
R로 Emma Watson의 트윗 마이닝
게시 됨: 2018-02-03어떤 사람의 트위터 스트림에는 그 사람에 대해 많은 것을 밝힐 수 있는 풍부한 소셜 데이터가 포함되어 있습니다. Twitter 데이터는 공개되어 있고 API는 누구나 사용할 수 있도록 열려 있기 때문에 데이터 마이닝 기술을 쉽게 적용하여 타이밍 패턴과 사용자가 중점을 두는 주제부터 관점과 생각을 표현하는 데 사용되는 텍스트 패턴까지 모든 것을 찾을 수 있습니다.

이 연구에서는 R 을 사용하여 가장 유명한 유명인 중 한 명인 Emma Watson이 게시한 트윗을 분석합니다. 먼저 탐색적 분석을 거친 다음 텍스트 분석으로 이동합니다.
엠마 왓슨의 트위터 데이터 추출
Twitter API를 사용하면 3,200개의 최근 트윗을 다운로드할 수 있습니다. API 키와 액세스 토큰을 얻기 위해 Twitter 앱을 만들기만 하면 됩니다. 앱을 만들려면 다음 단계를 따르세요.
- https://apps.twitter.com을 엽니다.
- '새 앱 만들기'를 클릭합니다.
- 세부 정보를 입력하고 '트위터 애플리케이션 만들기'를 클릭합니다.
- '키 및 액세스 토큰' 탭을 클릭하고 API 키 및 암호를 복사합니다.
- 아래로 스크롤하여 "내 액세스 토큰 만들기"를 클릭하십시오.
트윗을 다운로드하고 데이터 프레임을 만드는 데 사용되는 rtweet 이라는 R 라이브러리가 있습니다. 계속 진행하려면 아래에 제공된 코드를 사용하십시오.
[코드 언어 = "r"]
install.packages("httr")
install.packages("rtweet")
라이브러리("httr")
라이브러리("트윗")
# 당신이 만든 트위터 앱의 이름
앱 이름 <- "트윗 분석"
# api 키(다음 샘플을 키로 대체)
키 <- "8YnCioFqKFaebTwjoQfcVLPS"
# api 비밀(다음을 비밀로 대체)
비밀 <- "uSzkAOXnNpSDsaDAaDDDSddsA6Cukfds8a3tRtSG"
# "twitter_token"이라는 토큰을 생성합니다.
twitter_token <- create_token(
앱 = 앱 이름,
소비자 키 = 키,
Consumer_secret = 비밀)
#엠마 왓슨이 올린 트윗 다운로드
ew_tweets <- get_timeline(“엠마왓슨”, n = 3200)
[/암호]
탐색적 분석
여기에서 다음을 시각화하여 데이터 세트를 요약합니다.
- 2010년부터 2018년까지 게시된 트윗 수
- 몇 달 동안 트윗 빈도
- 일주일 동안 트윗 빈도
- 하루 동안의 트윗 밀도
- 리트윗 수와 원본 트윗 수 비교
연도별 트윗
우리는 놀라운 ggplot2 및 lubridate 라이브러리를 사용하여 차트를 작성하고 날짜로 작업할 것입니다. 계속해서 아래에 제공된 코드에 따라 패키지를 설치하고 로드하십시오.
[코드 언어 = "r"]
install.packages("ggplot2")
install.packages("윤활")
라이브러리("ggplot2")
라이브러리("윤활")
[/암호]
다음 코드를 실행하여 몇 년 동안의 트윗 수를 월로 나누어 플롯합니다.
[코드 언어 = "r"]
ggplot(데이터 = ew_tweets,
aes(월(생성된_at, 레이블=TRUE, abbr=TRUE),
group=factor(year(created_at)), color=factor(year(created_at))))+
geom_line(stat="count") +
geom_point(stat="count") +
labs(x=”월”, color=”연도”) +
xlab("월") + ylab("트윗 수") +
theme_minimal()
[/암호]
결과는 다음 차트입니다.
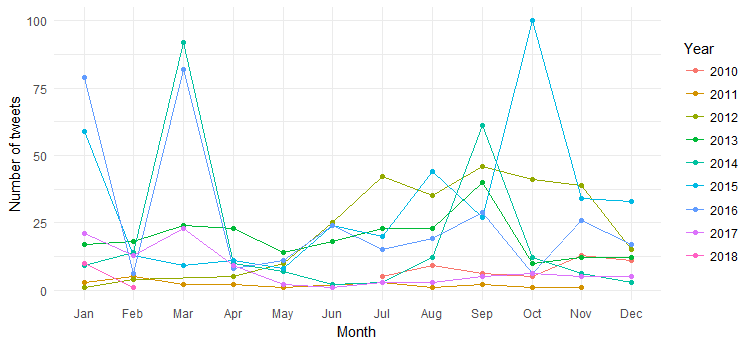
수년에 걸쳐 월별 트윗(2014년 3월, 2016년 3월 및 2015년 10월 급증)의 분할을 볼 수 있지만 해석은 어렵습니다. 이제 연도별 트윗 수만 표시하여 차트를 단순화해 보겠습니다.
[코드 언어 = "r"]
ggplot(데이터 = ew_tweets, aes(x = year(created_at))) +
geom_bar(aes(채우기 = ..count..)) +
xlab("연도") + ylab("트윗 수") +
scale_x_continuous(나누기 = c(2010:2018)) +
theme_minimal() +
scale_fill_gradient(낮음 = "cadetblue3", 높음 = "chartreuse4")
[/암호]
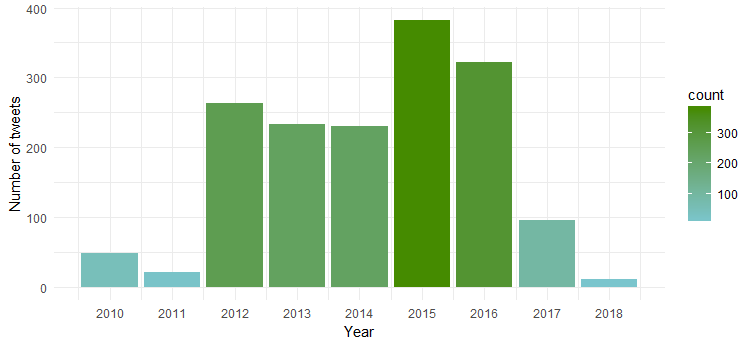
결과 차트에 따르면 그녀는 2015년과 2016년에 가장 활동적이었고 2011년에는 가장 활동이 적었습니다.
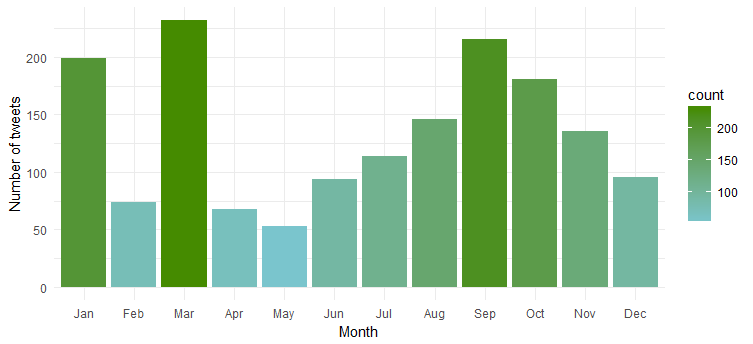
몇 달 동안 트윗 빈도
이제 Emma Watson Twitter 데이터에서 그녀가 1년 중 몇 달 동안 똑같이 트윗을 하는지 또는 가장 많이 트윗을 한 특정 달이 있는지 알아보겠습니다. 다음 코드를 사용하여 차트를 만듭니다.
[코드 언어 = "r"]
ggplot(데이터 = ew_tweets, aes(x = 월(생성된_at, 레이블 = TRUE))) +
geom_bar(aes(채우기 = ..count..)) +
xlab("월") + ylab("트윗 수") +
theme_minimal() +
scale_fill_gradient(낮음 = "cadetblue3", 높음 = "chartreuse4")
[/암호]
확실히 그녀는 '1월', '3월', '9월'에 가장 활동적이다.
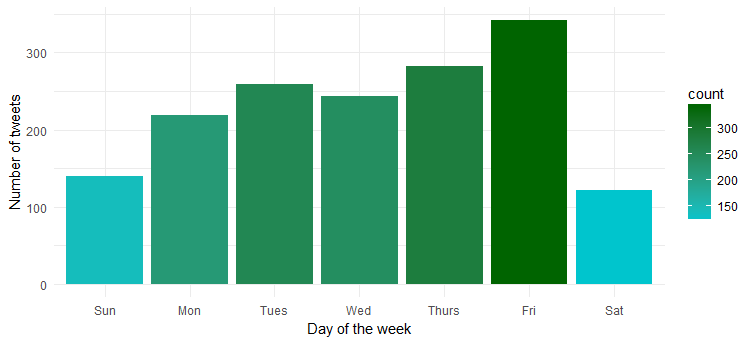
일주일 동안 트윗 빈도
그녀가 가장 활동적인 특정 요일이 있습니까? 다음 코드를 실행하여 차트를 플로팅해 보겠습니다.
[코드 언어 = "r"]
ggplot(데이터 = ew_tweets, aes(x = wday(created_at, 레이블 = TRUE))) +
geom_bar(aes(채우기 = ..count..)) +
xlab("요일") + ylab("트윗 수") +
theme_minimal() +
scale_fill_gradient(낮은 = "청록색3", 높음 = "진한 녹색")
[/암호]
흠...그녀는 금요일에 가장 활동적입니다. 파티 모드에 들어갈 준비가 되셨나요?
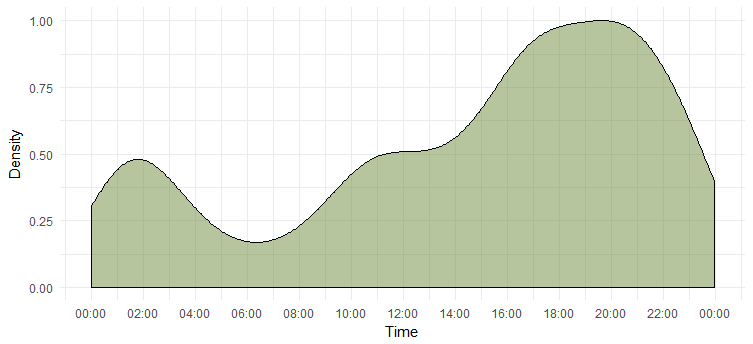
하루 동안의 트윗 밀도
우리는 가장 활동적인 날을 알아냈지만 그녀가 가장 활동적인 시간을 모릅니다. 다음 차트가 답을 줄 것입니다.
[코드 언어 = "r"]
# 하루 중 시간을 저장하고 포맷하는 패키지
install.packages("hms")
# 시간 휴식 및 레이블을 추가하는 패키지
install.packages("저울")
라이브러리("hms")
라이브러리("저울")
# 타임스탬프에서 시간만 추출, 즉 시, 분, 초
ew_tweets$time <- hms::hms(second(ew_tweets$created_at),
분(ew_tweets$created_at),
시간(ew_tweets$created_at))
# ggplot이 `hms`와 호환되지 않으므로 `POSIXct`로 변환
ew_tweets$time <- as.POSIXct(ew_tweets$time)
ggplot(데이터 = ew_tweets)+
geom_density(aes(x = 시간, y = ..scaled..),
채우기 = "다크 라이브그린4", 알파 = 0.3) +
xlab("시간") + ylab("밀도") +
scale_x_datetime(휴식 시간 = date_breaks("2시간"),
레이블 = date_format("%H:%M")) +
theme_minimal()
[/암호]

이것은 그녀가 오후 6시에서 8시 사이에 가장 활동적이라는 것을 알려줍니다. 시간대는 UTC입니다('unclass' 기능을 사용하여 확인할 수 있습니다. Emma를 트윗할 때 이 점을 염두에 두십시오.
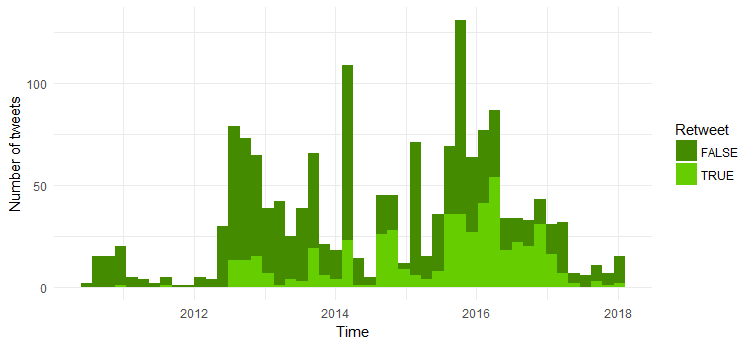
리트윗 수와 원본 트윗 수 비교
이제 원본 트윗과 리트윗 수를 비교하겠습니다. 코드는 다음과 같습니다.
[코드 언어 = "r"]
ggplot(데이터 = ew_tweets, aes(x = created_at, 채우기 = is_retweet)) +
geom_histogram(bins=48) +
xlab("시간") + ylab("트윗 수") + theme_minimal() +
scale_fill_manual(값 = c("chartreuse4", "chartreuse3"),
이름 = "리트윗")
[/암호]
대부분의 트윗은 원본 트윗입니다. 2014년에 비해 리트윗 횟수가 증가한 것은 흥미롭습니다.
텍스트 마이닝
이제 더 흥미로운 영역으로 들어가 보겠습니다. NLP를 포함한 텍스트 마이닝 기술을 수행하여 다음을 알아보겠습니다.
1. 자주 사용하는 해시태그
2. 트윗 텍스트의 워드 클라우드
3. 감정 분석
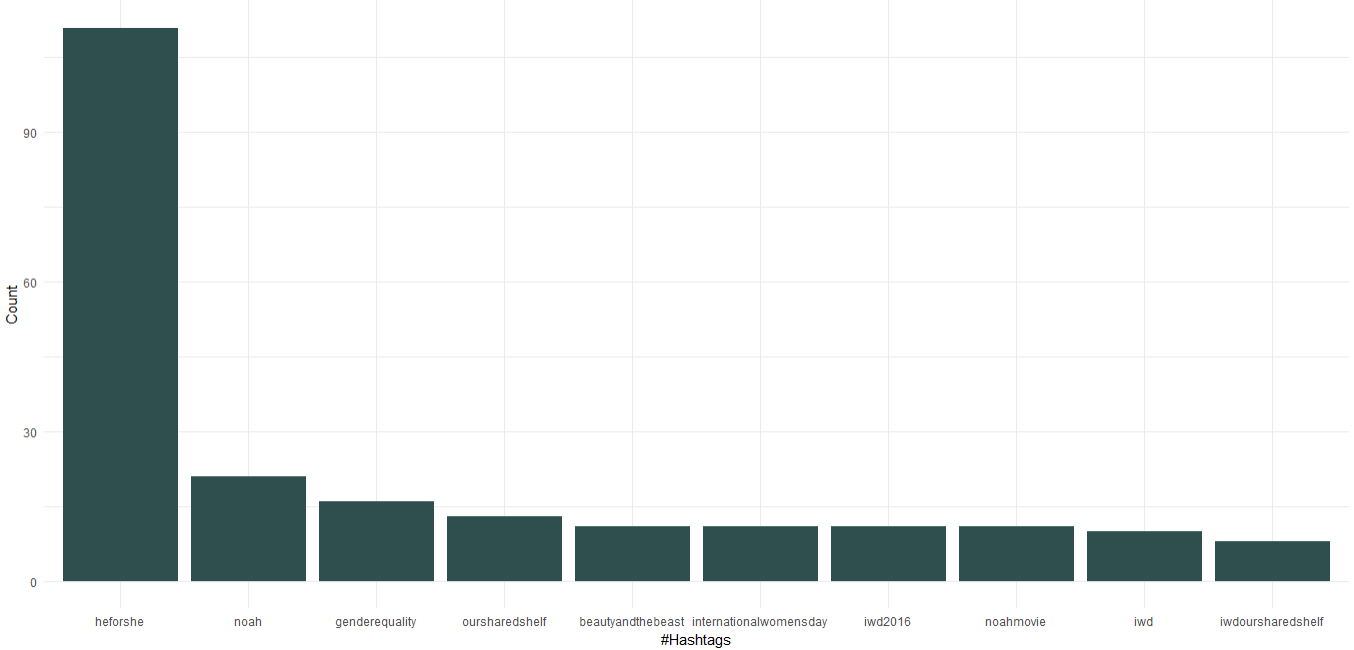
1. 자주 사용하는 해시태그
다운로드한 데이터세트에는 이미 해시태그가 포함된 열이 있습니다. 우리는 그것을 사용하여 Emma가 사용하는 상위 10개의 해시태그를 찾을 것입니다. 해시태그에 대한 차트를 만드는 코드는 다음과 같습니다.
[코드 언어 = "r"]
# 데이터 프레임으로 쉽게 작업할 수 있는 패키지
install.packages("dplyr")
라이브러리("dplyr")
# 목록에서 해시태그 가져오기
ew_tags_split <- unlist(strsplit(as.character(unlist(ew_tweets$hashtags)),'^c(|,|”|)'))
# 공백을 제거하여 서식 지정a
ew_tags <- sapply(ew_tags_split, function(y) nchar(trimws(y)) > 0 & !is.na(y))
ew_tag_df <- as_data_frame(테이블(tolower(ew_tags_split[ew_tags])))
ew_tag_df <- ew_tag_df[with(ew_tag_df,order(-n)),]
ew_tag_df <- ew_tag_df[1:10,]
ggplot(ew_tag_df, aes(x = 재정렬(Var1, -n), y=n)) +
geom_bar(stat=”identity”, fill=”darkslategray”)+
theme_minimal() +
xlab("#해시태그") + ylab("카운트")
[/암호]
엠마 왓슨은 유엔 여성 친선대사로서 성평등에 초점을 맞춘 “HeForShe” 캠페인을 추진하고 있습니다. 그 외에도 그녀는 "Our Shared Shelf"와 "International Women's Day"라는 책 클럽을 홍보했습니다. 영화에 나오는 "노아", "미녀와 야수"는 상위 10개 해시태그에 포함됩니다.
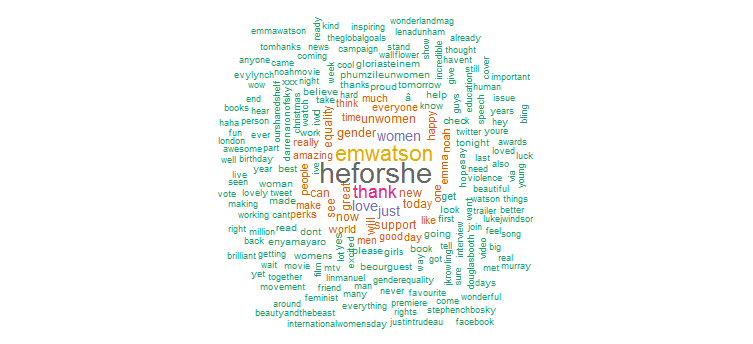
2. 워드 클라우드
이제 트윗 텍스트를 분석하여 가장 자주 사용되는 단어를 찾고 워드 클라우드를 만듭니다. 계속하려면 다음 코드를 실행하십시오.
[코드 언어 = "r"]
#텍스트마이닝및워드클라우드패키지설치
install.packages(c("tm", "wordcloud"))
라이브러리("tm")
라이브러리("워드클라우드")
트윗_텍스트 <- ew_tweets$text
#숫자, 구두점, 링크 및 영숫자 콘텐츠 제거
Tweet_text<- gsub('[[:digit:]]+', ”, tweet_text)
Tweet_text<- gsub('[[:punct:]]+', ”, tweet_text)
Tweet_text<- gsub("http[[:alnum:]]*", "", tweet_text)
트윗_텍스트<- gsub("([[:알파:]])1+", "", 트윗_텍스트)
#텍스트 코퍼스 생성
문서 <- 코퍼스(VectorSource(tweet_text))
# 재미있는 문자를 처리하기 위해 인코딩을 UTF-8로 덮습니다.
문서 <- tm_map(문서, 기능(x) iconv(enc2utf8(x), 하위 = "바이트"))
# 텍스트를 소문자로 변환
문서 <- tm_map(문서, content_transformer(tolower))
# 영어 공통 불용어 제거
문서 <- tm_map(문서, 제거 단어, 불용어("영어"))
# 문자형 벡터로 지정한 불용어 제거
문서 <- tm_map(문서, removeWords, c("amp"))
# 용어 문서 행렬 생성
tdm <- TermDocumentMatrix(문서)
# tdm을 행렬로 정의
m <- as.matrix(tdm)
# 단어 수를 내림차순으로 가져오기
word_freqs = 정렬(rowSums(m), 감소=TRUE)
# 단어와 빈도로 데이터 프레임 생성
ew_wf <- data.frame(단어=이름(단어_주파수), 주파수=단어_주파수)
# 플로팅 워드 클라우드
set.seed(1234)
wordcloud(단어 = ew_wf$단어, 주파수 = ew_wf$freq,
min.freq = 1, scale=c(1.8,.5),
max.words=200, random.order=FALSE, rot.per=0.15,
색상=brewer.pal(8, "Dark2"))
[/암호]
분명히 그녀는 "HeforShe" 캠페인을 위해 과감한 프로모션을 했습니다. 다른 자주 사용되는 단어는 "고마워", "사랑", "여성", "젠더" 및 "UNWomen"입니다. 이것은 그녀의 트위터 활동이 여성 문제에 상당히 집중되어 있음을 시사하는 해시태그와 분명히 일치합니다.
3. 감정 분석
감정 추출 및 플로팅을 위해 syuzhet 패키지를 적용합니다. 이 패키지는 다양한 감정(기쁨, 두려움, 분노, 놀람 등)과 감정 극성(긍정/부정)으로 다른 단어를 매핑하는 감정 어휘집을 기반으로 합니다. 우리는 트윗에 있는 단어를 기반으로 감정 점수를 계산하고 동일한 플롯을 그려야 합니다.
[코드 언어 = "r"]
install.packages("syuzhet")
도서관(슈제트)
# 이상한 문자를 추적하기 위해 트윗을 ASCII로 변환
Tweet_text <- iconv(tweet_text, from=”UTF-8″, to=”ASCII”, sub=””)
# 리트윗 삭제
Tweet_text<-gsub("(RT|via)((?:bw*@w+)+)",",tweet_text)
# 멘션 제거
Tweet_text<-gsub(“@w+”,””,tweet_text)
ew_sentiment<-get_nrc_sentiment((tweet_text))
감정 점수<-data.frame(colSums(ew_sentiment[,]))
이름(감정 점수) <- "점수"
감정 점수 <- cbind(“sentiment”=rownames(sentimentscores),sentimentscores)
행 이름(감정 점수) <- NULL
ggplot(데이터=감정점수,aes(x=감정,y=점수))+
geom_bar(aes(fill=sentiment),stat = "identity")+
테마(legend.position="없음")+
xlab("감정")+ylab("점수")+
ggtitle("점수에 따른 총 감정")+
theme_minimal()
[/암호]
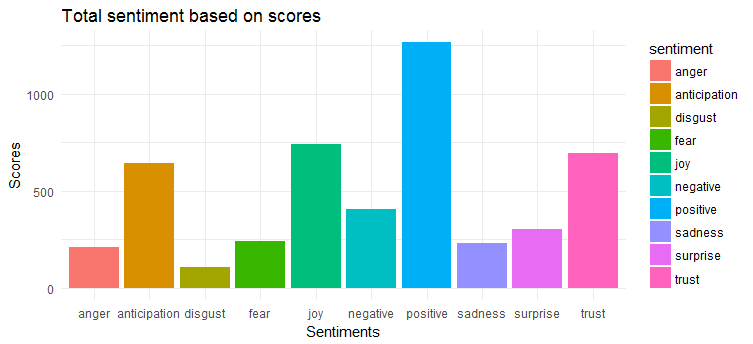
다음 차트는 트윗이 대체로 긍정적인 감정을 가지고 있음을 보여줍니다. 가장 많이 표현되는 감정 3가지는 '기쁨', '신뢰', '기대'다.
너에게
이 연구에서 우리는 Emma Watson이 게시한 트윗의 기본 주제와 트윗 패턴을 이해하기 위한 탐색적 데이터 분석 및 텍스트 마이닝 기술을 다루었습니다. 추가 분석을 수행하여 자주 언급되는 트위터 사용자를 찾고, 네트워크 그래프를 생성하고, 주제 모델링을 사용하여 트윗을 분류할 수 있습니다.
이 튜토리얼을 따라 댓글 섹션에서 발견한 내용을 공유하세요.
