
Estrarre i Tweet di Emma Watson con R
Pubblicato: 2018-02-03Il flusso Twitter di qualsiasi persona contiene dati social ricchi che possono svelare molto su quella persona. Poiché i dati di Twitter sono pubblici e l'API è aperta a chiunque, le tecniche di data mining possono essere facilmente applicate per scoprire tutto, dagli schemi temporali e gli argomenti su cui la persona si concentra, ai modelli di testo utilizzati per esprimere opinioni e pensieri.

In questo studio utilizzeremo R per analizzare i tweet postati da una delle celebrità più famose, ovvero Emma Watson. Per prima cosa esamineremo l'analisi esplorativa e poi passeremo all'analisi del testo.
Estrazione dei dati di Twitter di Emma Watson
L'API di Twitter ci consente di scaricare 3.200 tweet recenti: tutto ciò che dobbiamo fare è creare un'app Twitter per ottenere la chiave API e il token di accesso. Segui i passaggi indicati di seguito per creare l'app:
- Apri https://apps.twitter.com
- Fai clic su "Crea nuova app"
- Inserisci i dettagli e clicca su 'Crea la tua applicazione Twitter'
- Fai clic sulla scheda "Chiavi e token di accesso" e copia la chiave API e il segreto
- Scorri verso il basso e clicca su “Crea il mio token di accesso”
Esiste una libreria R chiamata rtweet che verrà utilizzata per scaricare i tweet e creare un frame di dati. Utilizzare il codice riportato di seguito per procedere:
[lingua del codice =”r”]
install.packages(“httr”)
install.packages ("rtweet")
libreria ("httr")
libreria ("rtweet")
# il nome dell'app Twitter da te creata
appname <- "tweet-analytics"
# chiave API (sostituisci il seguente esempio con la tua chiave)
chiave <- "8YnCioFqKFaebTwjoQfcVLPS"
# api secret (sostituisci quanto segue con il tuo segreto)
segreto <- “uSzkAOXnNpsDsaDAaDDDSddsA6Cukfds8a3tRtSG”
# crea un token chiamato "twitter_token"
twitter_token <- create_token(
app = nomeapp,
chiave_consumatore = chiave,
consumatore_segreto = segreto)
#Download dei tweet postati da Emma Watson
ew_tweets <- get_timeline("EmmaWatson", n = 3200)
[/codice]
Analisi esplorativa
Qui riassumeremo il set di dati visualizzando quanto segue:
- Numero di tweet pubblicati dal 2010 al 2018
- Frequenza dei tweet nel corso dei mesi
- Frequenza dei tweet per una settimana
- Densità di tweet per un giorno
- Confronto del numero di re-tweet e tweet originali
Tweet annuali
Useremo la straordinaria libreria ggplot2 e lubridate per tracciare grafici e lavorare con le date. Vai avanti e segui il codice indicato di seguito per installare e caricare i pacchetti:
[lingua del codice =”r”]
install.packages ("ggplot2")
install.packages ("lubrificare")
libreria ("ggplot2")
libreria ("lubrificare")
[/codice]
Esegui il codice seguente per tracciare il conteggio dei tweet nel corso degli anni suddividendolo in mesi:
[lingua del codice =”r”]
ggplot(data = ew_tweets,
aes(mese(creato_at, etichetta=VERO, abbr=VERO),
gruppo=fattore(anno(creato_at)), color=fattore(anno(creato_at)))))+
geom_line(stat=”conteggio”) +
geom_point(stat=”conteggio”) +
labs(x=”Mese”, color=”Anno”) +
xlab("Mese") + ylab("Numero di tweet") +
tema_minimo()
[/codice]
Il risultato è il seguente grafico:
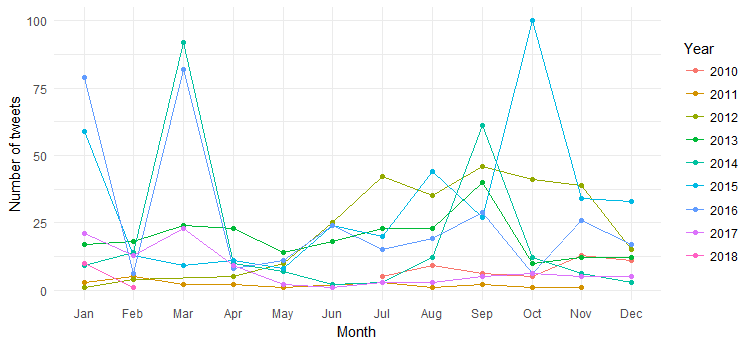
Possiamo vedere la rottura dei tweet mensili (picchi di marzo 2014, marzo 2016 e ottobre 2015) nel corso degli anni, ma l'interpretazione è difficile. Semplifichiamo ora il grafico tracciando solo i conteggi dei tweet per anno.
[lingua del codice =”r”]
ggplot(data = ew_tweets, aes(x = year(created_at)))) +
geom_bar(aes(fill = ..count..)) +
xlab("Anno") + ylab("Numero di tweet") +
scale_x_continuous (interruzioni = c(2010:2018)) +
tema_minimo() +
scale_fill_gradient(low = “cadetblue3”, high = “chartreuse4”)
[/codice]
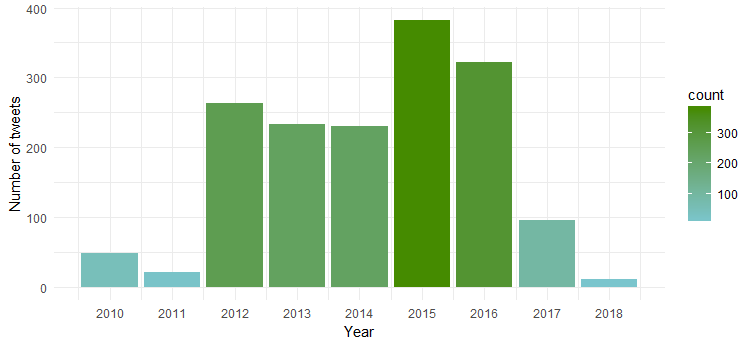
Il grafico risultante mostra che è stata più attiva nel 2015 e nel 2016, mentre il 2011 è stata meno attiva.
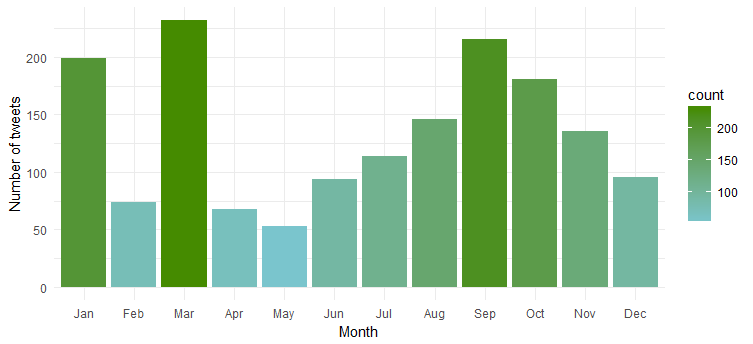
Frequenza dei tweet nel corso dei mesi
Scopriamo ora in Emma Watson Twitter Data per vedere se twitta allo stesso modo nel corso dei mesi di un anno o se ci sono mesi specifici in cui twitta di più. Utilizzare il codice seguente per creare il grafico:
[lingua del codice =”r”]
ggplot(data = ew_tweets, aes(x = month(created_at, label = TRUE))) +
geom_bar(aes(fill = ..count..)) +
xlab("Mese") + ylab("Numero di tweet") +
tema_minimo() +
scale_fill_gradient(low = “cadetblue3”, high = “chartreuse4”)
[/codice]
Chiaramente è più attiva durante "gennaio", "marzo" e "settembre".
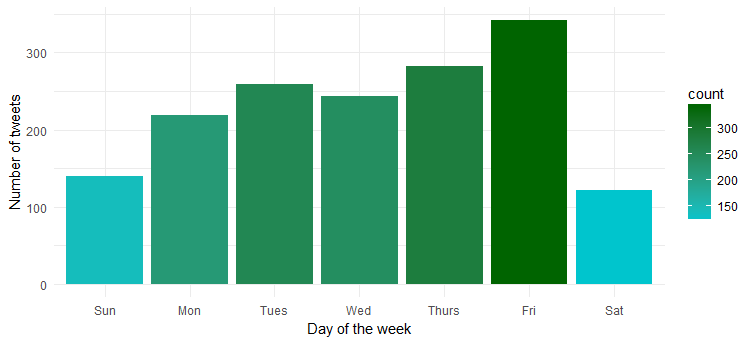
Frequenza dei tweet per una settimana
C'è un giorno specifico della settimana in cui è più attiva? Tracciamo il grafico eseguendo il codice seguente:
[lingua del codice =”r”]
ggplot(data = ew_tweets, aes(x = wday(created_at, label = TRUE))) +
geom_bar(aes(fill = ..count..)) +
xlab("Giorno della settimana") + ylab("Numero di tweet") +
tema_minimo() +
scale_fill_gradient(basso = “turchese3”, alto = “verde scuro”)
[/codice]
Hmm... è più attiva venerdì. Probabilmente ti stai preparando per entrare in modalità festa?
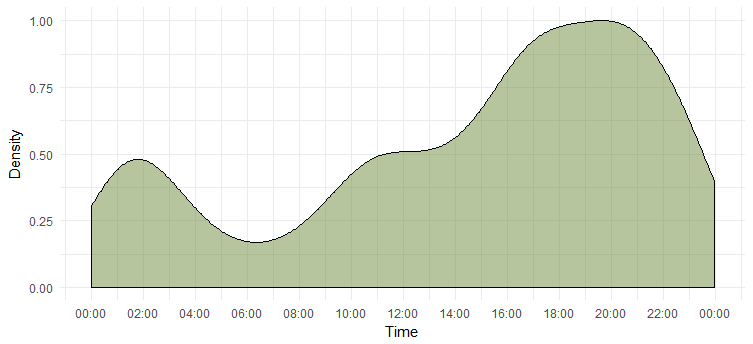
Densità di tweet per un giorno
Abbiamo individuato il giorno più attivo, ma non sappiamo a che ora sia più attiva. Il grafico seguente ci darà la risposta.
[lingua del codice =”r”]
# pacchetto per memorizzare e formattare l'ora del giorno
install.packages ("hms")
# pacchetto per aggiungere pause ed etichette
install.packages ("scale")
libreria ("hms")
libreria ("bilance")
# Estrarre solo l'ora dal timestamp, ovvero ora, minuti e secondi
ew_tweets$time <- hms::hms(second(ew_tweets$created_at),
minuto(ew_tweets$created_at),
ora(ew_tweets$created_at))
# La conversione in `POSIXct` come ggplot non è compatibile con `hms`
ew_tweets$ora <- as.POSIXct(ew_tweets$ora)
ggplot(data = ew_tweets)+
geom_density(aes(x = tempo, y = ..scalato..),
riempimento=”darkolivegreen4″, alfa=0,3) +
xlab("Tempo") + ylab("Densità") +
scale_x_datetime(breaks = date_breaks("2 ore"),
etichette = formato_data("%H:%M")) +
tema_minimo()
[/codice]

Questo ci dice che è più attiva dalle 18:00 alle 20:00 Nota che il fuso orario è UTC (può essere scoperto usando la funzione `unclass`. Tienilo a mente mentre twitti Emma.
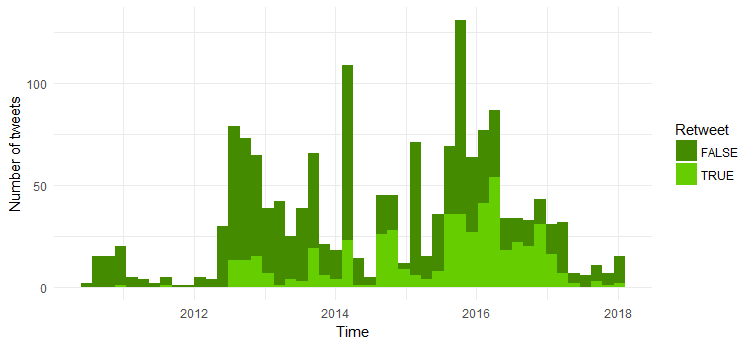
Confronto del numero di re-tweet e tweet originali
Ora confronteremo il numero di tweet originali e re-tweet. Di seguito è riportato il codice:
[lingua del codice =”r”]
ggplot(data = ew_tweets, aes(x = create_at, fill = is_retweet)) +
geom_histogram(bins=48) +
xlab("Tempo") + ylab("Numero di tweet") + theme_minimal() +
scale_fill_manual(values = c(“chartreuse4”, “chartreuse3”),
nome = "Retweet")
[/codice]
La maggior parte dei tweet sono tweet originali. Interessante vedere che il numero di retweet è aumentato rispetto al 2014.
Estrazione di testo
Entriamo ora in un'area più interessante: eseguiremo tecniche di estrazione di testo incluso NLP per scoprire quanto segue:
1. Hashtag usati di frequente
2. Nuvola di parole dei testi dei tweet
3. Analisi del sentimento
1. Hashtag usati di frequente
Il set di dati scaricato ha già una colonna contenente hashtag; lo useremo per scoprire i primi 10 hashtag usati da Emma. Di seguito è riportato il codice per creare il grafico per gli hashtag:
[lingua del codice =”r”]
# Pacchetto per lavorare facilmente con i frame di dati
install.packages ("dplyr")
libreria ("dplyr")
# Ottenere gli hashtag dall'elenco
ew_tags_split <- unlist(strsplit(as.character(unlist(ew_tweets$hashtags)),'^c(|,|”|)')))
# Formattazione rimuovendo lo spazio biancoa
ew_tags <- sapply(ew_tags_split, function(y) nchar(trimws(y)) > 0 & !is.na(y))
ew_tag_df <- as_data_frame(table(tolower(ew_tags_split[ew_tags]))))
ew_tag_df <- ew_tag_df[con(ew_tag_df,ordine(-n)),]
ew_tag_df <- ew_tag_df[1:10,]
ggplot(ew_tag_df, aes(x = riordina(Var1, -n), y=n)) +
geom_bar(stat=”identity”, fill=”darkslategray”)+
tema_minimo() +
xlab("#Hashtag") + ylab("Conteggio")
[/codice]
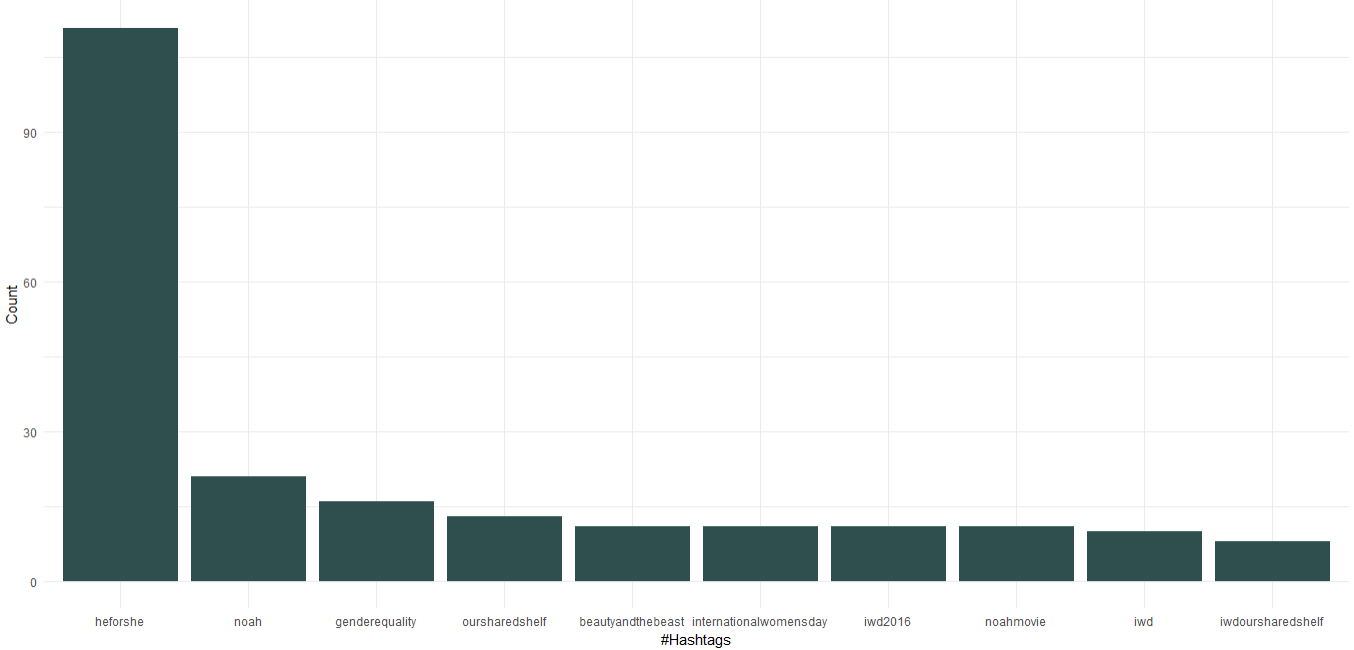
Possiamo vedere che in qualità di Ambasciatrice di buona volontà delle donne delle Nazioni Unite, Emma Watson ha promosso la campagna "HeForShe" incentrata sull'uguaglianza di genere. A parte questo ha promosso il suo club del libro chiamato “Our Shared Shelf” e “International Women's Day”. Venendo al cinema, "Noah", "La bella e la bestia" sono tra i primi 10 hashtag.
2. Nuvola di parole
Ora analizzeremo il testo del tweet per scoprire le parole più frequenti e creare una nuvola di parole. Eseguire il codice seguente per procedere:
[lingua del codice =”r”]
#installa il pacchetto di text mining e word cloud
install.packages(c(“tm”, “wordcloud”))
libreria ("tm")
libreria ("wordcloud")
tweet_text <- ew_tweets$testo
#Rimozione di numeri, punteggiatura, link e contenuti alfanumerici
tweet_text<- gsub('[[:digit:]]+', ”, tweet_text)
tweet_text<- gsub('[[:punct:]]+', ”, tweet_text)
tweet_text<- gsub(“http[[:alnum:]]*”, “”, tweet_text)
tweet_text<- gsub(“([[:alpha:]])1+”, “”, tweet_text)
#creazione di un corpus di testi
docs <- Corpus(VectorSource(tweet_text))
# convertendo la codifica in UTF-8 per gestire i personaggi divertenti
docs <- tm_map(docs, function(x) iconv(enc2utf8(x), sub = “byte”))
# Conversione del testo in minuscolo
docs <- tm_map(docs, content_transformer(tolower))
# Rimozione di stopword inglesi comuni
docs <- tm_map(docs, removeWords, stopwords("english"))
# Rimozione delle stopword specificate da noi come vettore di caratteri
docs <- tm_map(docs, removeWords, c("amp"))
# creazione di una matrice di documenti a termine
tdm <- TermDocumentMatrix(docs)
# definendo tdm come matrice
m <- come.matrice(tdm)
# ottenere il conteggio delle parole in ordine decrescente
word_freqs = sort(rowSums(m), decrescente=TRUE)
# creare un data frame con le parole e le loro frequenze
ew_wf <- data.frame(parola=nomi(freq_parola), freq=freq_parola)
# tracciando wordcloud
set.seme(1234)
wordcloud(parole = ew_wf$parola, freq = ew_wf$freq,
min.freq = 1,scala=c(1.8,.5),
max.words=200, random.order=FALSE, rot.per=0,15,
colori=brewer.pal(8, “Dark2”))
[/codice]
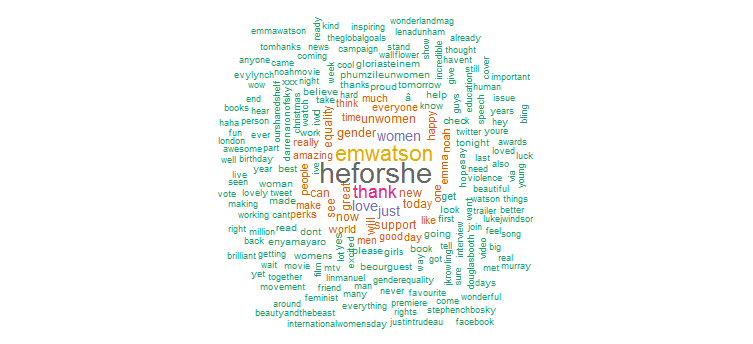
Chiaramente ha fatto una forte promozione per la campagna "HeforShe". Altre parole usate frequentemente sono “grazie”, “amore”, “donne”, “genere” e “UNWomen”. Ciò è chiaramente in linea con gli hashtag che suggeriscono che la sua attività su Twitter è piuttosto focalizzata sui problemi delle donne.
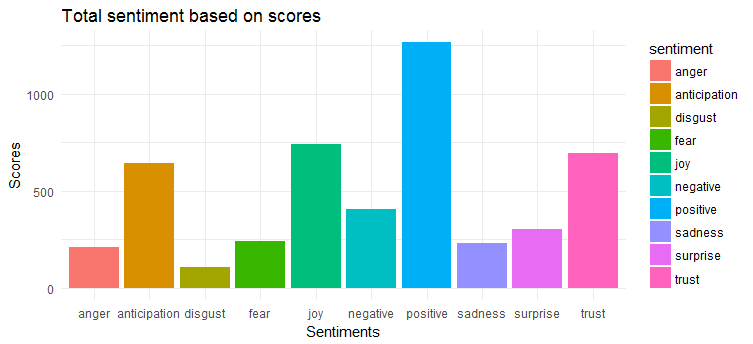
3. Analisi del sentimento
Per l'estrazione e il tracciamento del sentimento, applicheremo il pacchetto syuzhet . Questo pacchetto si basa sul lessico delle emozioni che mappa parole diverse con varie emozioni (gioia, paura, rabbia, sorpresa, ecc.) e polarità del sentimento (positivo/negativo). Dovremo calcolare il punteggio delle emozioni in base alle parole presenti nei tweet e tracciare lo stesso.
[lingua del codice =”r”]
install.packages ("syuzhet")
biblioteca (syuzhet)
# Conversione dei tweet in ASCII per tracciare strani caratteri
tweet_text <- iconv(tweet_text, from=”UTF-8″, to=”ASCII”, sub=””)
# rimozione dei retweet
tweet_text<-gsub(“(RT|via)((?:bw*@w+)+)”,””,tweet_text)
# rimozione delle menzioni
tweet_text<-gsub(“@w+”,””,tweet_text)
ew_sentiment<-get_nrc_sentiment((tweet_text))
sentimentscores<-data.frame(colSums(ew_sentiment[,]))
nomi (score dei sentimenti) <- "Punteggio"
sentimentscores <- cbind(“sentiment”=rownames(sentimentscores),sentimentscores)
rownames(sentimentscores) <- NULL
ggplot(data=sentimentscores,aes(x=sentiment,y=punteggio))+
geom_bar(aes(fill=sentimento),stat = “identità”)+
tema(legend.position="nessuno")+
xlab("Sentimenti")+ylab("Punteggi")+
ggtitle("Sentimento totale basato sui punteggi")+
tema_minimo()
[/codice]
Il grafico seguente mostra che i tweet hanno un sentimento ampiamente positivo. Le prime tre emozioni più espresse sono "gioia", "fiducia" e "attesa".
A voi
In questo studio abbiamo trattato l'analisi esplorativa dei dati e le tecniche di estrazione di testo per comprendere i modelli di tweeting e il tema alla base dei tweet pubblicati da Emma Watson. Ulteriori analisi possono essere eseguite per scoprire l'utente Twitter menzionato di frequente, creare un grafico di rete e classificare i tweet utilizzando la modellazione degli argomenti.
Segui questo tutorial e condividi i tuoi risultati nella sezione commenti.
