
ขุดทวีตของ Emma Watson กับ R
เผยแพร่แล้ว: 2018-02-03สตรีม Twitter ของบุคคลใด ๆ มีข้อมูลโซเชียลมากมายที่สามารถเปิดเผยเกี่ยวกับบุคคลนั้นได้มากมาย เนื่องจากข้อมูล Twitter เป็นแบบสาธารณะและ API เปิดให้ทุกคนใช้งานได้ เทคนิคการทำเหมืองข้อมูลจึงสามารถนำไปใช้เพื่อค้นหาทุกอย่างได้อย่างง่ายดาย ตั้งแต่รูปแบบเวลาและหัวข้อที่บุคคลนั้นมุ่งเน้น ไปจนถึงรูปแบบข้อความที่ใช้เพื่อแสดงมุมมองและความคิด

ในการศึกษานี้ เราจะใช้ R เพื่อทำการวิเคราะห์ทวีตที่โพสต์โดยคนดังที่มีชื่อเสียงที่สุดคนหนึ่ง เช่น Emma Watson ขั้นแรก เราจะทำการวิเคราะห์เชิงสำรวจ แล้วย้ายไปที่การวิเคราะห์ข้อความ
กำลังดึงข้อมูล Twitter ของ Emma Watson
Twitter API ช่วยให้เราดาวน์โหลดทวีตล่าสุดได้ 3,200 ทวีต — ทั้งหมดที่เราต้องทำคือสร้างแอพ Twitter เพื่อรับคีย์ API และโทเค็นการเข้าถึง ทำตามขั้นตอนด้านล่างเพื่อสร้างแอป:
- เปิด https://apps.twitter.com
- คลิกที่ 'สร้างแอปใหม่'
- ป้อนรายละเอียดและคลิกที่ 'สร้างแอปพลิเคชัน Twitter ของคุณ'
- คลิกที่แท็บ 'คีย์และโทเค็นการเข้าถึง' และคัดลอกคีย์ API และข้อมูลลับ
- เลื่อนลงและคลิกที่ "สร้างโทเค็นเพื่อการเข้าถึงของฉัน"
มีไลบรารี R ที่เรียกว่า rtweet ซึ่งจะใช้ในการดาวน์โหลดทวีตและสร้างกรอบข้อมูล ใช้รหัสที่ระบุด้านล่างเพื่อดำเนินการต่อ:
[รหัสภาษา =”r”]
install.packages("httr")
install.packages(“rtweet”)
ห้องสมุด("httr")
ห้องสมุด("rtweet")
# ชื่อของแอพ Twitter ที่คุณสร้างขึ้น
appname <- “ทวีต-วิเคราะห์”
# คีย์ api (แทนที่ตัวอย่างต่อไปนี้ด้วยคีย์ของคุณ)
คีย์ <- “8YnCioFqKFaebTwjoQfcVLPS”
# api secret (แทนที่สิ่งต่อไปนี้ด้วยความลับของคุณ)
ความลับ <- “uSzkAOXnNpSDsaDAaDDDSddsA6Cukfds8a3tRtSG”
# สร้างโทเค็นชื่อ “twitter_token”
twitter_token <- create_token(
แอพ = ชื่อแอพ,
Consumer_key = คีย์
Consumer_secret = ความลับ)
#ดาวน์โหลดทวีตที่โพสต์โดย Emma Watson
ew_tweets <- get_timeline(“EmmaWatson”, n = 3200)
[/รหัส]
การวิเคราะห์เชิงสำรวจ
เราจะสรุปชุดข้อมูลโดยแสดงภาพต่อไปนี้:
- จำนวนทวีตที่โพสต์ตั้งแต่ปี 2010 ถึง 2018
- ความถี่ทวีตในช่วงหลายเดือน
- ความถี่ทวีตตลอดทั้งสัปดาห์
- ทวีตหนาแน่นตลอดวัน
- เปรียบเทียบจำนวนรีทวีตและทวีตต้นฉบับ
ทวีตที่ชาญฉลาดประจำปี
เราจะใช้ไลบรารี ggplot2 และ lubridate ที่น่าทึ่งเพื่อลงจุดแผนภูมิและทำงานกับวันที่ ไปข้างหน้าและทำตามรหัสที่ระบุด้านล่างเพื่อติดตั้งและโหลดแพ็คเกจ:
[รหัสภาษา =”r”]
install.packages(“ggplot2”)
install.packages("หล่อลื่น")
ห้องสมุด (“ggplot2”)
ห้องสมุด("หล่อลื่น")
[/รหัส]
รันโค้ดต่อไปนี้เพื่อพล็อตการนับทวีตในช่วงหลายปีที่ผ่านมาโดยแบ่งเป็นเดือน:
[รหัสภาษา =”r”]
ggplot (ข้อมูล = ew_tweets,
aes(เดือน(created_at, label=TRUE, abbr=TRUE),
group=factor(year(created_at)), color=factor(year(created_at))))+
geom_line(stat=”นับ”) +
geom_point(stat=”นับ”) +
ห้องปฏิบัติการ(x=”เดือน”, สี=”ปี”) +
xlab("เดือน") + ylab("จำนวนทวีต") +
theme_minimal()
[/รหัส]
ผลลัพธ์เป็นแผนภูมิต่อไปนี้:
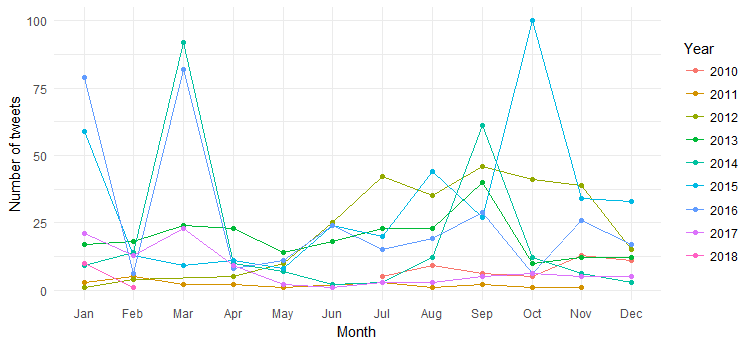
เราสามารถเห็นการเลิกราของทวีตรายเดือน (เพิ่มขึ้นในเดือนมีนาคม 2014 มีนาคม 2016 และตุลาคม 2015) ในช่วงหลายปีที่ผ่านมา แต่การตีความเป็นเรื่องยาก ตอนนี้เรามาทำให้แผนภูมิง่ายขึ้นโดยพล็อตเฉพาะจำนวนทวีตประจำปี
[รหัสภาษา =”r”]
ggplot(data = ew_tweets, aes(x = year(created_at))) +
geom_bar(aes(เติม = ..นับ..)) +
xlab("ปี") + ylab("จำนวนทวีต") +
scale_x_continuous (พัก = c(2010:2018)) +
theme_minimal() +
scale_fill_gradient (ต่ำ = "cadetblue3", สูง = "chartreuse4")
[/รหัส]
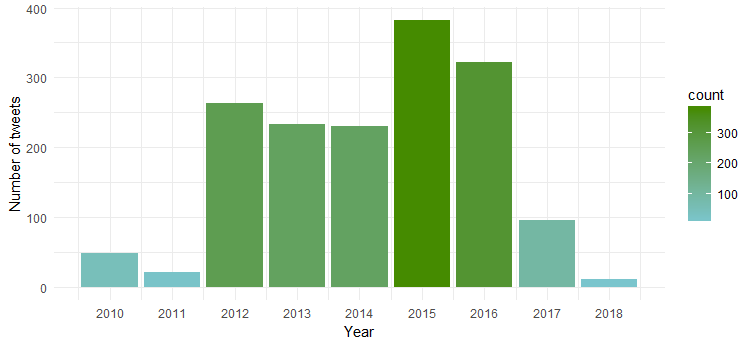
แผนภูมิผลลัพธ์แสดงให้เห็นว่าเธอมีความกระตือรือร้นมากที่สุดในปี 2558 และ 2559 ในขณะที่ปี 2554 มีกิจกรรมน้อยที่สุด
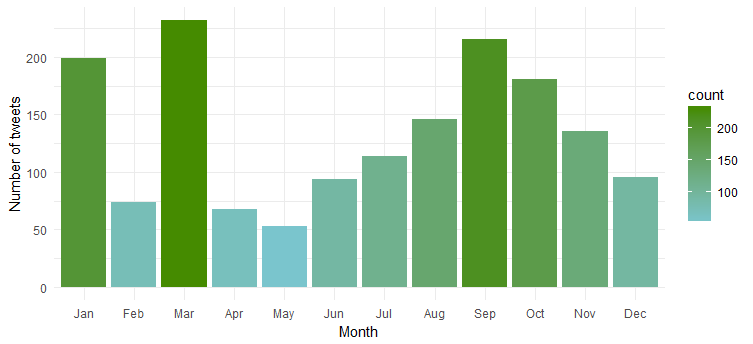
ความถี่ทวีตในช่วงหลายเดือน
ตอนนี้เรามาดูกันในข้อมูล Twitter ของ Emma Watson เพื่อดูว่าเธอทวีตเท่าๆ กันในช่วงหลายเดือนของปี หรือมีเดือนใดโดยเฉพาะที่เธอทวีตมากที่สุด ใช้รหัสต่อไปนี้เพื่อสร้างแผนภูมิ:
[รหัสภาษา =”r”]
ggplot(data = ew_tweets, aes(x = month(created_at, label = TRUE))) +
geom_bar(aes(เติม = ..นับ..)) +
xlab("เดือน") + ylab("จำนวนทวีต") +
theme_minimal() +
scale_fill_gradient (ต่ำ = "cadetblue3", สูง = "chartreuse4")
[/รหัส]
เห็นได้ชัดว่าเธอใช้งานมากที่สุดในช่วง 'มกราคม', 'มีนาคม' และ 'กันยายน'
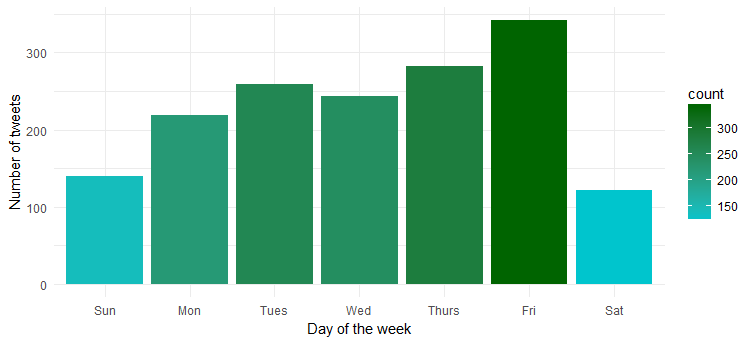
ความถี่ทวีตตลอดทั้งสัปดาห์
มีวันใดในสัปดาห์ที่เธอทำกิจกรรมมากที่สุดหรือไม่? ลองพล็อตแผนภูมิโดยรันโค้ดต่อไปนี้:
[รหัสภาษา =”r”]
ggplot(data = ew_tweets, aes(x = wday(created_at, label = TRUE))) +
geom_bar(aes(เติม = ..นับ..)) +
xlab("วันในสัปดาห์") + ylab("จำนวนทวีต") +
theme_minimal() +
scale_fill_gradient (ต่ำ = “สีเขียวขุ่น 3”, สูง = “เขียวเข้ม”)
[/รหัส]
อืม…เธอมีความกระตือรือร้นมากที่สุดในวันศุกร์ อาจพร้อมที่จะเข้าสู่โหมดปาร์ตี้?
ทวีตหนาแน่นตลอดวัน
เราพบวันที่กระตือรือร้นที่สุดแล้ว แต่เราไม่รู้ว่าเธอมีความกระตือรือร้นมากที่สุดเมื่อใด แผนภูมิต่อไปนี้จะให้คำตอบแก่เรา
[รหัสภาษา =”r”]
# แพ็คเกจสำหรับจัดเก็บและจัดรูปแบบเวลาของวัน
install.packages("hms")
# แพ็คเกจเพิ่มตัวแบ่งเวลาและป้ายกำกับ
install.packages("สเกล")
ห้องสมุด (“hms”)
ห้องสมุด("ตาชั่ง")
# แยกเฉพาะเวลาจากการประทับเวลา เช่น ชั่วโมง นาที และวินาที
ew_tweets$เวลา <- hms::hms(second(ew_tweets$created_at),
นาที(ew_tweets$created_at),
ชั่วโมง(ew_tweets$created_at))
# การแปลงเป็น `POSIXct` เนื่องจาก ggplot เข้ากันไม่ได้กับ `hms`
ew_tweets$เวลา <- as.POSIXct(ew_tweets$time)
ggplot(data = ew_tweets)+
geom_density(aes(x = เวลา, y = ..สเกล..),
เติม=”darkolivegreen4″, alpha=0.3) +
xlab("เวลา") + ylab("ความหนาแน่น") +
scale_x_datetime(breaks = date_breaks(“2 ชั่วโมง”),
labels = date_format(“%H:%M”)) +
theme_minimal()
[/รหัส]

สิ่งนี้บอกเราว่าเธอใช้งานมากที่สุดในช่วง 18-20 น. โปรดทราบว่าเขตเวลาคือ UTC (ค้นหาได้โดยใช้ฟังก์ชัน 'unclass' โปรดระลึกไว้เสมอว่าขณะทวีต Emma
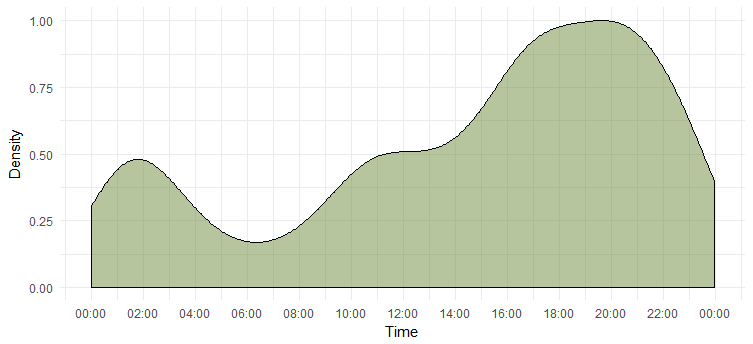
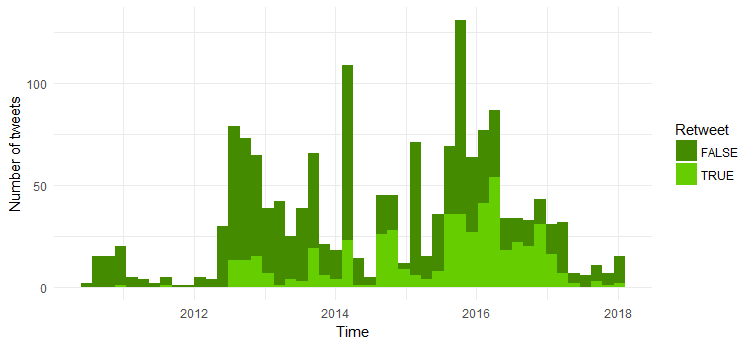
เปรียบเทียบจำนวนรีทวีตและทวีตต้นฉบับ
ตอนนี้เราจะเปรียบเทียบจำนวนทวีตดั้งเดิมและทวีตซ้ำ รับด้านล่างเป็นรหัส:
[รหัสภาษา =”r”]
ggplot(data = ew_tweets, aes(x = created_at, fill = is_retweet)) +
geom_histogram(ถัง=48) +
xlab("Time") + ylab("จำนวนทวีต") + theme_minimal() +
scale_fill_manual(values = c(“chartreuse4”, “chartreuse3”),
ชื่อ = “รีทวีต”)
[/รหัส]
ทวีตส่วนใหญ่เป็นทวีตดั้งเดิม น่าสนใจที่จำนวนรีทวีตเพิ่มขึ้นจากปี 2014
การขุดข้อความ
มาดูส่วนที่น่าสนใจกันดีกว่า — เราจะใช้เทคนิคการทำเหมืองข้อความรวมถึง NLP เพื่อค้นหาสิ่งต่อไปนี้:
1. แฮชแท็กที่ใช้บ่อย
2. Word cloud ของข้อความทวีต
3. การวิเคราะห์ความรู้สึก
1. แฮชแท็กที่ใช้บ่อย
ชุดข้อมูลที่ดาวน์โหลดมีคอลัมน์ที่มีแฮชแท็กอยู่แล้ว เราจะใช้สิ่งนั้นเพื่อค้นหาแฮชแท็ก 10 อันดับแรกที่ Emma ใช้ รับด้านล่างเป็นรหัสเพื่อสร้างแผนภูมิสำหรับแฮชแท็ก:
[รหัสภาษา =”r”]
# แพ็คเกจเพื่อทำงานกับ data frames อย่างง่ายดาย
install.packages(“dplyr”)
ห้องสมุด("dplyr")
#รับแฮชแท็กจากรายการ
ew_tags_split <- unlist(strsplit(as.character(unlist(ew_tweets$hashtags)),'^c(|,|”|)'))
# การจัดรูปแบบโดยการลบช่องว่างสีขาว
ew_tags <- sapply(ew_tags_split, function(y) nchar(trimws(y)) > 0 & !is.na(y))
ew_tag_df <- as_data_frame(table(tolower(ew_tags_split[ew_tags])))
ew_tag_df <- ew_tag_df[with(ew_tag_df,order(-n)),]
ew_tag_df <- ew_tag_df[1:10,]
ggplot(ew_tag_df, aes(x = จัดลำดับใหม่ (Var1, -n), y=n)) +
geom_bar(stat=”identity”, fill=”darkslategray”)+
theme_minimal() +
xlab("#แฮชแท็ก") + ylab("นับ")
[/รหัส]
เราเห็นได้ว่าในฐานะทูตสันถวไมตรีแห่งสหประชาชาติ เอ็มมา วัตสันได้ส่งเสริมแคมเปญ “HeForShe” ซึ่งเน้นที่ความเท่าเทียมทางเพศ นอกจากนั้น เธอยังได้โปรโมตชมรมหนังสือของเธอที่ชื่อว่า "ชั้นวางที่ใช้ร่วมกันของเรา" และ "วันสตรีสากล" มาถึงภาพยนตร์ “โนอาห์”, “โฉมงามกับอสูร” ในแฮชแท็ก 10 อันดับแรก
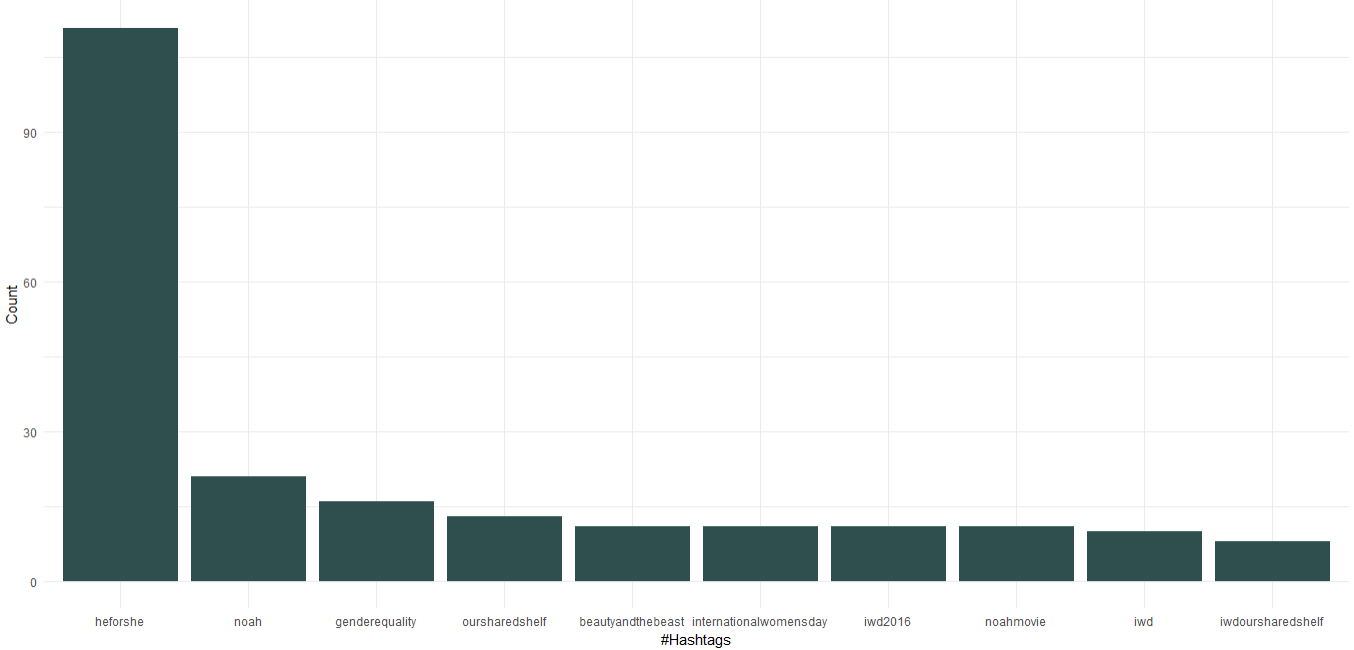
2. เวิร์ดคลาวด์
ตอนนี้เราจะวิเคราะห์ข้อความทวีตเพื่อค้นหาคำที่ใช้บ่อยที่สุดและสร้างคลาวด์คำ รันรหัสต่อไปนี้เพื่อดำเนินการต่อ:
[รหัสภาษา =”r”]
#ติดตั้งแพ็คเกจการทำเหมืองข้อความและเวิร์ดคลาวด์
install.packages(c(“tm”, “wordcloud”))
ห้องสมุด (“tm”)
ห้องสมุด (“wordcloud”)
tweet_text <- ew_tweets$text
#การลบตัวเลข เครื่องหมายวรรคตอน ลิงก์ และเนื้อหาที่เป็นตัวอักษรและตัวเลข
tweet_text<- gsub('[[:digit:]]+', ”, tweet_text)
tweet_text<- gsub('[[:punct:]]+', ”, tweet_text)
tweet_text<- gsub(“http[[:alnum:]]*”, “”, tweet_text)
tweet_text<- gsub(“([[:alpha:]])1+”, “”, tweet_text)
#การสร้างคลังข้อความ
เอกสาร <- Corpus(VectorSource(tweet_text))
# ปิดการเข้ารหัสเป็น UTF-8 เพื่อจัดการกับตัวตลก
เอกสาร <- tm_map(docs, function(x) iconv(enc2utf8(x), sub = “byte”))
#แปลงข้อความเป็นตัวพิมพ์เล็ก
เอกสาร <- tm_map(docs, content_transformer(tolower))
# การลบคำหยุดทั่วไปภาษาอังกฤษ
เอกสาร <- tm_map(docs, removeWords, stopwords("ภาษาอังกฤษ"))
# การลบคำหยุดที่เราระบุเป็นเวกเตอร์อักขระ
เอกสาร <- tm_map(docs, removeWords, c(“amp”))
#สร้างเมทริกซ์เอกสารเทอม
tdm <- TermDocumentMatrix (เอกสาร)
# กำหนด tdm เป็นเมทริกซ์
ม <- as.matrix(tdm)
# นับจำนวนคำในลำดับที่ลดลง
word_freqs = sort(rowSums(m), ลดลง=TRUE)
# การสร้าง data frame ด้วยคำและความถี่
ew_wf <- data.frame(word=names(word_freqs), freq=word_freqs)
#พล็อต wordcloud
ชุด.เมล็ด(1234)
wordcloud (คำ = ew_wf$word, ความถี่ = ew_wf$freq,
min.freq = 1,ขนาด=c(1.8,.5),
max.words=200, random.order=FALSE, rot.per=0.15,
สี=brewer.pal(8, “Dark2”))
[/รหัส]
เห็นได้ชัดว่าเธอได้ทำการโปรโมตอย่างหนักสำหรับแคมเปญ “HeforShe” คำอื่นๆ ที่ใช้บ่อย ได้แก่ “ขอบคุณ” “ความรัก” “ผู้หญิง” “เพศ” และ “UNWomen” เห็นได้ชัดว่าสอดคล้องกับแฮชแท็กซึ่งแสดงให้เห็นว่ากิจกรรม Twitter ของเธอค่อนข้างเน้นไปที่ประเด็นของผู้หญิง
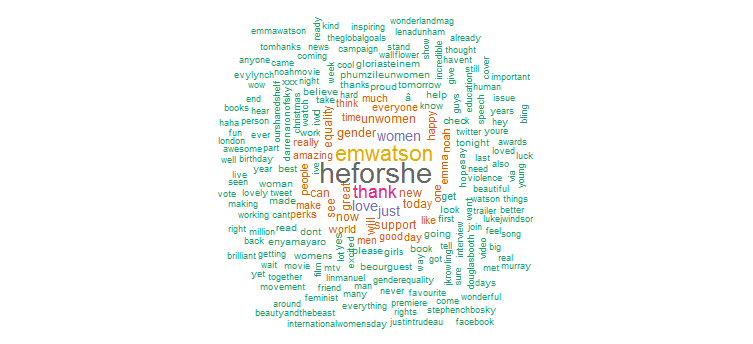
3. การวิเคราะห์ความรู้สึก
สำหรับการดึงความรู้สึกและการวางแผน เราจะใช้แพ็คเกจ syuzhet แพ็คเกจนี้ใช้คำศัพท์ทางอารมณ์ซึ่งจับคู่คำต่างๆ กับอารมณ์ต่างๆ (ความสุข ความกลัว ความโกรธ ความประหลาดใจ ฯลฯ) และอารมณ์ความรู้สึก (บวก/ลบ) เราจะต้องคำนวณคะแนนอารมณ์ตามคำที่มีอยู่ในทวีตและพล็อตเหมือนกัน
[รหัสภาษา =”r”]
install.packages(“syuzhet”)
ห้องสมุด(syuzhet)
# การแปลงทวีตเป็น ASCII เพื่อติดตามตัวละครแปลก ๆ
tweet_text <- iconv(tweet_text, from=”UTF-8″, to=”ASCII”, sub=””)
#ลบรีทวีต
tweet_text<-gsub("(RT|via)((?:bw*@w+)+)",””,tweet_text)
# ลบการกล่าวถึง
tweet_text<-gsub(“@w+”,”,”tweet_text)
ew_sentiment<-get_nrc_sentiment((ข้อความทวีต))
คะแนนความรู้สึก<-data.frame(colSums(ew_sentiment[,]))
ชื่อ (คะแนนความรู้สึก) <- “คะแนน”
Sentimentscores <- cbind(“sentiment”=rownames(sentimentscores),sentimentscores)
ชื่อแถว (คะแนนความรู้สึก) <- NULL
ggplot(data=sentimentscores,aes(x=sentiment,y=Score))+
geom_bar(aes(เติม=ความรู้สึก),stat = “ตัวตน”)+
ธีม(legend.position=”none”)+
xlab("ความรู้สึก")+ylab("คะแนน")+
ggtitle("ความรู้สึกโดยรวมตามคะแนน")+
theme_minimal()
[/รหัส]
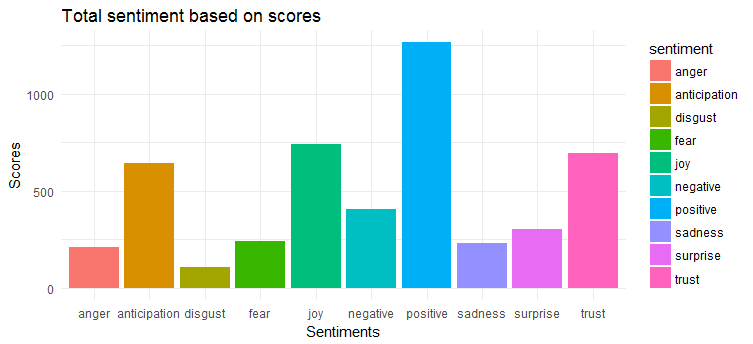
แผนภูมิต่อไปนี้แสดงให้เห็นว่าทวีตมีความรู้สึกเชิงบวกเป็นส่วนใหญ่ อารมณ์ที่แสดงออกมามากที่สุด 3 อันดับแรก ได้แก่ 'ความสุข' 'ความไว้วางใจ' และ 'ความคาดหวัง'
ไปยังคุณ
ในการศึกษานี้ เราครอบคลุมการวิเคราะห์ข้อมูลเชิงสำรวจและเทคนิคการทำเหมืองข้อความ เพื่อทำความเข้าใจรูปแบบการทวีตและธีมพื้นฐานของทวีตที่โพสต์โดย Emma Watson สามารถดำเนินการวิเคราะห์เพิ่มเติมเพื่อค้นหาผู้ใช้ทวิตเตอร์ที่กล่าวถึงบ่อย สร้างกราฟเครือข่าย และจำแนกทวีตโดยใช้แบบจำลองหัวข้อ
ทำตามบทช่วยสอนนี้และแชร์สิ่งที่คุณค้นพบในส่วนความคิดเห็น
