
Майнинг твитов Эммы Уотсон с помощью R
Опубликовано: 2018-02-03Поток любого человека в Твиттере содержит обширные социальные данные, которые могут многое рассказать об этом человеке. Поскольку данные Twitter являются общедоступными, а API открыт для всех, можно легко применять методы интеллектуального анализа данных, чтобы выяснить все, от временных схем и тем, на которых человек фокусируется, до текстовых паттернов, используемых для выражения взглядов и мыслей.

В этом исследовании мы будем использовать R для анализа твитов, опубликованных одной из самых известных знаменитостей, то есть Эммой Уотсон. Сначала мы проведем исследовательский анализ, а затем перейдем к текстовой аналитике.
Извлечение данных из Twitter Эммы Уотсон
Twitter API позволяет нам загружать 3200 последних твитов — все, что нам нужно сделать, это создать приложение Twitter, чтобы получить ключ API и токен доступа. Следуйте инструкциям ниже, чтобы создать приложение:
- Откройте https://apps.twitter.com
- Нажмите «Создать новое приложение».
- Введите данные и нажмите «Создать приложение Twitter».
- Перейдите на вкладку «Ключи и токены доступа» и скопируйте ключ API и секрет.
- Прокрутите вниз и нажмите «Создать мой токен доступа».
Существует библиотека R под названием rtweet , которая будет использоваться для загрузки твитов и создания фрейма данных. Используйте приведенный ниже код, чтобы продолжить:
[кодовый язык = "r"]
install.packages("httr")
install.packages («rtweet»)
библиотека («HTTR»)
библиотека («rtweet»)
# название твиттер-приложения, созданного вами
appname <- «tweet-analytics»
# ключ API (замените следующий пример своим ключом)
ключ <- «8YnCioFqKFaebTwjoQfcVLPS»
# секрет API (замените следующий секрет своим секретом)
секрет <- «uSzkAOXnNpSDsaDAaDDDSddsA6Cukfds8a3tRTSG»
# создайте токен с именем «twitter_token»
twitter_token <- create_token(
приложение = имя приложения,
потребитель_ключ = ключ,
потребитель_секрет = секрет)
#Скачивание твитов Эммы Уотсон
ew_tweets <- get_timeline («Эмма Уотсон», n = 3200)
[/код]
Исследовательский анализ
Здесь мы суммируем набор данных, визуализируя следующее:
- Количество твитов, опубликованных с 2010 по 2018 год.
- Частота твитов по месяцам
- Частота твитов в течение недели
- Плотность твитов в течение дня
- Сравнение количества ретвитов и оригинальных твитов
Годовые твиты
Мы будем использовать замечательную библиотеку ggplot2 и lubridate для построения графиков и работы с датами. Идите вперед и следуйте приведенному ниже коду, чтобы установить и загрузить пакеты:
[кодовый язык = "r"]
установить.пакеты («ggplot2»)
install.packages («смазать»)
библиотека («ggplot2»)
библиотека («смазка»)
[/код]
Выполните следующий код, чтобы отобразить количество твитов за годы, разбив их на месяцы:
[кодовый язык = "r"]
ggplot (данные = ew_tweets,
aes (месяц (созданный_в, метка = ИСТИНА, сокращение = ИСТИНА),
группа = фактор (год (созданный_в)), цвет = фактор (год (созданный_в ))))+
geom_line (статистика = «количество») +
geom_point(stat=”количество”) +
labs(x="Месяц", color="Год") +
xlab("Месяц") + ylab("Количество твитов") +
тема_минимальный()
[/код]
В результате получается следующая диаграмма:
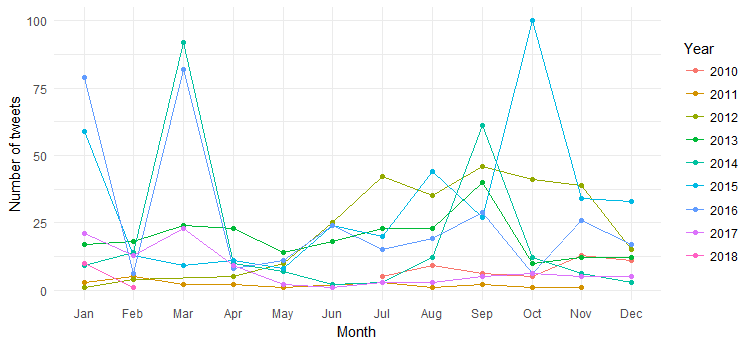
Мы можем видеть разбивку твитов по месяцам (всплески в марте 2014 г., марте 2016 г. и октябре 2015 г.) по годам, но их интерпретация затруднена. Теперь давайте упростим диаграмму, нанеся количество твитов только за год.
[кодовый язык = "r"]
ggplot(data = ew_tweets, aes(x = year(created_at))) +
geom_bar(aes(fill = ..count..)) +
xlab("Год") + ylab("Количество твитов") +
scale_x_continuous (перерывы = c(2010:2018)) +
тема_минимальный() +
scale_fill_gradient (низкий = «кадетский синий3», высокий = «шартрез4»)
[/код]
Полученная диаграмма показывает, что она была наиболее активной в 2015 и 2016 годах, а в 2011 году активность была наименьшей.
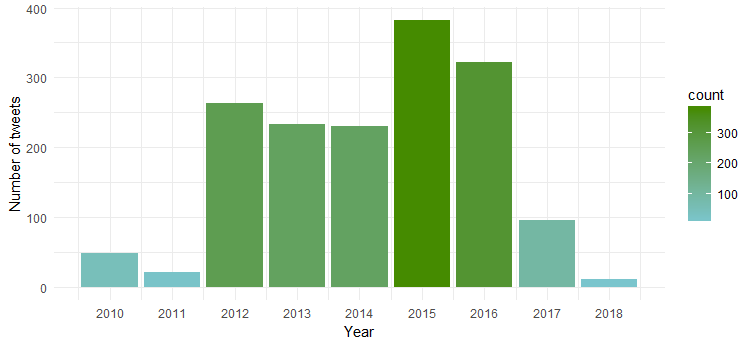
Частота твитов по месяцам
Давайте теперь выясним в данных Twitter Эммы Уотсон, чтобы увидеть, одинаково ли она твитит в течение месяцев года или есть какие-то определенные месяцы, в которые она пишет больше всего. Используйте следующий код для создания диаграммы:
[кодовый язык = "r"]
ggplot (данные = ew_tweets, aes (x = месяц (созданный_в, метка = TRUE))) +
geom_bar(aes(fill = ..count..)) +
xlab("Месяц") + ylab("Количество твитов") +
тема_минимальный() +
scale_fill_gradient (низкий = «кадетский синий3», высокий = «шартрез4»)
[/код]
Ясно, что она наиболее активна в «январе», «марте» и «сентябре».
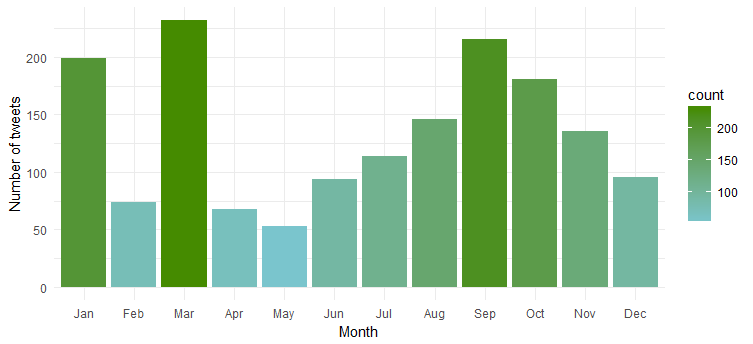
Частота твитов в течение недели
Есть ли какой-то конкретный день недели, когда она наиболее активна? Давайте построим диаграмму, выполнив следующий код:
[кодовый язык = "r"]
ggplot(data = ew_tweets, aes(x = wday(created_at, label = TRUE))) +
geom_bar(aes(fill = ..count..)) +
xlab("День недели") + ylab("Количество твитов") +
тема_минимальный() +
scale_fill_gradient (низкий = «бирюзовый3», высокий = «темно-зеленый»)
[/код]
Хм… она наиболее активна в пятницу. Вероятно, готовится перейти в режим вечеринки?
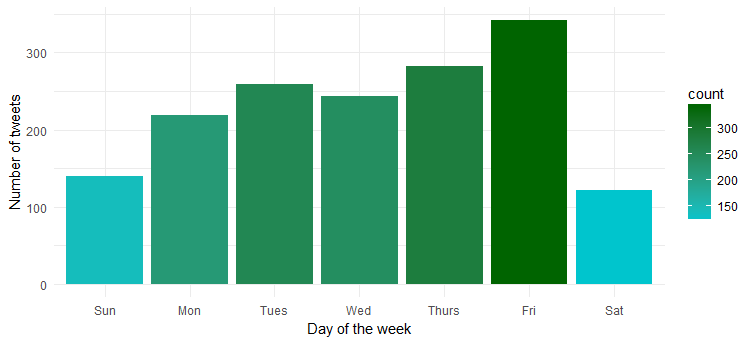
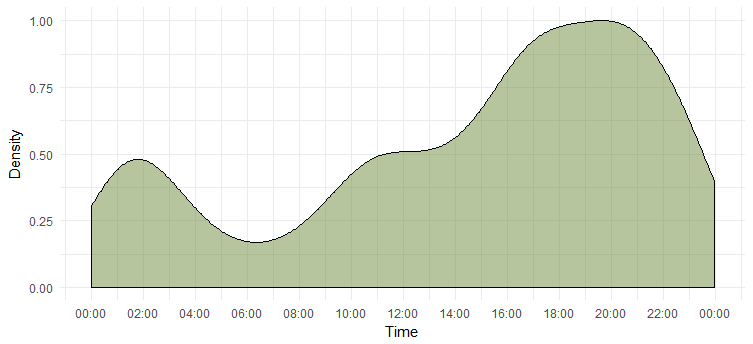
Плотность твитов в течение дня
Мы вычислили самый активный день, но не знаем, в какое время она наиболее активна. Следующая таблица даст нам ответ.
[кодовый язык = "r"]
# пакет для хранения и форматирования времени суток
установить.пакеты («хмс»)
# пакет для добавления временных пауз и меток
install.packages («весы»)
библиотека («хмс»)
библиотека («весы»)
# Извлечь из временной метки только время, т.е. часы, минуты и секунды
ew_tweets$time <- hms::hms(second(ew_tweets$created_at),
минута(ew_tweets$created_at),
час(ew_tweets$created_at))
# Преобразование в `POSIXct`, поскольку ggplot несовместимо с `hms`
ew_tweets$time <- as.POSIXct(ew_tweets$time)
ggplot(данные = ew_tweets)+
geom_density (aes (x = время, y = .. в масштабе ..),
fill=”darkolivegreen4″, альфа=0,3) +
xlab("Время") + ylab("Плотность") +
scale_x_datetime (перерывы = date_breaks («2 часа»),
метки = формат_даты («%H:%M»)) +
тема_минимальный()
[/код]

Это говорит нам о том, что она наиболее активна в 6-8 часов вечера. Обратите внимание, что часовой пояс — UTC (можно узнать с помощью функции «unclass». Имейте это в виду, когда пишете Эмме в Твиттере.
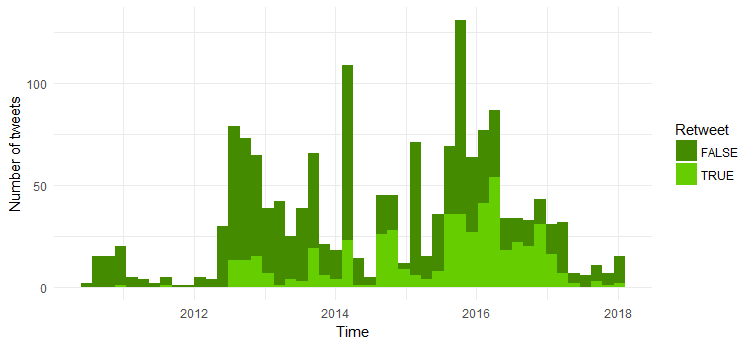
Сравнение количества ретвитов и оригинальных твитов
Теперь сравним количество оригинальных твитов и ретвитов. Ниже приведен код:
[кодовый язык = "r"]
ggplot (данные = ew_tweets, aes (x = created_at, fill = is_retweet)) +
geom_histogram (ячейки = 48) +
xlab("Время") + ylab("Количество твитов") + theme_minimal() +
scale_fill_manual (значения = c («шартрез4», «шартрез3»),
имя = «Ретвитнуть»)
[/код]
Большинство твитов являются оригинальными твитами. Интересно видеть, что количество ретвитов увеличилось с 2014 года.
Интеллектуальный анализ текста
Давайте теперь перейдем к более интересной области — мы будем использовать методы анализа текста, включая НЛП, чтобы выяснить следующее:
1. Часто используемые хэштеги
2. Облако слов из текстов твитов
3. Анализ настроений
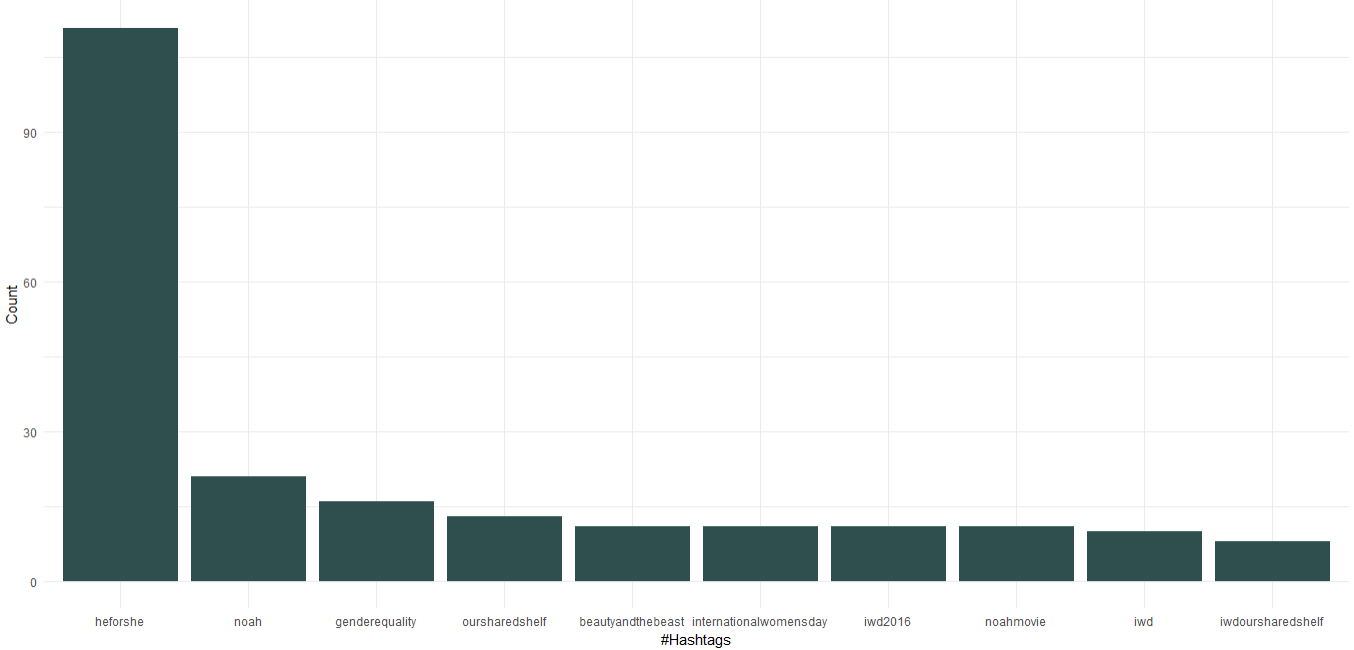
1. Часто используемые хэштеги
В загруженном наборе данных уже есть столбец с хэштегами; мы будем использовать это, чтобы узнать 10 лучших хэштегов, используемых Эммой. Ниже приведен код для создания диаграммы для хэштегов:
[кодовый язык = "r"]
# Пакет для удобной работы с фреймами данных
install.packages("dplyr")
библиотека («dplyr»)
# Получение хэштегов из списка
ew_tags_split <- unlist(strsplit(as.character(unlist(ew_tweets$hashtags)),'^c(|,|"|)'))
# Форматирование удалением пробела
ew_tags <- sapply(ew_tags_split, function(y) nchar(trimws(y)) > 0 & !is.na(y))
ew_tag_df <- as_data_frame(table(tolower(ew_tags_split[ew_tags])))
ew_tag_df <- ew_tag_df[с(ew_tag_df,порядок(-n)),]
ew_tag_df <- ew_tag_df[1:10,]
ggplot(ew_tag_df, aes(x = изменить порядок(Var1, -n), y=n)) +
geom_bar(stat=”identity”, fill=”darkslategray”)+
тема_минимальный() +
xlab("#Хэштеги") + ylab("Количество")
[/код]
Мы видим, что в качестве посла доброй воли «ООН-женщины» Эмма Уотсон продвигала кампанию «HeForShe», направленную на гендерное равенство. Кроме того, она продвигала свой книжный клуб под названием «Наша общая полка» и «Международный женский день». Что касается фильмов, то «Ной», «Красавица и чудовище» попали в топ-10 хэштегов.
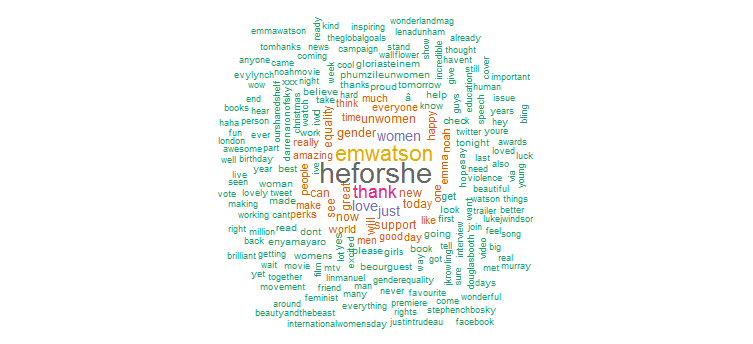
2. Облако слов
Теперь проанализируем текст твита, чтобы найти наиболее часто встречающиеся слова и создадим облако слов. Выполните следующий код, чтобы продолжить:
[кодовый язык = "r"]
#установить пакет интеллектуального анализа текста и облака слов
install.packages(c("tm", "wordcloud"))
библиотека («тм»)
библиотека («облако слов»)
твит_текст <- ew_tweets$текст
#Удаление цифр, знаков препинания, ссылок и буквенно-цифрового содержимого
tweet_text<- gsub('[[:digit:]]+', ", tweet_text)
tweet_text<- gsub('[[:punct:]]+', ", tweet_text)
tweet_text<- gsub("http[[:alnum:]]*", "", tweet_text)
tweet_text<- gsub("([[:alpha:]])1+", "", tweet_text)
#создание корпуса текстов
документы <- Корпус (VectorSource (tweet_text))
# замена кодировки на UTF-8 для обработки забавных символов
документы <- tm_map (документы, функция (x) iconv (enc2utf8 (x), sub = «byte»))
# Преобразование текста в нижний регистр
документы <- tm_map (документы, content_transformer (tolower))
# Удаление английских стоп-слов
docs <- tm_map(docs, removeWords, стоп-слова("английский"))
# Удаление стоп-слов, указанных нами как вектор символов
docs <- tm_map(docs, removeWords, c("amp"))
# создание матрицы документа термина
tdm <- TermDocumentMatrix(docs)
# определение tdm как матрицы
m <- as.matrix(tdm)
# получение количества слов в порядке убывания
word_freqs = сортировка (суммы строк (м), уменьшение = ИСТИНА)
# создание фрейма данных со словами и их частотностью
ew_wf <- data.frame(word=names(word_freqs), freq=word_freqs)
# построение облака слов
set.seed(1234)
облако слов (слова = ew_wf$word, частота = ew_wf$freq,
мин.частота = 1, шкала = с (1,8, 5),
max.words=200, random.order=FALSE, rot.per=0,15,
colors=brewer.pal(8, «Dark2»))
[/код]
Очевидно, она активно продвигала кампанию «HeforShe». Другими часто используемыми словами являются «спасибо», «любовь», «женщины», «гендер» и «ООН-женщины». Это явно соответствует хэштегам, которые предполагают, что ее деятельность в Твиттере в значительной степени сосредоточена на женских проблемах.
3. Анализ настроений
Для извлечения настроений и построения графиков применим пакет syuzhet . Этот пакет основан на словаре эмоций, который сопоставляет разные слова с различными эмоциями (радость, страх, гнев, удивление и т. д.) и полярностью настроения (положительное/отрицательное). Нам нужно будет рассчитать оценку эмоций на основе слов, присутствующих в твитах, и построить то же самое.
[кодовый язык = "r"]
install.packages("сюжет")
библиотека(сюжет)
# Преобразование твитов в ASCII для отслеживания странных символов
tweet_text <- iconv(tweet_text, from="UTF-8", to="ASCII", sub="")
# удаление ретвитов
tweet_text<-gsub("(RT|через)((?:bw*@w+)+)",",",tweet_text)
# удаление упоминаний
tweet_text<-gsub(“@w+”,”,”,tweet_text)
ew_sentiment<-get_nrc_sentiment((tweet_text))
оценки настроений <-data.frame(colSums(ew_sentiment[,]))
имена (оценка настроений) <- «Оценка»
оценки настроений <- cbind («настроения» = имена строк (оценки настроений), оценки настроений)
имена строк (показатели настроений) <- NULL
ggplot (данные = оценки настроений, aes (x = настроения, y = оценка)) +
geom_bar (aes (fill = настроение), stat = «личность») +
тема(легенда.позиция=”нет”)+
xlab("Настроения")+ylab("Оценки")+
ggtitle("Общее мнение на основе оценок")+
тема_минимальный()
[/код]
Следующая диаграмма показывает, что твиты имеют в основном положительные настроения. В первую тройку наиболее выраженных эмоций входят «радость», «доверие» и «ожидание».
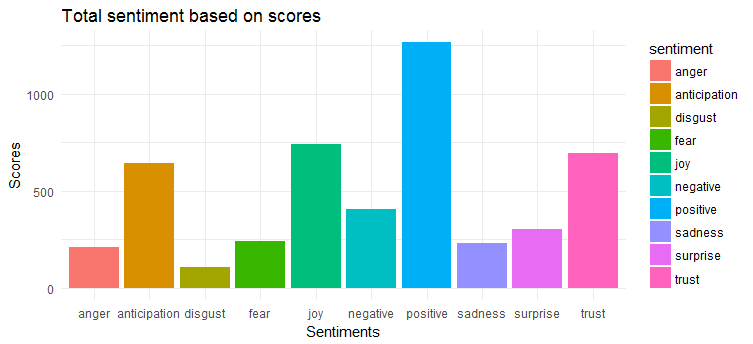
к вам
В этом исследовании мы рассмотрели исследовательский анализ данных и методы анализа текста, чтобы понять шаблоны твитов и основную тему твитов, опубликованных Эммой Уотсон. Можно выполнить дальнейший анализ, чтобы найти часто упоминаемого пользователя твиттера, создать сетевой график и классифицировать твиты с помощью тематического моделирования.
Следуйте этому руководству и поделитесь своими выводами в разделе комментариев.
