
Wydobywanie tweetów Emmy Watson z R
Opublikowany: 2018-02-03Strumień Twittera dowolnej osoby zawiera bogate dane społecznościowe, które mogą wiele ujawnić o tej osobie. Ponieważ dane z Twittera są publiczne, a interfejs API jest otwarty dla każdego, techniki eksploracji danych można łatwo zastosować, aby dowiedzieć się wszystkiego, od wzorców czasowych i tematów, na których dana osoba się koncentruje, po wzorce tekstowe używane do wyrażania poglądów i myśli.

W tym badaniu użyjemy R do analizy tweetów opublikowanych przez jedną z najbardziej znanych celebrytek, tj. Emmę Watson. Najpierw przejdziemy przez analizę eksploracyjną, a następnie przejdziemy do analizy tekstu.
Pobieranie danych z Twittera Emmy Watson
Twitter API pozwala nam pobrać 3200 ostatnich tweetów — wystarczy, że stworzymy aplikację Twitter, aby uzyskać klucz API i token dostępu. Wykonaj poniższe czynności, aby utworzyć aplikację:
- Otwórz https://apps.twitter.com
- Kliknij „Utwórz nową aplikację”
- Wprowadź szczegóły i kliknij „Utwórz aplikację na Twittera”
- Kliknij na zakładkę „Klucze i Tokeny Dostępu” i skopiuj klucz API oraz sekret
- Przewiń w dół i kliknij „Utwórz mój token dostępu”
Istnieje biblioteka R o nazwie rtweet , która będzie używana do pobierania tweetów i tworzenia ramki danych. Użyj poniższego kodu, aby kontynuować:
[język kodu=”r”]
install.packages("httr")
install.packages("rtweet")
biblioteka("httr")
biblioteka(„rtweet”)
# nazwa aplikacji Twitter stworzonej przez Ciebie
nazwa aplikacji <- „Analiza tweetów”
# klucz api (zastąp poniższy przykład swoim kluczem)
klawisz <- „8YnCioFqKFaebTwjoQfcVLPS”
# api secret (zastąp poniższe swoim sekretem)
sekret <- “uSzkaAOXnNpSDsaDAaDDDSddsA6Cukfds8a3tRtSG”
# utwórz token o nazwie „twitter_token”
twitter_token <- utwórz_token(
aplikacja = nazwa aplikacji,
klucz_konsumenta = klucz,
Consumer_secret = sekret)
#Pobieranie tweetów opublikowanych przez Emmę Watson
ew_tweets <- get_timeline(„EmmaWatson”, n = 3200)
[/kod]
Analiza eksploracyjna
Tutaj podsumujemy zestaw danych, wizualizując następujące elementy:
- Liczba tweetów opublikowanych od 2010 do 2018
- Częstotliwość tweetów na przestrzeni miesięcy
- Częstotliwość tweetów przez tydzień
- Gęstość tweetów w ciągu dnia
- Porównanie liczby ponownych tweetów i oryginalnych tweetów
Roczne tweety
Będziemy używać niesamowitej biblioteki ggplot2 i lubridate do tworzenia wykresów i pracy z datami. Śmiało i postępuj zgodnie z kodem podanym poniżej, aby zainstalować i załadować pakiety:
[język kodu=”r”]
install.packages(“ggplot2”)
install.packages("smaruj")
biblioteka("ggplot2")
biblioteka („smaruj”)
[/kod]
Wykonaj następujący kod, aby wykreślić liczbę tweetów na przestrzeni lat z podziałem na miesiące:
[język kodu=”r”]
ggplot(dane = ew_tweety,
aes(miesiąc(utworzony_at, etykieta=PRAWDA, skrót=PRAWDA),
group=czynnik(rok(utworzono_w)), kolor=czynnik(rok(utworzono_w))))+
geom_line(stat=”liczba”) +
geom_point(stat=”liczba”) +
labs(x=”Miesiąc”, kolor=”Rok”) +
xlab("Miesiąc") + ylab("Liczba tweetów") +
theme_minimal()
[/kod]
Rezultatem jest następujący wykres:
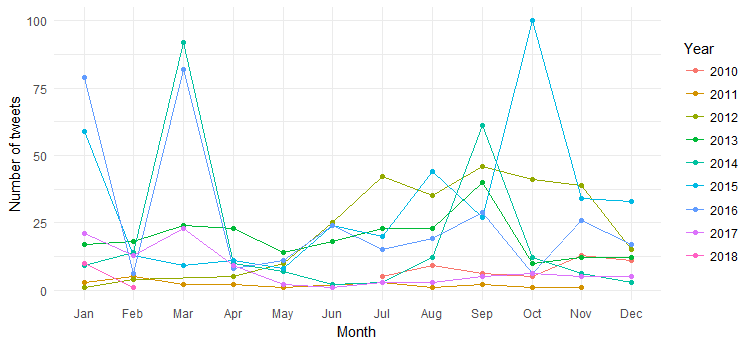
Widzimy rozpad tweetów miesięcznych (wzrosty w marcu 2014, marcu 2016 i październiku 2015) na przestrzeni lat, ale interpretacja jest trudna. Uprośćmy teraz wykres, wykreślając tylko roczne liczby tweetów.
[język kodu=”r”]
ggplot(dane = ew_tweety, aes(x = rok(utworzony_at))) +
geom_bar(aes(fill = ..count..)) +
xlab("Rok") + ylab("Liczba tweetów") +
scale_x_continuous (przerwy = c(2010:2018)) +
theme_minimal() +
scale_fill_gradient(low = „cadetblue3”, high = „chartreuse4”)
[/kod]
Wynikowy wykres pokazuje, że była najbardziej aktywna w 2015 i 2016 roku, podczas gdy 2011 był świadkiem najmniejszej aktywności.
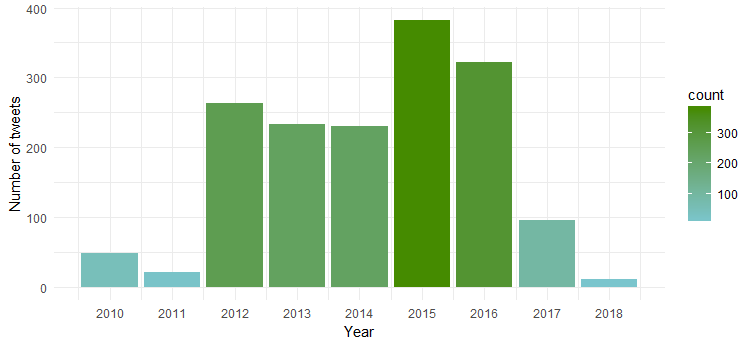
Częstotliwość tweetów na przestrzeni miesięcy
Sprawdźmy teraz w Danych na Twitterze Emma Watson, aby zobaczyć, czy tweetuje równo w ciągu miesięcy w roku, czy są jakieś konkretne miesiące, w których tweetuje najczęściej. Użyj następującego kodu, aby utworzyć wykres:
[język kodu=”r”]
ggplot(dane = ew_tweets, aes(x = miesiąc(utworzony_at, etykieta = PRAWDA))) +
geom_bar(aes(fill = ..count..)) +
xlab("Miesiąc") + ylab("Liczba tweetów") +
theme_minimal() +
scale_fill_gradient(low = „cadetblue3”, high = „chartreuse4”)
[/kod]
Najwyraźniej jest najbardziej aktywna w okresie „styczeń”, „marzec” i „wrzesień”.
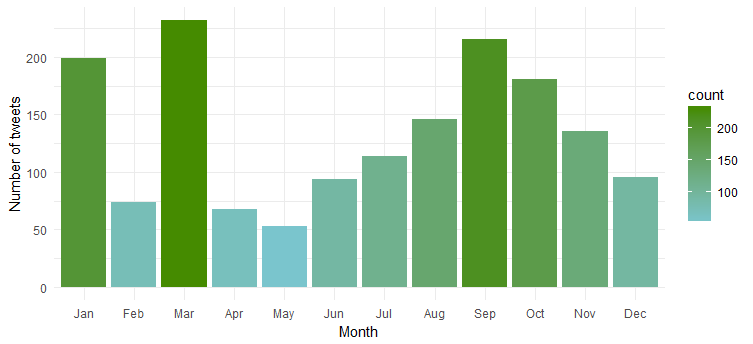
Częstotliwość tweetów przez tydzień
Czy jest jakiś konkretny dzień tygodnia, w którym jest najbardziej aktywna? Narysujmy wykres, wykonując następujący kod:
[język kodu=”r”]
ggplot(data = ew_tweets, aes(x = wday(created_at, label = TRUE))) +
geom_bar(aes(fill = ..count..)) +
xlab(„Dzień tygodnia”) + ylab(„Liczba tweetów”) +
theme_minimal() +
scale_fill_gradient(low = „turkusowy3”, wysoki = „ciemnozielony”)
[/kod]
Hmm… najbardziej aktywna jest w piątek. Prawdopodobnie przygotowujesz się do wejścia w tryb imprezy?
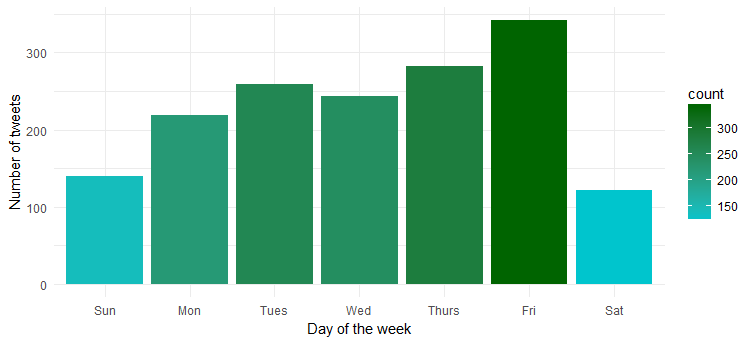
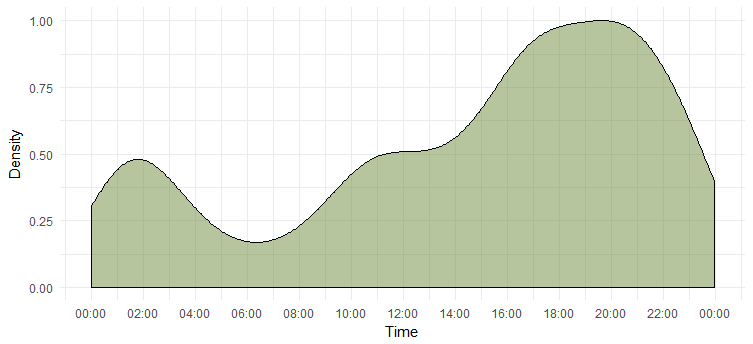
Gęstość tweetów w ciągu dnia
Ustaliliśmy najbardziej aktywny dzień, ale nie znamy godziny, w której jest najbardziej aktywna. Poniższy wykres da nam odpowiedź.
[język kodu=”r”]
# pakiet do przechowywania i formatowania pory dnia
install.packages("hms")
# pakiet do dodawania przerw i etykiet
install.packages("waga")
biblioteka(„hms”)
biblioteka("wagi")
# Wyodrębnij tylko czas ze znacznika czasu, tj. godzinę, minutę i sekundę
ew_tweets$time <- hms::hms(second(ew_tweets$created_at),
minuta(ew_tweets$created_at),
godzina(ew_tweets$created_at))
# Konwersja do `POSIXct` jako ggplot nie jest kompatybilna z `hms`
ew_tweets$time <- as.POSIXct(ew_tweets$time)
ggplot(dane = ew_tweety)+
geom_density(aes(x = czas, y = ..skalowane..),
fill=”darkolivegreen4″, alfa=0.3) +
xlab("Czas") + ylab("Gęstość") +
scale_x_datetime(przerwy = date_breaks("2 godziny"),
etykiety = format_daty(„%H:%M”)) +
theme_minimal()
[/kod]

To mówi nam, że jest najbardziej aktywna w godzinach 18-20. Zauważ, że strefa czasowa to UTC (można to sprawdzić za pomocą funkcji `unclass`. Miej to na uwadze podczas tweetowania z Emmą).
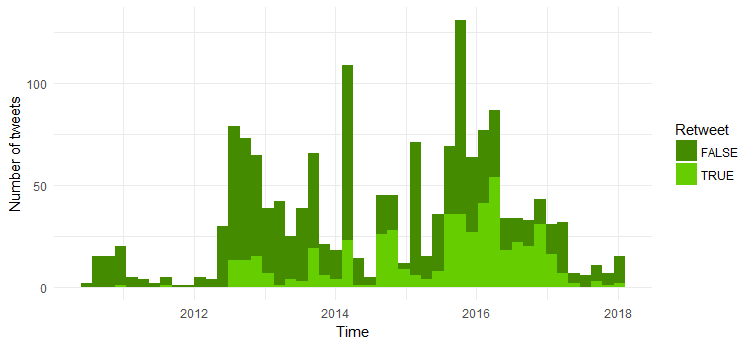
Porównanie liczby ponownych tweetów i oryginalnych tweetów
Teraz porównamy liczbę oryginalnych tweetów i ponownych tweetów. Poniżej podano kod:
[język kodu=”r”]
ggplot(data = ew_tweets, aes(x = created_at, fill = is_retweet)) +
geom_histogram(bins=48) +
xlab(„Czas”) + ylab(„Liczba tweetów”) + theme_minimal() +
scale_fill_manual(wartości = c(„wykres4”, „wykres3”),
nazwa = „Prześlij dalej”)
[/kod]
Większość tweetów to tweety oryginalne. Ciekawe, że liczba ponownych tweetów wzrosła od 2014 roku.
Eksploracja tekstu
Przejdźmy teraz do bardziej interesującego obszaru — wykonamy techniki eksploracji tekstu, w tym NLP, aby dowiedzieć się, co następuje:
1. Często używane hashtagi
2. Chmura słów tekstów tweet
3. Analiza sentymentu
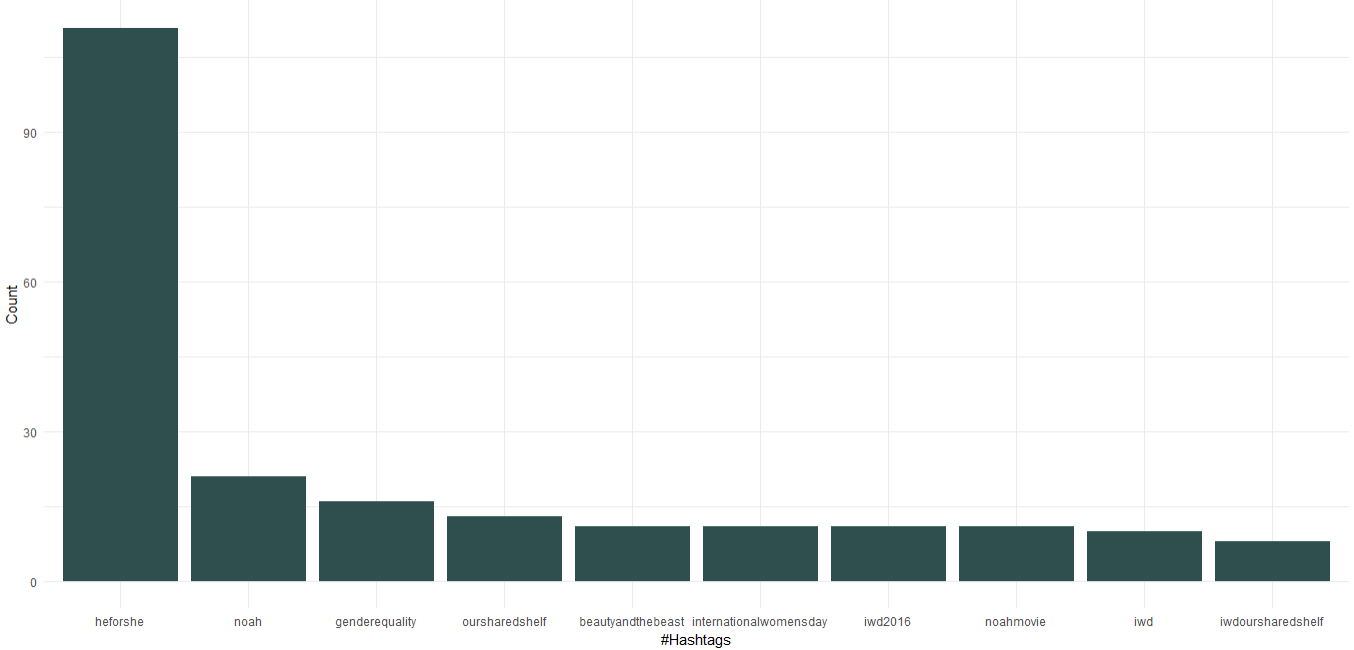
1. Często używane hashtagi
Pobrany zbiór danych zawiera już kolumnę zawierającą hashtagi; użyjemy tego, aby znaleźć 10 najpopularniejszych hashtagów używanych przez Emmę. Poniżej podano kod do stworzenia wykresu dla hashtagów:
[język kodu=”r”]
# Pakiet do łatwej pracy z ramkami danych
install.packages("dplyr")
biblioteka("dplyr")
# Pobieranie hashtagów z listy
ew_tags_split <- unlist(strsplit(as.character(unlist(ew_tweets$hashtags)),'^c(|,|”|)'))
# Formatowanie poprzez usunięcie spacjia
ew_tags <- sapply(ew_tags_split, function(y) nchar(trimws(y)) > 0 & !is.na(y))
ew_tag_df <- as_data_frame(table(tolower(ew_tags_split[ew_tags])))
ew_tag_df <- ew_tag_df[with(ew_tag_df,order(-n)),]
ew_tag_df <- ew_tag_df[1:10,]
ggplot(ew_tag_df, aes(x = reorder(Var1, -n), y=n)) +
geom_bar(stat=”identity”, fill=”darkslategray”)+
theme_minimal() +
xlab("#Hashtagi") + ylab("Liczba")
[/kod]
Widzimy, że jako Ambasador Dobrej Woli ONZ, Emma Watson promowała kampanię „HeForShe”, która skupia się na równości płci. Poza tym promowała swój klub książki „Nasza wspólna półka” i „Międzynarodowy Dzień Kobiet”. Wracając do filmów, „Noah”, „Piękna i Bestia” pojawiają się w 10 najlepszych hashtagach.
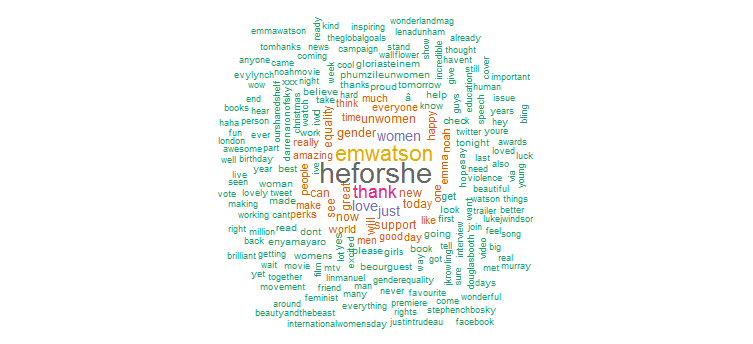
2. Chmura słowa
Teraz przeanalizujemy tekst tweeta, aby znaleźć najczęściej używane słowa i utworzyć chmurę słów. Wykonaj następujący kod, aby kontynuować:
[język kodu=”r”]
#zainstaluj pakiet eksploracji tekstu i chmury słów
install.packages(c("tm", "wordcloud"))
biblioteka(„tm”)
biblioteka(„chmura słów”)
tweet_text <- ew_tweets$text
#Usuwanie cyfr, znaków interpunkcyjnych, linków i treści alfanumerycznych
tweet_text<- gsub('[[:cyfra:]]+', ”, tweet_text)
tweet_text<- gsub('[[:punct:]]+', ”, tweet_text)
tweet_text<- gsub(„http[[:alnum:]]*”, „”, tweet_text)
tweet_text<- gsub(„([[:alpha:]])1+”, „”, tweet_text)
#tworzenie korpusu tekstowego
docs <- Corpus(VectorSource(tweet_text))
# ukrywanie kodowania do UTF-8 w celu obsługi zabawnych znaków
docs <- tm_map(docs, function(x) iconv(enc2utf8(x), sub = “bajt”))
# Konwersja tekstu na małe litery
docs <- tm_map(docs, content_transformer(tolower))
# Usuwanie popularnych angielskich odrzuconych słów
docs <- tm_map(docs, removeWords, stopwords(„angielski”))
# Usuwanie odrzucanych słów określonych przez nas jako wektor znaków
docs <- tm_map(docs, removeWords, c(„amp”))
# tworzenie matrycy dokumentów terminów
tdm <- TermDocumentMatrix (dokumenty)
# zdefiniowanie tdm jako macierz
m <- as.macierz(tdm)
# pobieranie liczby słów w kolejności malejącej
word_freqs = sort(rowSums(m), malejący=TRUE)
# tworzenie ramki danych ze słowami i ich częstotliwościami
ew_wf <- data.frame(word=names(word_freqs), freq=word_freqs)
# kreślenie wordcloud
zestaw.nasion(1234)
wordcloud(słowa = ew_wf$słowo, częst = ew_wf$częst.,
min.freq = 1,skala=c(1.8,.5),
max.words=200, random.order=FALSE, rot.per=0.15,
kolory=brewer.pal(8, „Ciemny2”))
[/kod]
Najwyraźniej mocno promowała kampanię „HeforShe”. Inne często używane słowa to „dziękuję”, „miłość”, „kobiety”, „płeć” i „UNWomen”. Jest to wyraźnie zgodne z hashtagami, które sugerują, że jej aktywność na Twitterze jest dość skoncentrowana na sprawach kobiet.
3. Analiza sentymentu
Do ekstrakcji sentymentów i kreślenia użyjemy pakietu syuzhet . Pakiet ten opiera się na leksykonie emocji, który odwzorowuje różne słowa z różnymi emocjami (radość, strach, złość, zaskoczenie itp.) oraz polaryzacją sentymentu (pozytywne/negatywne). Będziemy musieli obliczyć wynik emocji na podstawie słów obecnych w tweetach i wykreślić to samo.
[język kodu=”r”]
install.packages("syuzhet")
biblioteka (syużet)
# Konwertowanie tweetów do ASCII w celu śledzenia dziwnych postaci
tweet_text <- iconv(tweet_text, from=”UTF-8”, to=”ASCII”, sub=””)
# usuwanie retweetów
tweet_text<-gsub(“(RT|przez)((?:bw*@w+)+)”,””,tweet_text)
# usuwanie wzmianek
tweet_text<-gsub(„@w+”,””,tweet_text)
ew_sentiment<-get_nrc_sentiment((tweet_text))
sentymenty<-data.frame(colSums(ew_sentiment[,]))
nazwy (sentimentscores) <- „Score”
wyniki nastrojów <- cbind("nastroje"=nazwy wierszy(wyceny nastrojów), wyniki nastrojów)
rownames(sentimentscores) <- NULL
ggplot(data=sentimentscores,aes(x=sentiment,y=Score))+
geom_bar(aes(fill=sentiment),stat = “tożsamość”)+
theme(legend.position=”brak”)+
xlab("Sentymenty")+ylab("Wyniki")+
ggtitle("Całkowity sentyment oparty na wynikach")+
theme_minimal()
[/kod]
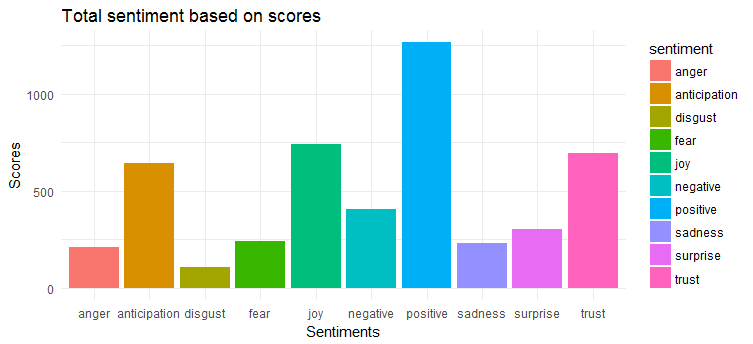
Poniższy wykres pokazuje, że tweety mają w dużej mierze pozytywny sentyment. Trzy najczęściej wyrażane emocje to „radość”, „zaufanie” i „oczekiwanie”.
Do Ciebie
W tym badaniu omówiliśmy eksploracyjną analizę danych i techniki eksploracji tekstu, aby zrozumieć wzorce tweetów i motyw przewodni tweetów opublikowanych przez Emmę Watson. Można przeprowadzić dalszą analizę, aby znaleźć często wspominanego użytkownika Twittera, stworzyć wykres sieci i sklasyfikować tweety za pomocą modelowania tematów.
Śledź ten samouczek i podziel się swoimi odkryciami w sekcji komentarzy.
