
Emma Watson'ın Tweetlerini R ile Madencilik
Yayınlanan: 2018-02-03Herhangi bir kişinin Twitter akışı, o kişi hakkında çok şey ortaya çıkarabilecek zengin sosyal veriler içerir. Twitter verileri herkese açık olduğundan ve API herkesin kullanımına açık olduğundan, zamanlama kalıplarından ve kişinin odaklandığı konulardan görüş ve düşünceleri ifade etmek için kullanılan metin kalıplarına kadar her şeyi bulmak için veri madenciliği teknikleri kolayca uygulanabilir.

Bu çalışmada, en ünlü ünlülerden biri olan Emma Watson'ın attığı tweetler üzerinde R analiz etmek için kullanacağız. İlk önce keşif analizinden geçeceğiz ve ardından metin analizine geçeceğiz.
Emma Watson'ın Twitter Verilerini Çıkarma
Twitter API, 3.200 yeni tweet'i indirmemize izin veriyor - tek yapmamız gereken, API anahtarını ve erişim belirtecini almak için bir Twitter uygulaması oluşturmak. Uygulamayı oluşturmak için aşağıda verilen adımları izleyin:
- https://apps.twitter.com'u açın
- 'Yeni Uygulama Oluştur'a tıklayın
- Ayrıntıları girin ve 'Twitter uygulamanızı oluşturun' seçeneğini tıklayın
- 'Anahtarlar ve Erişim Simgeleri' sekmesine tıklayın ve API anahtarını ve sırrını kopyalayın
- Aşağı kaydırın ve "Erişim jetonumu oluştur" u tıklayın
Tweetleri indirmek ve bir veri çerçevesi oluşturmak için kullanılacak rtweet adında bir R kütüphanesi var. Devam etmek için aşağıda verilen kodu kullanın:
[kod dili=”r”]
install.packages(“httr”)
install.packages(“rtweet”)
kitaplık ("httr")
kitaplık ("rtweet")
# sizin tarafınızdan oluşturulan twitter uygulamasının adı
uygulama adı <- "tweet analizi"
# api anahtarı (aşağıdaki örneği anahtarınızla değiştirin)
tuşu <- “8YnCioFqKFaebTwjoQfcVLPS”
# api sırrı (aşağıdakini sırrınızla değiştirin)
gizli <- “uSzkAOXnNpSDsaDAaDDDSddsA6Cukfds8a3tRtSG”
# "twitter_token" adlı jeton oluştur
twitter_token <- create_token(
uygulama = uygulama adı,
tüketici_anahtar = anahtar,
tüketici_gizi = gizli)
#Emma Watson tarafından gönderilen tweet'leri indirme
ew_tweets <- get_timeline(“EmmaWatson”, n = 3200)
[/kod]
Keşif analizi
Burada, aşağıdakileri görselleştirerek veri kümesini özetleyeceğiz:
- 2010'dan 2018'e atılan tweet sayısı
- Aylara göre tweet sıklığı
- Bir hafta boyunca tweet sıklığı
- Bir gün boyunca tweet yoğunluğu
- Yeniden tweet ve orijinal tweet sayısının karşılaştırılması
yıllık tweetler
Grafikleri çizmek ve tarihlerle çalışmak için harika ggplot2 ve lubridate kitaplığını kullanacağız. Devam edin ve paketleri kurmak ve yüklemek için aşağıda verilen kodu izleyin:
[kod dili=”r”]
install.packages(“ggplot2”)
install.packages(“yağlama”)
kitaplık ("ggplot2")
kitaplık ("yağlama")
[/kod]
Aylara bölünerek yıllar boyunca tweet sayısını çizmek için aşağıdaki kodu yürütün:
[kod dili=”r”]
ggplot(veri = ew_tweets,
aes(ay(yaratılan_at, etiket=DOĞRU, kısaltılmış=DOĞRU),
grup=faktör(yıl(yaratılan_at)), renk=etken(yıl(yaratılan_at))))+
geom_line(stat=”say”) +
geom_point(stat=”say”) +
labs(x=”Ay”, color=”Yıl”) +
xlab(“Ay”) + ylab(“Tweet sayısı”) +
tema_minimal()
[/kod]
Sonuç aşağıdaki tablodur:
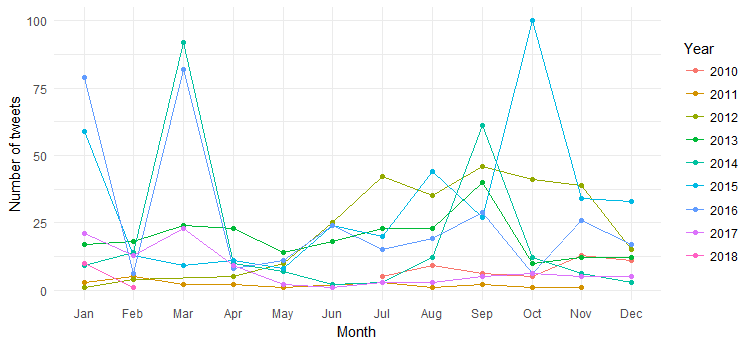
Aylık tweetlerin (Mart 2014, Mart 2016 ve Ekim 2015'te ani artışlar) yıllar içinde dağıldığını görebiliriz, ancak yorumlamak zordur. Şimdi sadece yıl bazında tweet sayılarını çizerek grafiği basitleştirelim.
[kod dili=”r”]
ggplot(veri = ew_tweets, aes(x = yıl(created_at))) +
geom_bar(aes(dolgu = ..say..)) +
xlab(“Yıl”) + ylab(“Tweet sayısı”) +
scale_x_continuous (aralar = c(2010:2018)) +
theme_minimal() +
scale_fill_gradient(düşük = “cadetblue3”, yüksek = “chartreuse4”)
[/kod]
Ortaya çıkan grafik, 2015 ve 2016'da en aktif olduğunu, 2011'de ise en az aktiviteye tanık olduğunu gösteriyor.
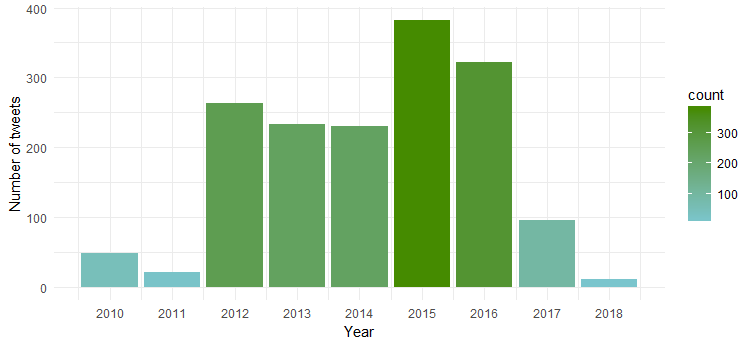
Aylara göre tweet sıklığı
Şimdi Emma Watson Twitter Verilerinde bir yılın ayları boyunca eşit şekilde tweet atıp atmadığını veya en çok tweet attığı belirli aylar olup olmadığını öğrenelim. Grafiği oluşturmak için aşağıdaki kodu kullanın:
[kod dili=”r”]
ggplot(veri = ew_tweets, aes(x = ay(created_at, etiket = DOĞRU))) +
geom_bar(aes(dolgu = ..say..)) +
xlab(“Ay”) + ylab(“Tweet sayısı”) +
theme_minimal() +
scale_fill_gradient(düşük = “cadetblue3”, yüksek = “chartreuse4”)
[/kod]
Açıkçası en aktif olduğu 'Ocak', 'Mart' ve 'Eylül'.
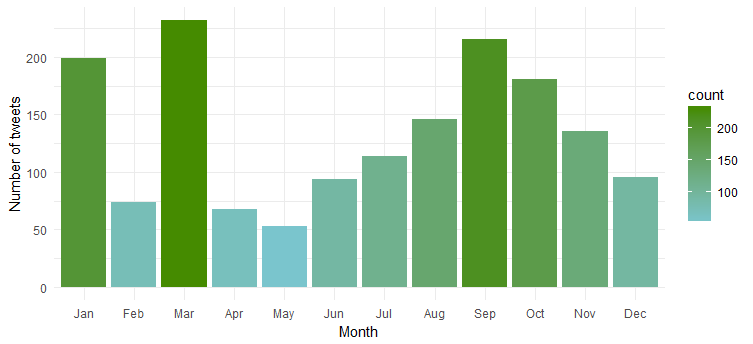
Bir hafta boyunca tweet sıklığı
En aktif olduğu haftanın belirli bir günü var mı? Aşağıdaki kodu çalıştırarak grafiği çizelim:
[kod dili=”r”]
ggplot(veri = ew_tweets, aes(x = wday(created_at, etiket = DOĞRU))) +
geom_bar(aes(dolgu = ..say..)) +
xlab(“Haftanın Günü”) + ylab(“Tweet sayısı”) +
theme_minimal() +
scale_fill_gradient(düşük = “turkuaz3”, yüksek = “koyu yeşil”)
[/kod]
Hmm… o en çok Cuma günü aktif. Muhtemelen parti moduna girmeye mi hazırlanıyorsunuz?
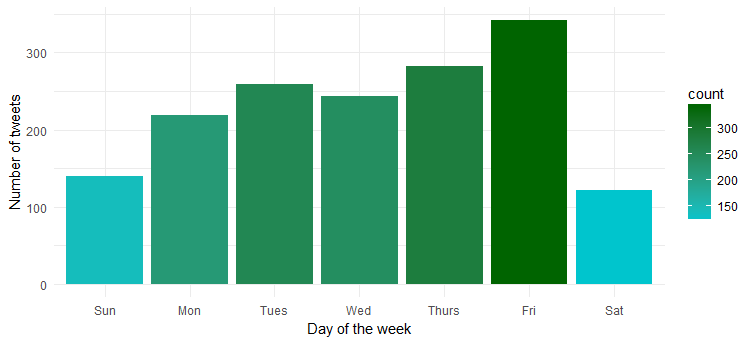
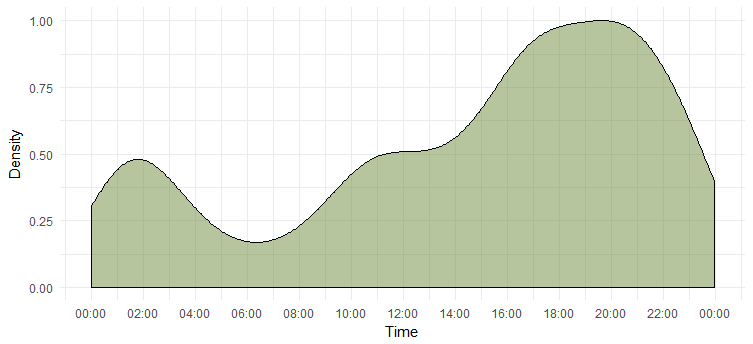
Bir gün boyunca tweet yoğunluğu
En aktif günü bulduk ama en aktif olduğu zamanı bilmiyoruz. Aşağıdaki tablo bize cevabı verecektir.
[kod dili=”r”]
# günün saatini saklamak ve biçimlendirmek için paket
install.packages(“hms”)
# zaman araları ve etiketler eklemek için paket
install.packages(“ölçekler”)
kitaplık ("hms")
kitaplık ("ölçekler")
# Zaman damgasından yalnızca zamanı çıkarın, yani saat, dakika ve saniye
ew_tweets$zaman <- hms::hms(saniye(ew_tweets$created_at),
dakika(ew_tweets$created_at),
saat(ew_tweets$created_at))
# ggplot olarak `POSIXct`e dönüştürme `hms` ile uyumlu değil
ew_tweets$zaman <- as.POSIXct(ew_tweets$zaman)
ggplot(veri = ew_tweets)+
geom_density(aes(x = zaman, y = ..ölçeklendirilmiş..),
dolgu=”darkolivegreen4″, alpha=0,3) +
xlab(“Zaman”) + ylab(“Yoğunluk”) +
scale_x_datetime(breaks = date_breaks(“2 saat”)),
etiketler = date_format(“%H:%M”)) +
tema_minimal()
[/kod]

Bu bize onun en çok akşam 6-8 arası aktif olduğunu söyler. Saat diliminin UTC olduğunu unutmayın ("sınıf dışı" işlevi kullanılarak öğrenilebilir. Emma'yı tweetlerken bunu aklınızda bulundurun.
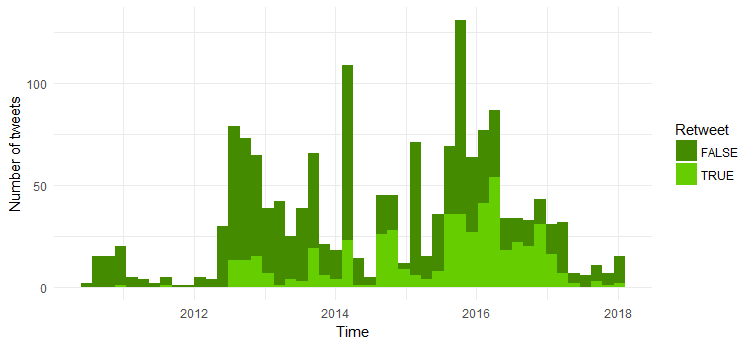
Yeniden tweet ve orijinal tweet sayısının karşılaştırılması
Şimdi orijinal tweet'lerin ve yeniden tweet'lerin sayısını karşılaştıracağız. Aşağıda verilen kod:
[kod dili=”r”]
ggplot(data = ew_tweets, aes(x = create_at, fill = is_retweet)) +
geom_histogram(bins=48) +
xlab(“Zaman”) + ylab(“Tweet sayısı”) + theme_minimal() +
scale_fill_manual(değerler = c(“chartreuse4”, “chartreuse3”)),
isim = “Retweetle”)
[/kod]
Tweetlerin çoğu orijinal tweetlerdir. 2014'ten bu yana retweet sayısının artması ilginç.
Metin Madenciliği
Şimdi daha ilginç bir alana girelim - aşağıdakileri bulmak için NLP dahil metin madenciliği teknikleri uygulayacağız:
1. Sık kullanılan hashtag'ler
2. Tweet metinlerinin kelime bulutu
3. Duygu analizi
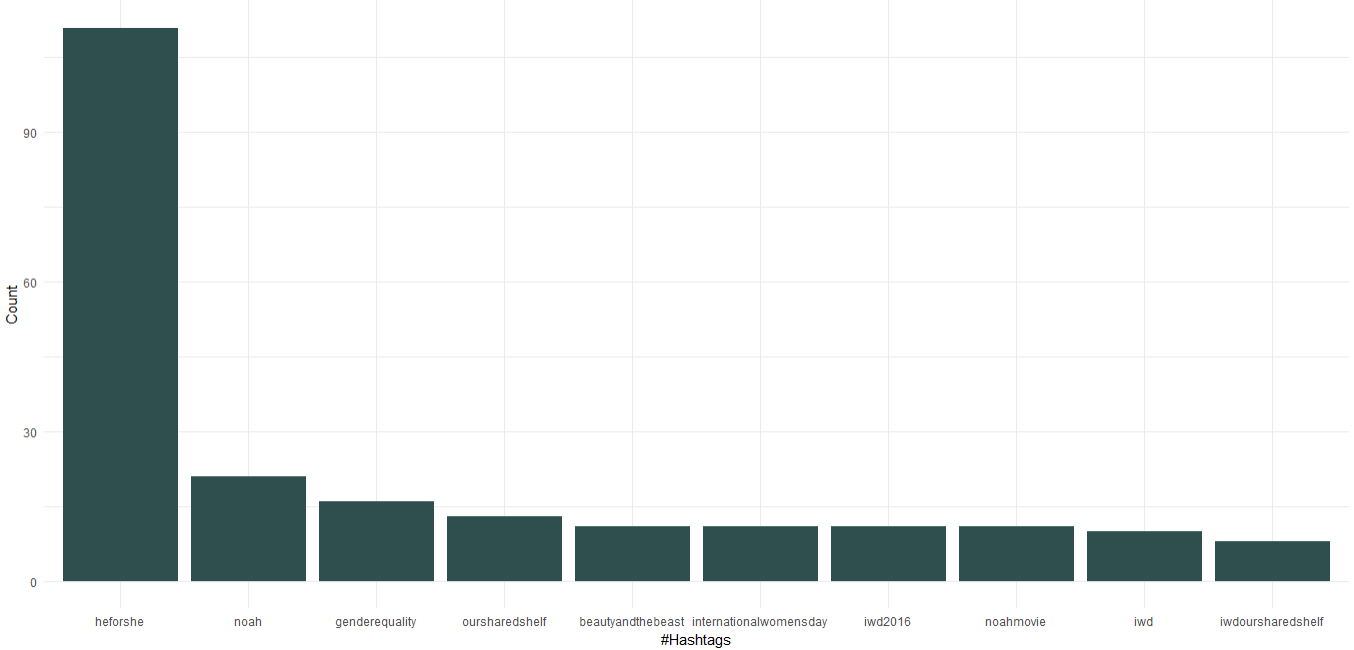
1. Sık kullanılan hashtag'ler
İndirilen veri kümesinde hashtag'leri içeren bir sütun zaten var; Emma tarafından kullanılan en iyi 10 hashtag'i bulmak için bunu kullanacağız. Hashtag'ler için grafiği oluşturan kod aşağıda verilmiştir:
[kod dili=”r”]
# Veri çerçeveleriyle kolayca çalışmak için paket
install.packages(“dplyr”)
kitaplık ("dplyr")
# Listeden hashtag'leri alma
ew_tags_split <- unlist(strsplit(as.character(unlist(ew_tweets$hashtags))),'^c(|,|”|)'))
# Boşlukları kaldırarak biçimlendirme
ew_tags <- sapply(ew_tags_split, function(y) nchar(trimws(y)) > 0 & !is.na(y))
ew_tag_df <- as_data_frame(table(tolower(ew_tags_split[ew_tags])))
ew_tag_df <- ew_tag_df[with(ew_tag_df,order(-n)),]
ew_tag_df <- ew_tag_df[1:10,]
ggplot(ew_tag_df, aes(x = yeniden sırala(Var1, -n), y=n)) +
geom_bar(stat=”kimlik”, fill=”darkslategray”)+
theme_minimal() +
xlab(“#Hashtags”) + ylab(“Sayı”)
[/kod]
Emma Watson'ın BM Kadın İyi Niyet Elçisi olarak toplumsal cinsiyet eşitliğine odaklanan “HeForShe” kampanyasını desteklediğini görüyoruz. Bunun dışında “Ortak Rafımız” ve “Dünya Kadınlar Günü” adlı kitap kulübünün tanıtımını yaptı. Filmlere gelen "Nuh", "Güzel ve Çirkin" ilk 10 hashtag'de yer alıyor.
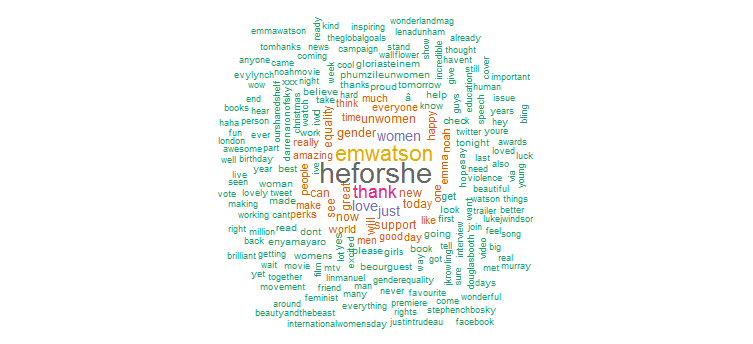
2. Kelime bulutu
Şimdi en sık kullanılan kelimeleri bulmak ve bir kelime bulutu oluşturmak için tweet metnini analiz edeceğiz. Devam etmek için aşağıdaki kodu yürütün:
[kod dili=”r”]
#metin madenciliği ve kelime bulutu paketini kurun
install.packages(c(“tm”, “wordcloud”))
kitaplık ("tm")
kitaplık ("kelime bulutu")
tweet_text <- ew_tweets$metin
#Sayıları, noktalama işaretlerini, bağlantıları ve alfasayısal içeriği kaldırma
tweet_text<- gsub('[[:digit:]]+', ”, tweet_text)
tweet_text<- gsub('[[:punkt:]]+', ”, tweet_text)
tweet_text<- gsub(“http[[:alnum:]]*”, “”, tweet_text)
tweet_text<- gsub(“([[:alpha:]])1+”, “”, tweet_text)
#metin topluluğu oluşturma
dokümanlar <- Corpus(VectorSource(tweet_text))
# komik karakterleri işlemek için kodlamayı UTF-8'e çevirmek
belgeler <- tm_map(belgeler, işlev(x) iconv(enc2utf8(x), alt = “bayt”))
# Metni küçük harfe dönüştürme
dokümanlar <- tm_map(docs, content_transformer(tolower))
# İngilizce ortak kelimelerin kaldırılması
dokümanlar <- tm_map(docs, removeWords, stopwords(“ingilizce”))
# Tarafımızdan karakter vektörü olarak belirtilen stopwords kaldırma
dokümanlar <- tm_map(docs, removeWords, c(“amp”))
# dönem belgesi matrisi oluşturma
tdm <- TermDocumentMatrix(belgeler)
# tdm'yi matris olarak tanımlama
m <- as.matrix(tdm)
# azalan sırayla kelime sayıları alma
word_freqs = sort(rowSums(m), azalan=DOĞRU)
# kelimeler ve frekansları ile bir veri çerçevesi oluşturma
ew_wf <- data.frame(kelime=isimler(kelime_sıklıkları), sıklık=kelime_sıklıkları)
# wordcloud çizimi
set.seed(1234)
wordcloud(kelimeler = ew_wf$kelime, sıklık = ew_wf$sık,
min.freq = 1,ölçek=c(1.8,.5),
max.words=200, random.order=YANLIŞ, rot.per=0.15,
renkler=brewer.pal(8, “Koyu2”))
[/kod]
Açıkça “HeforShe” kampanyası için yoğun bir tanıtım yaptı. Sık kullanılan diğer kelimeler ise “teşekkür”, “sevgi”, “kadınlar”, “cinsiyet” ve “UNWomen”dir. Bu, Twitter etkinliğinin oldukça kadın sorunlarına odaklandığını gösteren hashtag'lerle açıkça uyumludur.
3. Duygu analizi
Duygu çıkarma ve çizim için syuzhet paketini uygulayacağız. Bu paket, farklı sözcükleri çeşitli duygularla (sevinç, korku, öfke, sürpriz vb.) ve duygu kutupluluğuyla (olumlu/olumsuz) eşleştiren duygu sözlüğüne dayanmaktadır. Tweetlerde bulunan kelimelere dayanarak duygu puanını hesaplamamız ve aynısını çizmemiz gerekecek.
[kod dili=”r”]
install.packages(“syuzhet”)
kütüphane(syuzhet)
# Tuhaf karakterleri izlemek için tweet'leri ASCII'ye dönüştürme
tweet_text <- iconv(tweet_text, from=”UTF-8″, to=”ASCII”, sub=””)
# retweetleri kaldırma
tweet_text<-gsub(“(RT|yoluyla)((?:bw*@w+)+)””,tweet_text)
# bahsetmeleri kaldırma
tweet_text<-gsub(“@w+”,””,tweet_text)
ew_sentiment<-get_nrc_sentiment((tweet_text))
duygu puanları<-data.frame(colSums(ew_sentiment[,]))
isimler(sentimentscores) <- “Puan”
duygu puanları <- cbind(“duygu”=satır adları(duygu puanları), duygu puanları)
satır adları(duygu puanları) <- NULL
ggplot(data=sentimentscores,aes(x=sentiment,y=Puan))+
geom_bar(aes(fill=sentiment),stat = “kimlik”)+
tema(legend.position=”yok”)+
xlab(“Duygular”)+ylab(“Puanlar”)+
ggtitle(“Puanlara dayalı toplam duyarlılık”)+
tema_minimal()
[/kod]
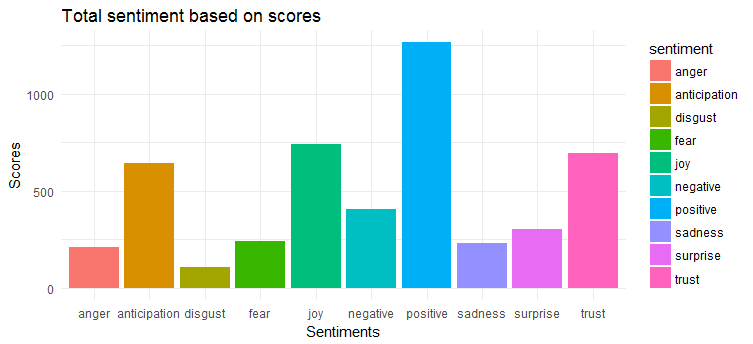
Aşağıdaki grafik, tweet'lerin büyük ölçüde olumlu duygulara sahip olduğunu göstermektedir. En çok ifade edilen ilk üç duygu 'sevinç', 'güven' ve 'beklenti'dir.
Sana doğru
Bu çalışmada, Emma Watson tarafından gönderilen tweet'lerin tweetleme modellerini ve altında yatan temayı anlamak için keşifsel veri analizi ve metin madenciliği tekniklerini ele aldık. Konu modellemesi kullanılarak sık bahsedilen twitter kullanıcısını bulmak, ağ grafiği oluşturmak ve tweetleri sınıflandırmak için daha fazla analiz yapılabilir.
Bu öğreticiyi takip edin ve bulgularınızı yorumlar bölümünde paylaşın.
