
Minando os Tweets de Emma Watson com R
Publicados: 2018-02-03O fluxo do Twitter de qualquer pessoa contém dados sociais ricos que podem revelar muito sobre essa pessoa. Como os dados do Twitter são públicos e a API está aberta para qualquer pessoa usar, as técnicas de mineração de dados podem ser facilmente aplicadas para descobrir tudo, desde os padrões de tempo e os tópicos em que a pessoa se concentra até os padrões de texto usados para expressar opiniões e pensamentos.

Neste estudo, usaremos o R para realizar análises sobre os tweets postados por uma das celebridades mais famosas, ou seja, Emma Watson. Primeiro, passaremos pela análise exploratória e, em seguida, passaremos para a análise de texto.
Extraindo os dados do Twitter de Emma Watson
A API do Twitter nos permite baixar 3.200 tweets recentes – tudo o que precisamos fazer é criar um aplicativo do Twitter para obter a chave da API e o token de acesso. Siga os passos abaixo para criar o aplicativo:
- Abra https://apps.twitter.com
- Clique em 'Criar novo aplicativo'
- Insira os detalhes e clique em 'Criar seu aplicativo do Twitter'
- Clique na guia 'Chaves e tokens de acesso' e copie a chave e o segredo da API
- Role para baixo e clique em “Criar meu token de acesso”
Existe uma biblioteca R chamada rtweet que será usada para baixar os tweets e criar um quadro de dados. Use o código abaixo para prosseguir:
[linguagem do código=”r”]
install.packages(“httr”)
install.packages(“rtweet”)
biblioteca(“httr”)
biblioteca(“rtweet”)
# o nome do aplicativo do twitter criado por você
appname <- “tweet-analytics”
# api key (substitua o exemplo a seguir pela sua chave)
chave <- “8YnCioFqKFaebTwjoQfcVLPS”
# api secret (substitua o seguinte pelo seu segredo)
segredo <- “uSzkAOXnNpSDsaDAaDDDSddsA6Cukfds8a3tRtSG”
# cria um token chamado “twitter_token”
twitter_token <- criar_token(
app = nomedoaplicativo,
consumidor_chave = chave,
consumidor_secret = segredo)
#Baixando os tweets postados por Emma Watson
ew_tweets <- get_timeline(“EmmaWatson”, n = 3200)
[/código]
Análise exploratória
Aqui, resumiremos o conjunto de dados visualizando o seguinte:
- Número de tweets postados de 2010 a 2018
- Frequência de tweets ao longo dos meses
- Frequência de tweets durante uma semana
- Densidade de tweets ao longo de um dia
- Comparação do número de retuítes e tweets originais
Tweets anuais
Usaremos a incrível biblioteca ggplot2 e lubridate para traçar gráficos e trabalhar com as datas. Vá em frente e siga o código abaixo para instalar e carregar os pacotes:
[linguagem do código=”r”]
install.packages(“ggplot2”)
install.packages(“lubrificar”)
biblioteca(“ggplot2”)
biblioteca(“lubrificar”)
[/código]
Execute o seguinte código para traçar a contagem de tweets ao longo dos anos, dividindo em meses:
[linguagem do código=”r”]
ggplot(dados = ew_tweets,
aes(month(created_at, label=TRUE, abbr=TRUE),
grupo=fator(ano(criado_at)), cor=fator(ano(criado_at))))+
geom_line(stat=”conta”) +
geom_point(stat=”count”) +
labs(x=”Mês”, cor=”Ano”) +
xlab(“Mês”) + ylab(“Número de tweets”) +
theme_minimal()
[/código]
O resultado é o gráfico a seguir:
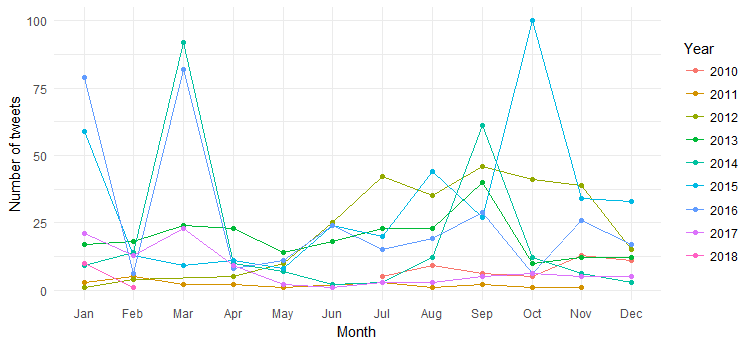
Podemos ver a separação dos tweets mensais (picos em março de 2014, março de 2016 e outubro de 2015) ao longo dos anos, mas a interpretação é difícil. Vamos agora simplificar o gráfico plotando apenas a contagem anual de tweets.
[linguagem do código=”r”]
ggplot(dados = ew_tweets, aes(x = ano(criado_at))) +
geom_bar(aes(preencher = ..contar..)) +
xlab(“Ano”) + ylab(“Número de tweets”) +
scale_x_continuous (interrupções = c(2010:2018)) +
theme_minimal() +
scale_fill_gradient(baixo = “cadetblue3”, alto = “chartreuse4”)
[/código]
O gráfico resultante mostra que ela foi mais ativa em 2015 e 2016, enquanto 2011 testemunhou menos atividade.
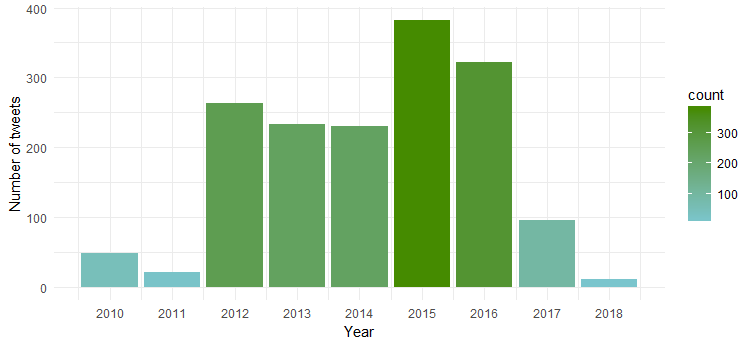
Frequência de tweets ao longo dos meses
Vamos agora descobrir em Emma Watson Twitter Data para ver se ela twitta igualmente ao longo dos meses de um ano ou há meses específicos em que ela twitta mais. Use o seguinte código para criar o gráfico:
[linguagem do código=”r”]
ggplot(data = ew_tweets, aes(x = month(created_at, label = TRUE))) +
geom_bar(aes(preencher = ..contar..)) +
xlab(“Mês”) + ylab(“Número de tweets”) +
theme_minimal() +
scale_fill_gradient(baixo = “cadetblue3”, alto = “chartreuse4”)
[/código]
Claramente ela é mais ativa durante 'janeiro', 'março' e 'setembro'.
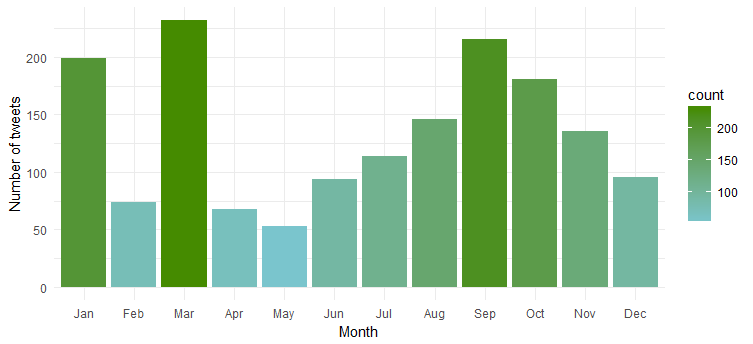
Frequência de tweets durante uma semana
Existe algum dia específico da semana em que ela é mais ativa? Vamos plotar o gráfico executando o seguinte código:
[linguagem do código=”r”]
ggplot(data = ew_tweets, aes(x = wday(created_at, label = TRUE))) +
geom_bar(aes(preencher = ..contar..)) +
xlab(“Dia da semana”) + ylab(“Número de tweets”) +
theme_minimal() +
scale_fill_gradient(baixo = “turquesa3”, alto = “verde escuro”)
[/código]
Hmm... ela é mais ativa na sexta-feira. Provavelmente se preparando para entrar no modo festa?
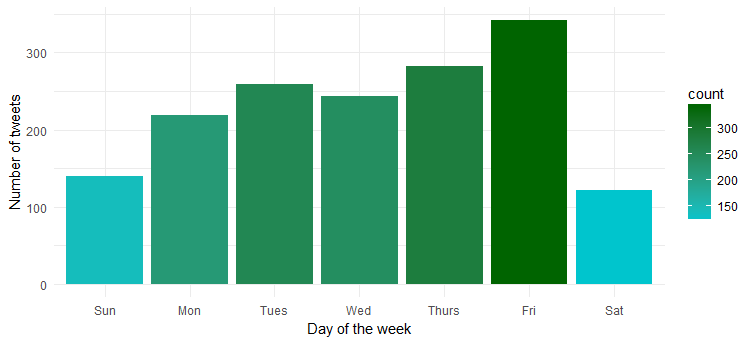
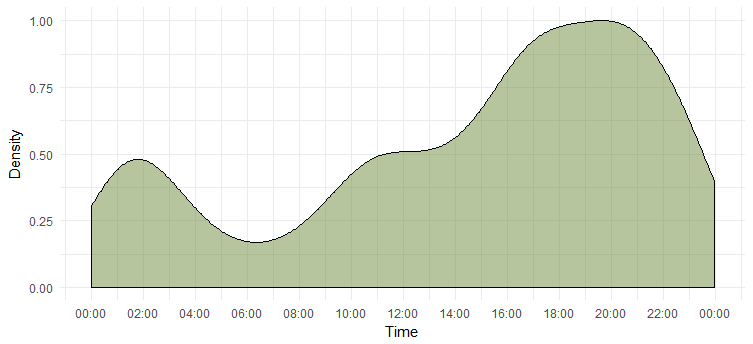
Densidade de tweets ao longo de um dia
Descobrimos o dia mais ativo, mas não sabemos a hora em que ela está mais ativa. O gráfico a seguir nos dará a resposta.
[linguagem do código=”r”]
# pacote para armazenar e formatar hora do dia
install.packages(“hms”)
# pacote para adicionar intervalos de tempo e rótulos
install.packages(“escalas”)
biblioteca(“hm”)
biblioteca(“escalas”)
# Extraia apenas a hora do timestamp, ou seja, hora, minuto e segundo
ew_tweets$time <- hms::hms(second(ew_tweets$created_at),
minuto(ew_tweets$created_at),
hora(ew_tweets$created_at))
# Convertendo para `POSIXct` como ggplot não é compatível com `hms`
ew_tweets$time <- as.POSIXct(ew_tweets$time)
ggplot(dados = ew_tweets)+
geom_density(aes(x = tempo, y = ..escalado..),
fill=”darkolivegreen4″, alfa=0,3) +
xlab(“Tempo”) + ylab(“Densidade”) +
scale_x_datetime(breaks = date_breaks(“2 horas”),
rótulos = formato_data(“%H:%M”)) +
theme_minimal()
[/código]

Isso nos diz que ela está mais ativa entre 18h e 20h. Observe que o fuso horário é UTC (pode ser encontrado usando a função `unclass`. Tenha isso em mente ao twittar Emma.
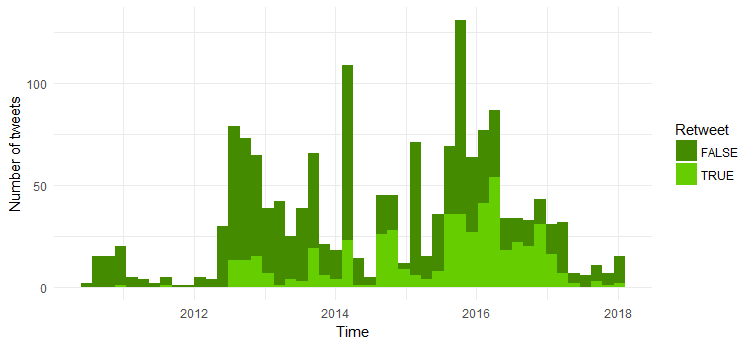
Comparação do número de retuítes e tweets originais
Agora vamos comparar o número de tweets e retuítes originais. Abaixo segue o código:
[linguagem do código=”r”]
ggplot(data = ew_tweets, aes(x = created_at, fill = is_retweet)) +
geom_histogram(bins=48) +
xlab(“Hora”) + ylab(“Número de tweets”) + theme_minimal() +
scale_fill_manual(valores = c(“chartreuse4”, “chartreuse3”),
nome = “Retweetar”)
[/código]
A maioria dos tweets são tweets originais. Interessante ver que o número de retuítes aumentou a partir de 2014.
Mineração de texto
Vamos agora entrar em uma área mais interessante - vamos realizar técnicas de mineração de texto, incluindo NLP, para descobrir o seguinte:
1. Hashtags usadas com frequência
2. Nuvem de palavras dos textos do tweet
3. Análise de sentimentos
1. Hashtags usadas com frequência
O conjunto de dados baixado já possui uma coluna contendo hashtags; usaremos isso para descobrir as 10 principais hashtags usadas por Emma. Abaixo está o código para criar o gráfico para as hashtags:
[linguagem do código=”r”]
# Pacote para trabalhar facilmente com data frames
install.packages(“dplyr”)
biblioteca(“dplyr”)
# Obtendo as hashtags da lista
ew_tags_split <- unlist(strsplit(as.character(unlist(ew_tweets$hashtags)),'^c(|,|”|)'))
# Formatação removendo o espaço em brancoa
ew_tags <- sapply(ew_tags_split, function(y) nchar(trimws(y)) > 0 & !is.na(y))
ew_tag_df <- as_data_frame(table(tolower(ew_tags_split[ew_tags]))))
ew_tag_df <- ew_tag_df[com(ew_tag_df,order(-n)),]
ew_tag_df <- ew_tag_df[1:10,]
ggplot(ew_tag_df, aes(x = reordenar(Var1, -n), y=n)) +
geom_bar(stat=”identidade”, fill=”darkslategray”)+
theme_minimal() +
xlab(“#Hashtags”) + ylab(“Contagem”)
[/código]
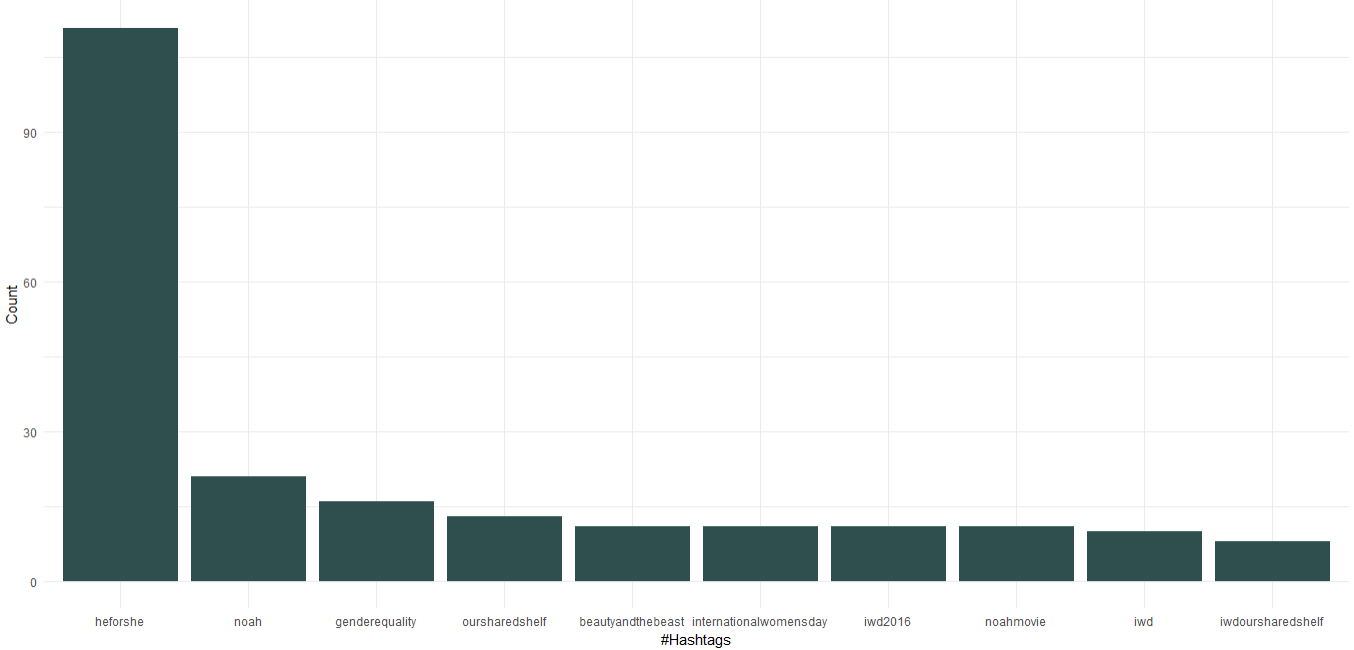
Podemos ver que, como Embaixadora da Boa Vontade da ONU Mulheres, Emma Watson promoveu a campanha “HeForShe”, focada na igualdade de gênero. Além disso, promoveu seu clube do livro chamado “Nossa Prateleira Compartilhada” e “Dia Internacional da Mulher”. Chegando ao cinema, “Noé”, “A Bela e a Fera” aparecem no top 10 das hashtags.
2. Nuvem de palavras
Agora vamos analisar o texto do tweet para descobrir as palavras mais frequentes e criar uma nuvem de palavras. Execute o seguinte código para prosseguir:
[linguagem do código=”r”]
#instale o pacote de mineração de texto e nuvem de palavras
install.packages(c(“tm”, “wordcloud”))
biblioteca(“tm”)
biblioteca(“nuvem de palavras”)
tweet_text <- ew_tweets$texto
#Remoção de números, pontuações, links e conteúdo alfanumérico
tweet_text<- gsub('[[:digit:]]+', ”, tweet_text)
tweet_text<- gsub('[[:punct:]]+', ”, tweet_text)
tweet_text<- gsub(“http[[:alnum:]]*”, “”, tweet_text)
tweet_text<- gsub(“([[:alpha:]])1+”, “”, tweet_text)
#criando um corpus de texto
docs <- Corpus(VectorSource(tweet_text))
# cobrindo a codificação para UTF-8 para lidar com caracteres engraçados
docs <- tm_map(docs, function(x) iconv(enc2utf8(x), sub = “byte”))
# Convertendo o texto para letras minúsculas
docs <- tm_map(docs, content_transformer(tolower))
# Removendo stopwords comuns em inglês
docs <- tm_map(docs, removeWords, stopwords(“português”))
# Removendo palavras irrelevantes especificadas por nós como um vetor de caracteres
docs <- tm_map(docs, removeWords, c(“amp”))
# criando matriz de documento de termo
tdm <- TermDocumentMatrix(docs)
# definindo tdm como matriz
m <- as.matriz(tdm)
# obtendo contagens de palavras em ordem decrescente
word_freqs = sort(rowSums(m), decrescente=TRUE)
# criando um data frame com palavras e suas frequências
ew_wf <- data.frame(word=names(word_freqs), freq=word_freqs)
# plotando a nuvem de palavras
set.seed(1234)
wordcloud(palavras = ew_wf$palavra, freq = ew_wf$freq,
min.freq = 1,scale=c(1,8,.5),
max.words=200, random.order=FALSE, rot.per=0,15,
cores=brewer.pal(8, “Dark2”))
[/código]
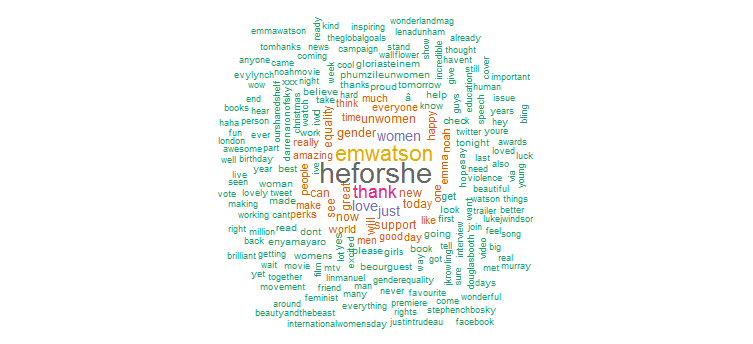
Claramente ela fez uma promoção pesada para a campanha “HeforShe”. Outras palavras frequentemente usadas são “obrigado”, “amor”, “mulheres”, “gênero” e “UNMulheres”. Isso está claramente de acordo com as hashtags que sugerem que sua atividade no Twitter é bastante focada em questões femininas.
3. Análise de sentimentos
Para extração e plotagem de sentimentos, aplicaremos o pacote syuzhet . Este pacote é baseado no léxico de emoções que mapeia diferentes palavras com várias emoções (alegria, medo, raiva, surpresa, etc.) e polaridade de sentimento (positivo/negativo). Teremos que calcular a pontuação de emoção com base nas palavras presentes nos tweets e plotar o mesmo.
[linguagem do código=”r”]
install.packages(“syuzhet”)
biblioteca (syuzhet)
# Convertendo tweets em ASCII para rastrear caracteres estranhos
tweet_text <- iconv(tweet_text, from=”UTF-8″, to=”ASCII”, sub=””)
# removendo retuítes
tweet_text<-gsub(“(RT|via)((?:bw*@w+)+)”,””,tweet_text)
# removendo menções
tweet_text<-gsub(“@w+”,””,tweet_text)
ew_sentiment<-get_nrc_sentiment((tweet_text))
sentimentscores<-data.frame(colSums(ew_sentiment[,]))
nomes(sentimentscores) <- “Pontuação”
sentimentscores <- cbind(“sentiment”=rownames(sentimentscores),sentimentscores)
rownames(sentimentscores) <- NULL
ggplot(data=sentimentscores,aes(x=sentiment,y=Score))+
geom_bar(aes(preencher=sentimento),stat = “identidade”)+
tema(legend.position=”nenhum”)+
xlab(“Sentimentos”)+ylab(“Pontuações”)+
ggtitle(“Sentimento total baseado em pontuações”)+
theme_minimal()
[/código]
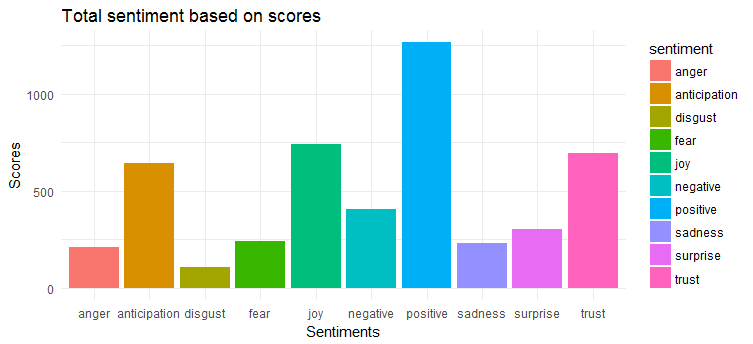
O gráfico a seguir mostra que os tweets têm um sentimento amplamente positivo. As três emoções mais expressas são 'alegria', 'confiança' e 'antecipação'.
Para você
Neste estudo, abordamos a análise exploratória de dados e técnicas de mineração de texto para entender os padrões de tweeting e o tema subjacente dos tweets postados por Emma Watson. Uma análise mais aprofundada pode ser realizada para descobrir o usuário do twitter frequentemente mencionado, criar um gráfico de rede e classificar os tweets usando modelagem de tópicos.
Siga este tutorial e compartilhe suas descobertas na seção de comentários.
