
Das Mining von Emma Watsons Tweets mit R
Veröffentlicht: 2018-02-03Der Twitter-Stream einer Person enthält umfangreiche soziale Daten, die viel über diese Person enthüllen können. Da Twitter-Daten öffentlich und die API für jedermann zugänglich ist, können Data-Mining-Techniken einfach angewendet werden, um alles herauszufinden, von den Zeitmustern und den Themen, auf die sich die Person konzentriert, bis zu den Textmustern, die verwendet werden, um Ansichten und Gedanken auszudrücken.

In dieser Studie verwenden wir R , um Analysen der Tweets durchzuführen, die von einer der berühmtesten Prominenten, nämlich Emma Watson, gepostet wurden. Zuerst gehen wir die explorative Analyse durch und gehen dann zur Textanalyse über.
Extrahieren von Emma Watsons Twitter-Daten
Die Twitter-API ermöglicht es uns, 3.200 aktuelle Tweets herunterzuladen – alles, was wir tun müssen, ist eine Twitter-App zu erstellen, um den API-Schlüssel und das Zugriffstoken zu erhalten. Führen Sie die folgenden Schritte aus, um die App zu erstellen:
- Öffnen Sie https://apps.twitter.com
- Klicken Sie auf „Neue App erstellen“.
- Geben Sie die Details ein und klicken Sie auf „Erstellen Sie Ihre Twitter-Anwendung“.
- Klicken Sie auf die Registerkarte „Schlüssel und Zugriffstoken“ und kopieren Sie den API-Schlüssel und das Geheimnis
- Scrollen Sie nach unten und klicken Sie auf „Create my access token“
Es gibt eine R -Bibliothek namens rtweet , die verwendet wird, um die Tweets herunterzuladen und einen Datenrahmen zu erstellen. Verwenden Sie den unten angegebenen Code, um fortzufahren:
[code language="r"]
install.packages("httr")
install.packages(“rtweet”)
Bibliothek ("httr")
Bibliothek ("rtweet")
# der Name der von Ihnen erstellten Twitter-App
Appname <- „tweet-analytics“
# API-Schlüssel (ersetzen Sie das folgende Beispiel durch Ihren Schlüssel)
Schlüssel <- „8YnCioFqKFaebTwjoQfcVLPS“
# API-Geheimnis (ersetzen Sie Folgendes durch Ihr Geheimnis)
Geheimnis <- „uSzkaOXnNpSDsaDAaDDDSddsA6Cukfds8a3tRtSG“
# Token namens „twitter_token“ erstellen
twitter_token <- create_token(
app = Appname,
Consumer_key = Schlüssel,
Consumer_secret = Geheimnis)
#Herunterladen der von Emma Watson geposteten Tweets
ew_tweets <- get_timeline(“EmmaWatson”, n = 3200)
[/Code]
Explorative Analyse
Hier fassen wir den Datensatz zusammen, indem wir Folgendes visualisieren:
- Anzahl der geposteten Tweets von 2010 bis 2018
- Tweethäufigkeit über die Monate
- Tweet-Frequenz über eine Woche
- Tweetdichte über einen Tag
- Vergleich der Anzahl von Re-Tweets und Original-Tweets
Jahresbezogene Tweets
Wir werden die erstaunliche Bibliothek ggplot2 und lubridate verwenden, um Diagramme zu zeichnen und mit den Daten zu arbeiten. Fahren Sie fort und folgen Sie dem unten angegebenen Code, um die Pakete zu installieren und zu laden:
[code language="r"]
install.packages(“ggplot2”)
install.packages ("schmieren")
Bibliothek ("ggplot2")
Bibliothek ("schmieren")
[/Code]
Führen Sie den folgenden Code aus, um die Anzahl der Tweets über die Jahre darzustellen, indem Sie sie in Monate aufschlüsseln:
[code language="r"]
ggplot(data = ew_tweets,
aes(Monat(erstellt_um, Label=TRUE, abbr=TRUE),
Gruppe=Faktor(Jahr(erstellt_um)), Farbe=Faktor(Jahr(erstellt_um))))+
geom_line(stat="count") +
geom_point(stat="count") +
labs(x=”Monat”, color=”Jahr”) +
xlab("Monat") + ylab("Anzahl der Tweets") +
theme_minimal()
[/Code]
Das Ergebnis ist folgendes Diagramm:
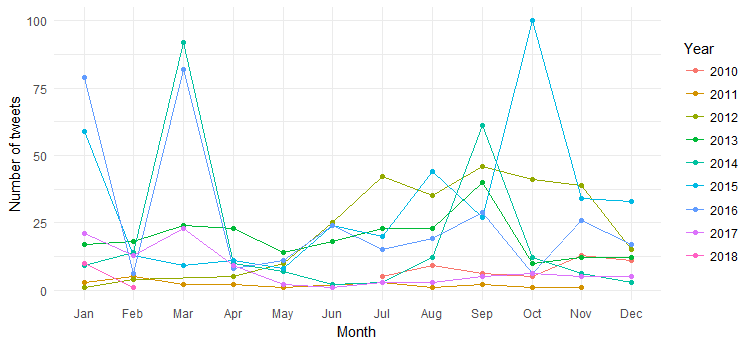
Wir können die Aufteilung der monatlichen Tweets (Spitzen im März 2014, März 2016 und Oktober 2015) im Laufe der Jahre sehen, aber die Interpretation ist schwierig. Vereinfachen wir nun das Diagramm, indem wir nur die Anzahl der Tweets im Jahresverlauf darstellen.
[code language="r"]
ggplot(data = ew_tweets, aes(x = year(created_at))) +
geom_bar(aes(fill = ..count..)) +
xlab("Jahr") + ylab("Anzahl der Tweets") +
scale_x_continuous (Brüche = c(2010:2018)) +
theme_minimal() +
scale_fill_gradient(low = „cadetblue3“, high = „chartreuse4“)
[/Code]
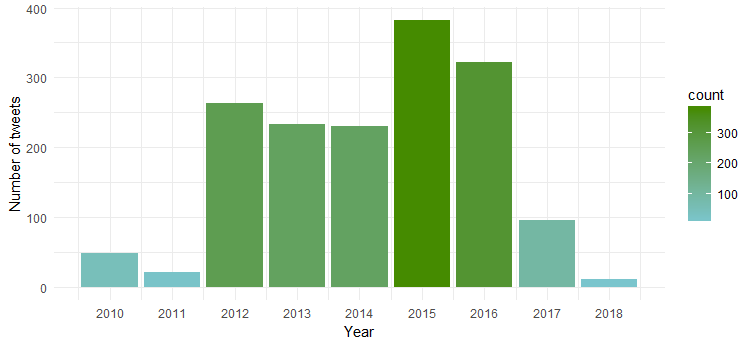
Das resultierende Diagramm zeigt, dass sie 2015 und 2016 am aktivsten war, während 2011 die geringste Aktivität zu verzeichnen war.
Tweethäufigkeit über die Monate
Lassen Sie uns nun in den Twitter-Daten von Emma Watson herausfinden, ob sie über die Monate eines Jahres gleichmäßig twittert oder ob es bestimmte Monate gibt, in denen sie am meisten twittert. Verwenden Sie den folgenden Code, um das Diagramm zu erstellen:
[code language="r"]
ggplot(data = ew_tweets, aes(x = month(created_at, label = TRUE))) +
geom_bar(aes(fill = ..count..)) +
xlab("Monat") + ylab("Anzahl der Tweets") +
theme_minimal() +
scale_fill_gradient(low = „cadetblue3“, high = „chartreuse4“)
[/Code]
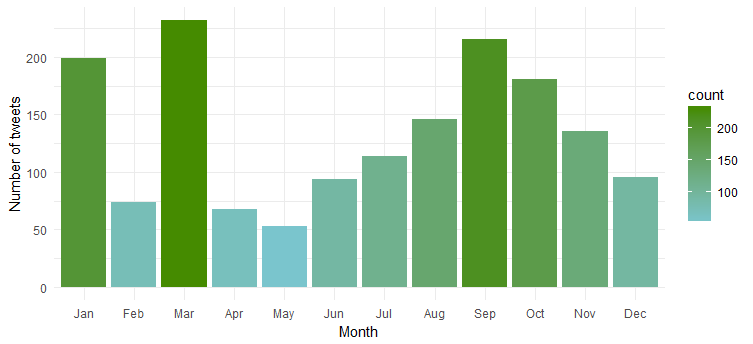
Am aktivsten ist sie natürlich im „Januar“, „März“ und „September“.
Tweet-Frequenz über eine Woche
Gibt es einen bestimmten Wochentag, an dem sie am aktivsten ist? Lassen Sie uns das Diagramm zeichnen, indem Sie den folgenden Code ausführen:
[code language="r"]
ggplot(data = ew_tweets, aes(x = wday(created_at, label = TRUE))) +
geom_bar(aes(fill = ..count..)) +
xlab("Wochentag") + ylab("Anzahl der Tweets") +
theme_minimal() +
scale_fill_gradient(niedrig = „türkis3“, hoch = „dunkelgrün“)
[/Code]
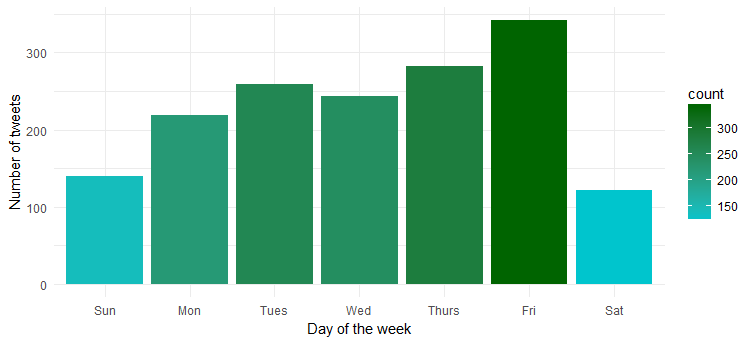
Hmm… am Freitag ist sie am aktivsten. Bereiten Sie sich wahrscheinlich darauf vor, in den Partymodus zu wechseln?
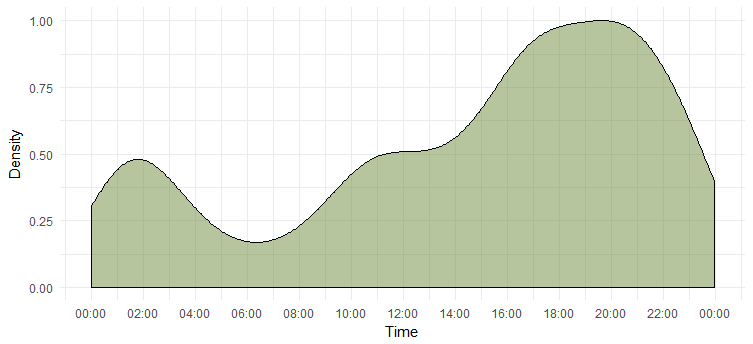
Tweetdichte über einen Tag
Wir haben den aktivsten Tag herausgefunden, aber wir wissen nicht, zu welcher Zeit sie am aktivsten ist. Die folgende Tabelle gibt uns die Antwort.
[code language="r"]
# Paket zum Speichern und Formatieren der Tageszeit
install.packages(“hms”)
# Paket zum Hinzufügen von Zeitunterbrechungen und Beschriftungen
install.packages("scales")
Bibliothek („hms“)
Bibliothek ("Skalen")
# Aus dem Zeitstempel nur die Zeit extrahieren, dh Stunde, Minute und Sekunde
ew_tweets$time <- hms::hms(second(ew_tweets$created_at),
minute(ew_tweets$created_at),
Stunde (ew_tweets$created_at))
# Konvertieren in `POSIXct`, da ggplot nicht mit `hms` kompatibel ist
ew_tweets$time <- as.POSIXct(ew_tweets$time)
ggplot(data = ew_tweets)+
geom_density(aes(x = time, y = ..scaled..),
fill=”darkolivegreen4″, alpha=0.3) +
xlab("Zeit") + ylab("Dichte") +
scale_x_datetime(pausen = date_breaks(“2 Stunden”),
Etiketten = Datumsformat(“%H:%M”)) +
theme_minimal()
[/Code]

Dies sagt uns, dass sie zwischen 18 und 20 Uhr am aktivsten ist. Beachten Sie, dass die Zeitzone UTC ist (kann mit der Funktion „unclass“ herausgefunden werden. Denken Sie daran, wenn Sie Emma twittern.
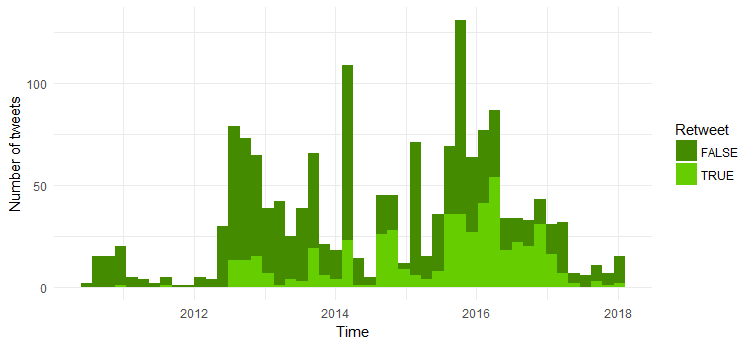
Vergleich der Anzahl von Re-Tweets und Original-Tweets
Jetzt vergleichen wir die Anzahl der Original-Tweets und Re-Tweets. Da unten ist der Code:
[code language="r"]
ggplot(data = ew_tweets, aes(x = created_at, fill = is_retweet)) +
geom_histogram(bins=48) +
xlab("Zeit") + ylab("Anzahl der Tweets") + theme_minimal() +
scale_fill_manual(values = c("chartreuse4", "chartreuse3"),
Name = „Retweet“)
[/Code]
Die Mehrzahl der Tweets sind Original-Tweets. Interessant zu sehen, dass die Zahl der Retweets seit 2014 zugenommen hat.
Text-Mining
Kommen wir nun zu einem interessanteren Bereich – wir führen Text-Mining-Techniken einschließlich NLP durch, um Folgendes herauszufinden:
1. Häufig verwendete Hashtags
2. Wortwolke der Tweet-Texte
3. Stimmungsanalyse
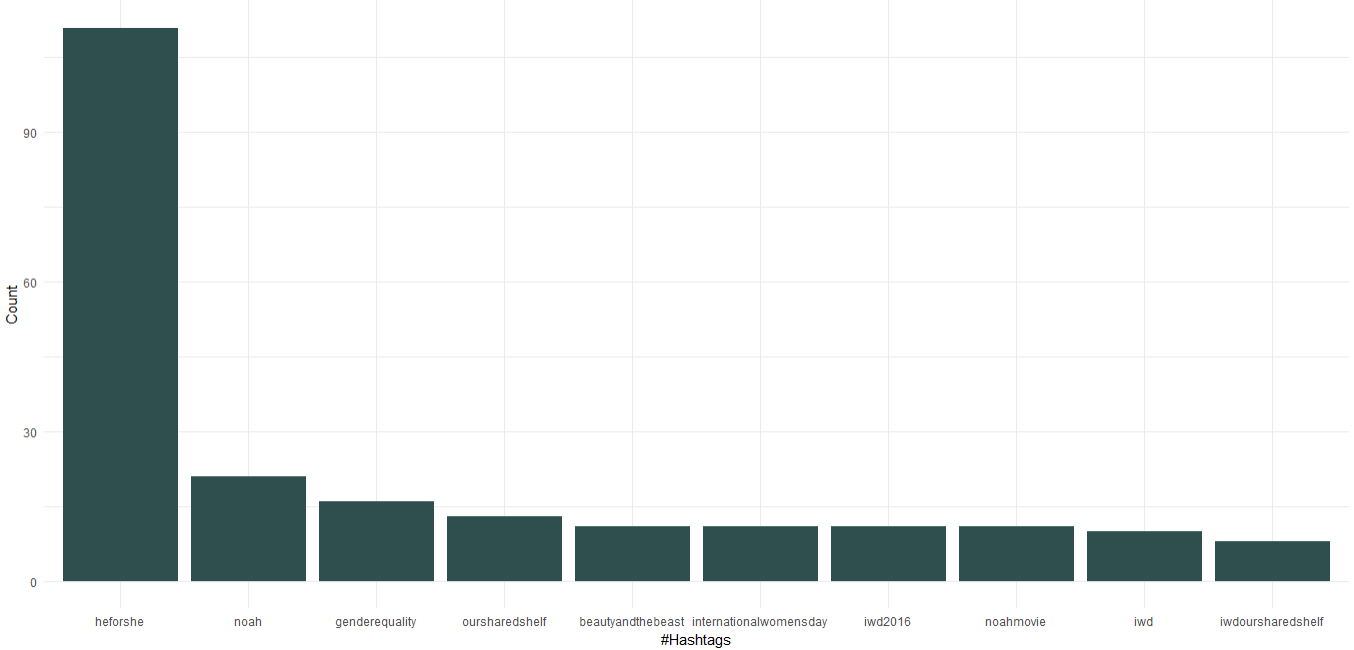
1. Häufig verwendete Hashtags
Das heruntergeladene Dataset hat bereits eine Spalte mit Hashtags; Wir werden das verwenden, um die Top 10 der von Emma verwendeten Hashtags herauszufinden. Unten ist der Code zum Erstellen des Diagramms für die Hashtags:
[code language="r"]
# Paket zum einfachen Arbeiten mit Datenrahmen
install.packages („dplyr“)
Bibliothek ("dplyr")
# Abrufen der Hashtags aus der Liste
ew_tags_split <- unlist(strsplit(as.character(unlist(ew_tweets$hashtags)),'^c(|,|“|)'))
# Formatierung durch Entfernen des Leerzeichensa
ew_tags <- sapply(ew_tags_split, function(y) nchar(trimws(y)) > 0 & !is.na(y))
ew_tag_df <- as_data_frame(table(tolower(ew_tags_split[ew_tags])))
ew_tag_df <- ew_tag_df[with(ew_tag_df,order(-n)),]
ew_tag_df <- ew_tag_df[1:10,]
ggplot(ew_tag_df, aes(x = reorder(Var1, -n), y=n)) +
geom_bar(stat=“identity“, fill=“darkslategray“)+
theme_minimal() +
xlab("#Hashtags") + ylab("Anzahl")
[/Code]
Wir können sehen, dass Emma Watson als UN-Sonderbotschafterin für Frauen die „HeForShe“-Kampagne gefördert hat, die sich auf die Gleichstellung der Geschlechter konzentriert. Abgesehen davon hat sie für ihren Buchclub namens „Our Shared Shelf“ und den „International Women's Day“ geworben. Zu den Filmen gehören „Noah“, „Die Schöne und das Biest“ in den Top 10 der Hashtags.
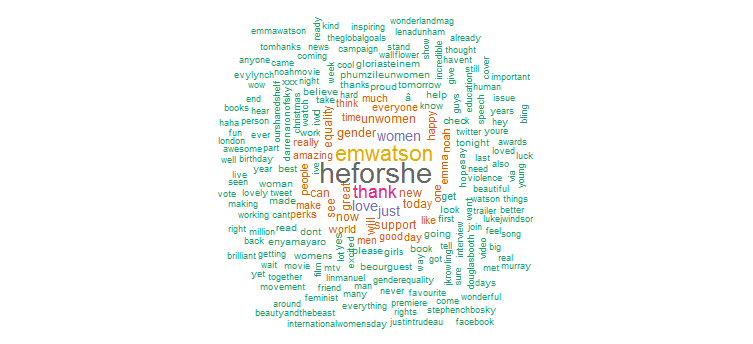
2. Wortwolke
Jetzt analysieren wir den Tweet-Text, um die häufigsten Wörter herauszufinden, und erstellen eine Wortwolke. Führen Sie den folgenden Code aus, um fortzufahren:
[code language="r"]
#Installieren Sie das Text-Mining- und Word-Cloud-Paket
install.packages(c("tm", "wordcloud"))
Bibliothek ("tm")
Bibliothek ("Wortwolke")
tweet_text <- ew_tweets$text
#Entfernen von Zahlen, Satzzeichen, Links und alphanumerischen Inhalten
tweet_text<- gsub('[[:ziffer:]]+', ”, tweet_text)
tweet_text<- gsub('[[:punct:]]+', ”, tweet_text)
tweet_text<- gsub("http[[:alnum:]]*", "", tweet_text)
tweet_text<- gsub(“([[:alpha:]])1+”, „”, tweet_text)
#Erstellen eines Textkorpus
docs <- Corpus(VectorSource(tweet_text))
# Umwandeln der Codierung in UTF-8, um mit komischen Zeichen umzugehen
docs <- tm_map(docs, function(x) iconv(enc2utf8(x), sub = „byte“))
# Umwandlung des Textes in Kleinbuchstaben
docs <- tm_map(docs, content_transformer(tolower))
# Entfernen allgemeiner englischer Stoppwörter
docs <- tm_map(docs, removeWords, stopwords(“english”))
# Entfernen von Stoppwörtern, die von uns als Zeichenvektor angegeben wurden
docs <- tm_map(docs, removeWords, c(“amp”))
# Begriffsdokumentmatrix erstellen
tdm <- TermDocumentMatrix(docs)
# tdm als Matrix definieren
m <- as.Matrix(tdm)
# Abrufen der Wortanzahl in absteigender Reihenfolge
word_freqs = sort(rowSums(m), absteigend=TRUE)
# Erstellen eines Datenrahmens mit Wörtern und ihren Häufigkeiten
ew_wf <- data.frame (word=names(word_freqs), freq=word_freqs)
# Wortwolke plotten
set.seed(1234)
wordcloud(words = ew_wf$word, freq = ew_wf$freq,
min.freq = 1, Skala = c (1,8, 0,5),
max.words=200, random.order=FALSE, rot.per=0.15,
colors=brewer.pal(8, „Dark2“))
[/Code]
Sie hat eindeutig viel Werbung für die „HeforShe“-Kampagne gemacht. Andere häufig verwendete Wörter sind „thank“, „love“, „women“, „gender“ und „UNWomen“. Dies steht eindeutig im Einklang mit den Hashtags, die darauf hindeuten, dass sich ihre Twitter-Aktivität ziemlich auf Frauenthemen konzentriert.
3. Stimmungsanalyse
Für die Sentimentextraktion und das Plotten wenden wir das syuzhet -Paket an. Dieses Paket basiert auf einem Emotionslexikon, das verschiedene Wörter mit verschiedenen Emotionen (Freude, Angst, Wut, Überraschung usw.) und Stimmungspolarität (positiv/negativ) abbildet. Wir müssen den Emotions-Score basierend auf den in den Tweets enthaltenen Wörtern berechnen und dasselbe plotten.
[code language="r"]
install.packages(“syuzhet”)
Bibliothek (syzhet)
# Konvertieren von Tweets in ASCII, um seltsame Zeichen zu verfolgen
tweet_text <- iconv(tweet_text, from=“UTF-8″, to=“ASCII“, sub=““)
# Retweets entfernen
tweet_text<-gsub(“(RT|via)((?:bw*@w+)+)”,””,tweet_text)
# Erwähnungen entfernen
tweet_text<-gsub(“@w+”,””,tweet_text)
ew_sentiment<-get_nrc_sentiment((tweet_text))
sentimentscores<-data.frame(colSums(ew_sentiment[,]))
Namen (Sentimentscores) <- „Score“
Sentimentscores <- cbind(“sentiment”=rownames(sentimentscores),sentimentscores)
rownames(sentimentscores) <- NULL
ggplot(data=Stimmungsergebnisse,aes(x=Stimmung,y=Punktzahl))+
geom_bar(aes(fill=sentiment),stat = „identity“)+
theme(legend.position="none")+
xlab(„Stimmungen“)+ylab(„Ergebnisse“)+
ggtitle("Gesamtstimmung basierend auf Bewertungen")+
theme_minimal()
[/Code]
Das folgende Diagramm zeigt, dass Tweets eine weitgehend positive Stimmung haben. Die drei am häufigsten ausgedrückten Emotionen sind „Freude“, „Vertrauen“ und „Vorfreude“.
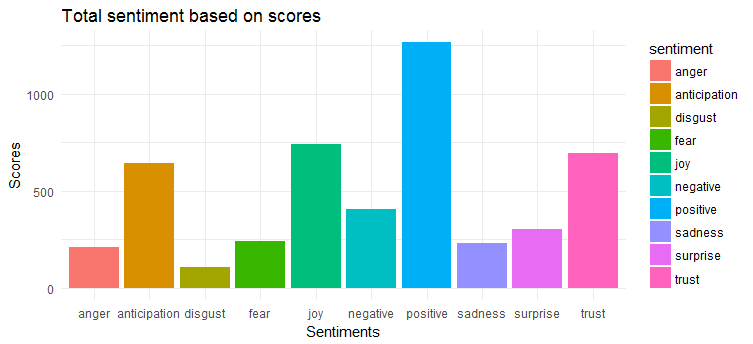
Zu dir hinüber
In dieser Studie haben wir explorative Datenanalyse- und Text-Mining-Techniken behandelt, um die Tweetmuster und das zugrunde liegende Thema der von Emma Watson geposteten Tweets zu verstehen. Weitere Analysen können durchgeführt werden, um den häufig genannten Twitter-Nutzer herauszufinden, Netzwerkdiagramme zu erstellen und die Tweets mithilfe von Themenmodellierung zu klassifizieren.
Folgen Sie diesem Tutorial und teilen Sie Ihre Erkenntnisse im Kommentarbereich.
