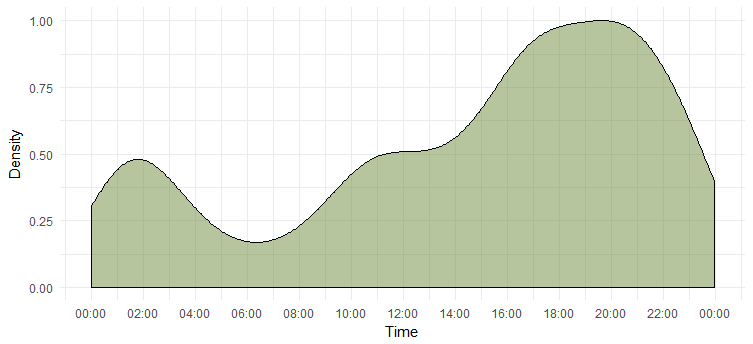
一天的推文密度
我们已经算出了最活跃的一天,但我们不知道她最活跃的时间。 下面这张图会给我们答案。
[代码语言=“r”]
# 用于存储和格式化一天中时间的包
安装包(“嗯”)
# 添加时间间隔和标签的包
install.packages(“秤”)
图书馆(“嗯”)
图书馆(“尺度”)
# 仅从时间戳中提取时间,即小时、分钟和秒
ew_tweets$time <- hms::hms(second(ew_tweets$created_at),
分钟(ew_tweets$created_at),
小时(ew_tweets$created_at))
# 转换为 `POSIXct` 因为 ggplot 与 `hms` 不兼容
ew_tweets$time <- as.POSIXct(ew_tweets$time)
ggplot(数据 = ew_tweets)+
geom_density(aes(x = time, y = ..scaled..),
填充=”darkolivegreen4”, alpha=0.3) +
xlab(“时间”) + ylab(“密度”) +
scale_x_datetime(breaks = date_breaks(“2 小时”),
标签 = date_format(“%H:%M”)) +
主题最小()
[/代码]

这告诉我们她在下午 6 点到 8 点最活跃 请注意,时区是 UTC(可以使用 `unclass` 函数找到。在发推特 Emma 时请记住这一点。
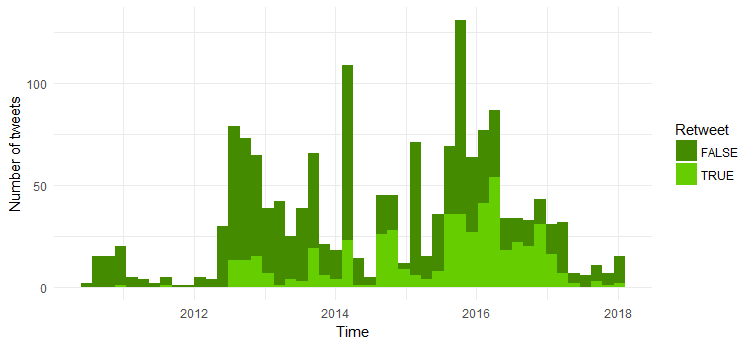
转发推文和原始推文数量的比较
现在我们将比较原始推文和转发推文的数量。 下面给出的是代码:
[代码语言=“r”]
ggplot(data = ew_tweets, aes(x = created_at, fill = is_retweet)) +
geom_histogram(bins=48) +
xlab(“时间”) + ylab(“推文数”) + theme_minimal() +
scale_fill_manual(值 = c(“chartreuse4”,“chartreuse3”),
名称=“转推”)
[/代码]
大多数推文是原创推文。 有趣的是,转发推文的数量自 2014 年以来有所增加。
文本挖掘
现在让我们进入更有趣的领域——我们将执行包括 NLP 在内的文本挖掘技术来找出以下内容:
1. 常用标签
2. 推文的词云
3. 情绪分析
1. 常用标签
下载的数据集已经有一个包含主题标签的列; 我们将使用它来找出 Emma 使用的前 10 个主题标签。 下面给出了为主题标签创建图表的代码:
[代码语言=“r”]
# 打包以轻松处理数据框
安装包(“dplyr”)
图书馆(“dplyr”)
# 从列表中获取主题标签
ew_tags_split <- unlist(strsplit(as.character(unlist(ew_tweets$hashtags)),'^c(|,|”|)'))
# 通过删除空格来格式化a
ew_tags <- sapply(ew_tags_split, function(y) nchar(trimws(y)) > 0 & !is.na(y))
ew_tag_df <- as_data_frame(table(tolower(ew_tags_split[ew_tags])))
ew_tag_df <- ew_tag_df[with(ew_tag_df,order(-n)),]
ew_tag_df <- ew_tag_df[1:10,]
ggplot(ew_tag_df, aes(x = reorder(Var1, -n), y=n)) +
geom_bar(stat=”identity”, fill=”darkslategray”)+
主题最小()+
xlab(“#Hashtags”) + ylab(“计数”)
[/代码]
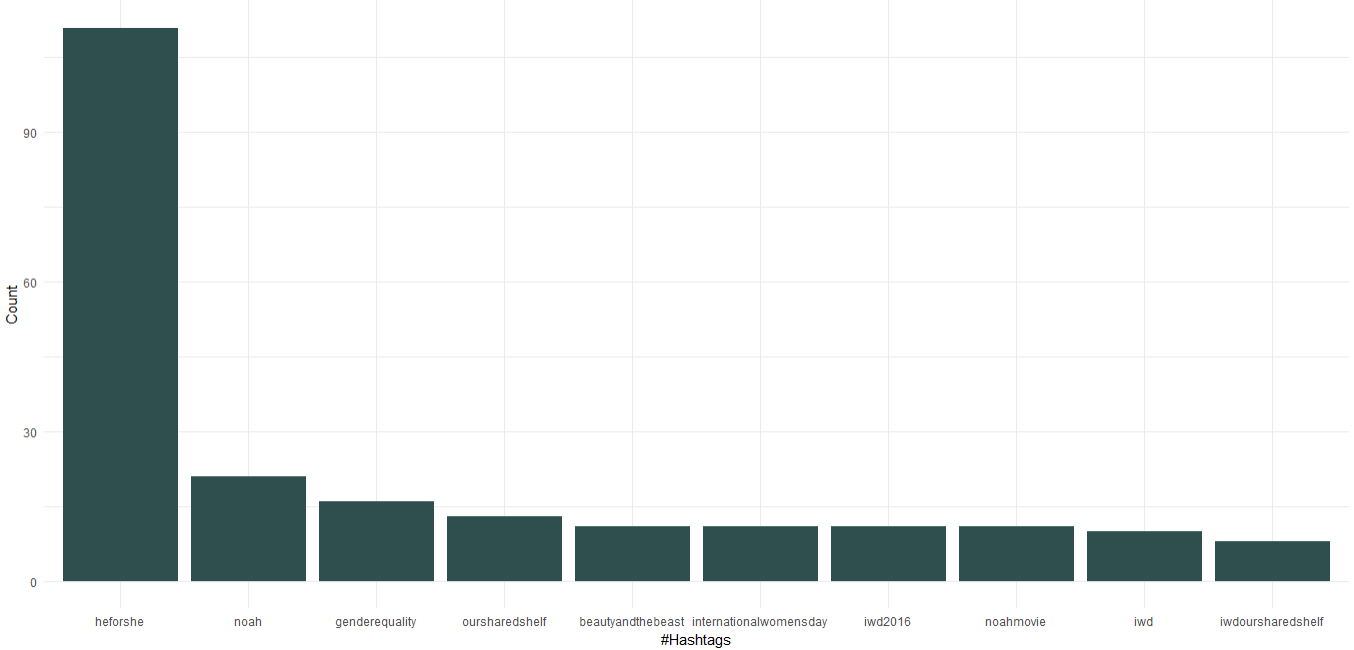
我们可以看到,作为联合国妇女署亲善大使,艾玛·沃特森(Emma Watson)发起了关注性别平等的“HeForShe”运动。 除此之外,她还推广了名为“我们的共享书架”和“国际妇女节”的读书俱乐部。 在电影中,“诺亚”、“美女与野兽”出现在前 10 个标签中。
2.词云
现在我们将分析推文文本以找出最常见的词并创建词云。 执行以下代码继续:
[代码语言=“r”]
#安装文本挖掘和词云包
install.packages(c(“tm”, “wordcloud”))
图书馆(“tm”)
图书馆(“wordcloud”)
tweet_text <- ew_tweets$text
#删除数字、标点符号、链接和字母数字内容
tweet_text<- gsub('[[:digit:]]+', ”, tweet_text)
tweet_text<- gsub('[[:punct:]]+', ”, tweet_text)
tweet_text<- gsub(“http[[:alnum:]]*”, “”, tweet_text)
tweet_text<- gsub(“([[:alpha:]])1+”, “”, tweet_text)
#创建文本语料库
文档 <- 语料库(向量源(tweet_text))
# 将编码转换为 UTF-8 以处理有趣的字符
docs <- tm_map(docs, function(x) iconv(enc2utf8(x), sub = “byte”))
# 将文本转换为小写
文档 <- tm_map(文档,content_transformer(下))
# 去除英语常用停用词
docs <- tm_map(docs, removeWords, stopwords(“english”))
# 删除我们指定为字符向量的停用词
docs <- tm_map(docs, removeWords, c(“amp”))
# 创建词条文档矩阵
tdm <- TermDocumentMatrix(文档)
# 将 tdm 定义为矩阵
m <- as.matrix(tdm)
# 按降序获取字数
word_freqs = sort(rowSums(m), 递减=TRUE)
# 创建一个包含单词及其频率的数据框
ew_wf <- data.frame(word=names(word_freqs), freq=word_freqs)
# 绘制词云
设置种子(1234)
wordcloud(words = ew_wf$word, freq = ew_wf$freq,
min.freq = 1,scale=c(1.8,.5),
max.words=200, random.order=FALSE, rot.per=0.15,
颜色=brewer.pal(8, “Dark2”))
[/代码]
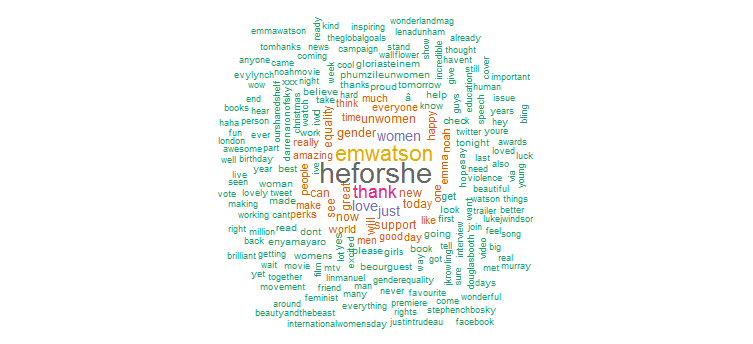
显然,她为“HeforShe”活动做了大力宣传。 其他常用词是“感谢”、“爱”、“妇女”、“性别”和“联合国妇女署”。 这显然与主题标签一致,这表明她的 Twitter 活动非常关注女性问题。
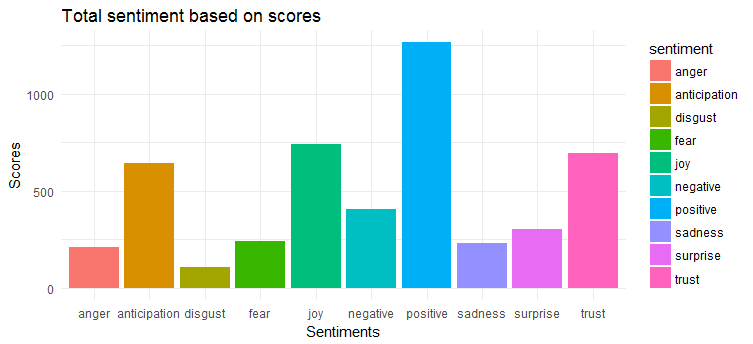
3. 情绪分析
对于情感提取和绘图,我们将应用syuzhet包。 该软件包基于情感词典,该词典将不同的单词与各种情感(喜悦、恐惧、愤怒、惊讶等)和情感极性(正面/负面)对应起来。 我们必须根据推文中出现的单词计算情感分数并绘制相同的图。
[代码语言=“r”]
install.packages(“syuzhet”)
图书馆(syuzhet)
# 将推文转换为 ASCII 以跟踪奇怪的字符
tweet_text <- iconv(tweet_text, from=”UTF-8″, to=”ASCII”, sub=””)
# 删除转发
tweet_text<-gsub(“(RT|via)((?:bw*@w+)+)”,””,tweet_text)
# 删除提及
tweet_text<-gsub(“@w+”,””,tweet_text)
ew_sentiment<-get_nrc_sentiment((tweet_text))
情绪评分<-data.frame(colSums(ew_sentiment[,]))
名称(sentimentscores)<-“分数”
情绪评分 <- cbind(“情绪”=行名(情绪评分),情绪评分)
行名(sentimentscores) <- NULL
ggplot(数据=sentimentscores,aes(x=sentiment,y=Score))+
geom_bar(aes(fill=sentiment),stat = “身份”)+
主题(legend.position=”none”)+
xlab(“情绪”)+ylab(“分数”)+
ggtitle(“基于分数的总情绪”)+
主题最小()
[/代码]
下图显示,推文大多具有积极的情绪。 表达最多的前三种情绪是“喜悦”、“信任”和“期待”。
交给你
在这项研究中,我们介绍了探索性数据分析和文本挖掘技术,以了解 Emma Watson 发布的推文的推文模式和潜在主题。 可以进行进一步分析以找出经常提到的推特用户,创建网络图并使用主题建模对推文进行分类。
遵循本教程并在评论部分分享您的发现。
