
Menambang Tweet Emma Watson dengan R
Diterbitkan: 2018-02-03Aliran Twitter dari setiap orang berisi data sosial yang kaya yang dapat mengungkap banyak hal tentang orang itu. Karena data Twitter bersifat publik dan API terbuka bagi siapa saja untuk digunakan, teknik penambangan data dapat dengan mudah diterapkan untuk mengetahui semuanya, mulai dari pola waktu dan topik yang menjadi fokus orang tersebut hingga pola teks yang digunakan untuk mengekspresikan pandangan dan pemikiran.

Dalam penelitian ini, kami akan menggunakan R untuk melakukan analisis pada tweet yang diposting oleh salah satu selebriti paling terkenal, yaitu Emma Watson. Pertama kita akan melalui analisis eksplorasi dan kemudian pindah ke analisis teks.
Mengekstrak Data Twitter Emma Watson
Twitter API memungkinkan kami mengunduh 3.200 tweet terbaru — yang perlu kami lakukan hanyalah membuat aplikasi Twitter untuk mendapatkan kunci API dan token akses. Ikuti langkah-langkah yang diberikan di bawah ini untuk membuat aplikasi:
- Buka https://apps.twitter.com
- Klik 'Buat Aplikasi Baru'
- Masukkan detailnya dan klik 'Buat aplikasi Twitter Anda'
- Klik pada tab 'Kunci dan Token Akses' dan salin kunci dan rahasia API
- Gulir ke bawah dan klik "Buat token akses saya"
Ada perpustakaan R yang disebut rtweet yang akan digunakan untuk mengunduh tweet dan membuat bingkai data. Gunakan kode yang diberikan di bawah ini untuk melanjutkan:
[bahasa kode="r"]
install.packages("httr")
install.packages(“rtweet”)
perpustakaan("httr")
perpustakaan("rtweet")
# nama aplikasi twitter yang Anda buat
nama aplikasi <- “tweet-analytics”
# kunci api (ganti contoh berikut dengan kunci Anda)
kunci <- “8YnCioFqKFaebTwjoQfcVLPS”
# api secret (ganti yang berikut dengan rahasia Anda)
rahasia <- “uSzkAOXnNpSDsaDAaDDDSddsA6Cukfds8a3tRtSG”
# buat token bernama “twitter_token”
twitter_token <- buat_token(
aplikasi = nama aplikasi,
konsumen_key = kunci,
rahasia_konsumen = rahasia)
#Mengunduh tweet yang diposting oleh Emma Watson
ew_tweets <- get_timeline(“EmmaWatson”, n = 3200)
[/kode]
Analisis eksplorasi
Di sini kita akan meringkas dataset dengan memvisualisasikan hal berikut:
- Jumlah tweet yang diposting dari 2010 hingga 2018
- Frekuensi tweet selama berbulan-bulan
- Frekuensi tweet selama seminggu
- Kepadatan tweet sepanjang hari
- Perbandingan jumlah tweet ulang dan tweet asli
Tweet dari tahun ke tahun
Kami akan menggunakan ggplot2 yang menakjubkan dan lubridate perpustakaan untuk memplot bagan dan bekerja dengan tanggal. Silakan dan ikuti kode yang diberikan di bawah ini untuk menginstal dan memuat paket:
[bahasa kode="r"]
install.packages("ggplot2")
install.packages("melumasi")
perpustakaan("ggplot2")
perpustakaan("melumasi")
[/kode]
Jalankan kode berikut untuk memplot jumlah tweet selama bertahun-tahun dengan membaginya menjadi beberapa bulan:
[bahasa kode="r"]
ggplot(data = ew_tweets,
aes(bulan(dibuat_at, label=TRUE, abbr=TRUE),
grup=faktor(tahun(dibuat_at)), warna=faktor(tahun(dibuat_at))))+
geom_line(stat="hitung") +
geom_point(stat="hitung") +
labs(x=”Bulan”, color=”Tahun”) +
xlab(“Bulan”) + ylab(“Jumlah tweet”) +
tema_minimal()
[/kode]
Hasilnya adalah grafik berikut:
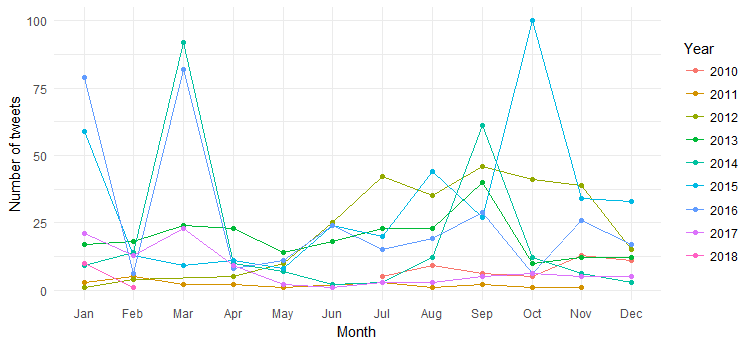
Kita dapat melihat pecahnya tweet bulanan (lonjakan pada Maret 2014, Maret 2016 dan Oktober 2015) selama bertahun-tahun, tetapi interpretasinya sulit. Sekarang mari kita sederhanakan bagan dengan hanya memplot jumlah tweet berdasarkan tahun.
[bahasa kode="r"]
ggplot(data = ew_tweets, aes(x = tahun(dibuat_at))) +
geom_bar(aes(isi = ..hitung..)) +
xlab(“Tahun”) + ylab(“Jumlah tweet”) +
scale_x_continuous (breaks = c(2010:2018)) +
tema_minimal() +
scale_fill_gradient(rendah = “cadetblue3”, tinggi = “chartreuse4”)
[/kode]
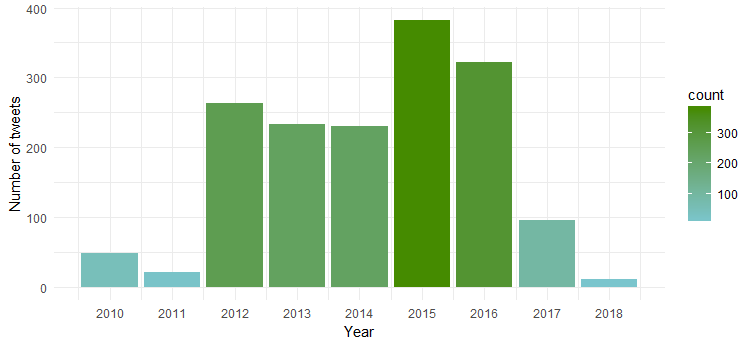
Grafik yang dihasilkan menunjukkan bahwa dia paling aktif pada tahun 2015 dan 2016 sementara tahun 2011 menunjukkan aktivitas paling sedikit.
Frekuensi tweet selama berbulan-bulan
Sekarang mari kita cari tahu di Data Twitter Emma Watson untuk melihat apakah dia men-tweet secara merata selama bulan-bulan dalam setahun atau ada bulan-bulan tertentu di mana dia paling banyak men-tweet. Gunakan kode berikut untuk membuat grafik:
[bahasa kode="r"]
ggplot(data = ew_tweets, aes(x = bulan(dibuat_at, label = BENAR))) +
geom_bar(aes(isi = ..hitung..)) +
xlab(“Bulan”) + ylab(“Jumlah tweet”) +
tema_minimal() +
scale_fill_gradient(rendah = “cadetblue3”, tinggi = “chartreuse4”)
[/kode]
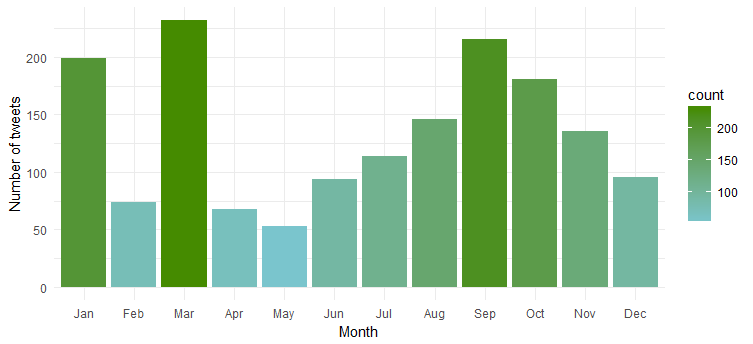
Jelas dia paling aktif selama 'Januari', 'Maret' dan 'September'.
Frekuensi tweet selama seminggu
Apakah ada hari tertentu dalam seminggu di mana dia paling aktif? Mari kita plot grafik dengan mengeksekusi kode berikut:
[bahasa kode="r"]
ggplot(data = ew_tweets, aes(x = wday(dibuat_at, label = TRUE))) +
geom_bar(aes(isi = ..hitung..)) +
xlab("Hari dalam seminggu") + ylab("Jumlah tweet") +
tema_minimal() +
scale_fill_gradient(rendah = “turquoise3”, tinggi = “hijau tua”)
[/kode]
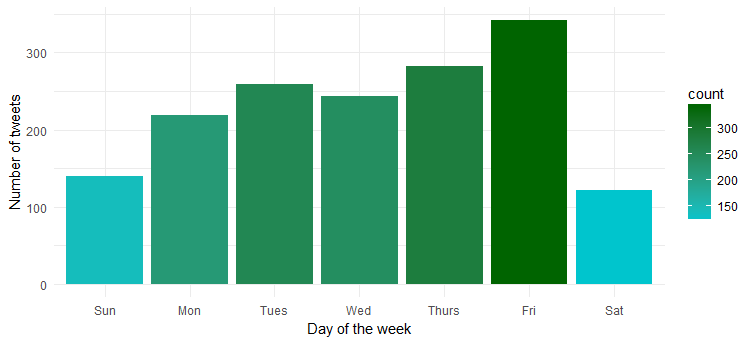
Hmm…dia paling aktif di hari Jumat. Mungkin bersiap-siap untuk masuk ke mode pesta?
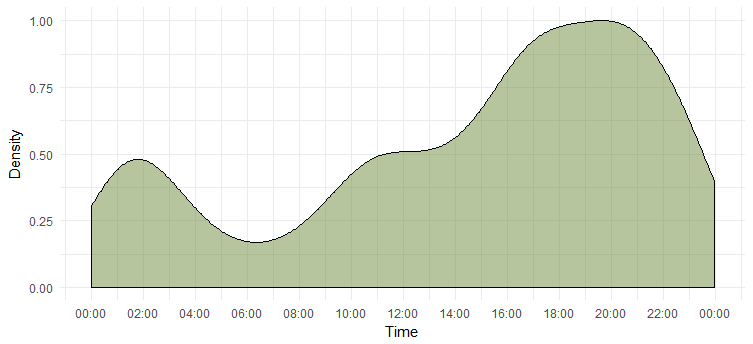
Kepadatan tweet sepanjang hari
Kami telah menemukan hari yang paling aktif, tetapi kami tidak tahu jam di mana dia paling aktif. Bagan berikut akan memberi kita jawabannya.
[bahasa kode="r"]
# paket untuk menyimpan dan memformat waktu hari ini
install.packages("hms")
# paket untuk menambahkan jeda waktu dan label
install.packages("skala")
perpustakaan("hms")
perpustakaan("skala")
# Ekstrak hanya waktu dari stempel waktu, yaitu jam, menit, dan detik
ew_tweets$waktu <- hms::hms(second(ew_tweets$created_at),
menit(ew_tweets$created_at),
jam(ew_tweets$created_at))
# Mengonversi ke `POSIXct` karena ggplot tidak kompatibel dengan `hms`
ew_tweets$waktu <- as.POSIXct(ew_tweets$waktu)
ggplot(data = ew_tweets)+
geom_density(aes(x = waktu, y = ..skala..),
isi="darkolivegreen4″, alfa=0,3) +
xlab("Waktu") + ylab("Kerapatan") +
scale_x_datetime(breaks = date_breaks(“2 jam”),
labels = date_format(“%H:%M”)) +
tema_minimal()
[/kode]

Ini memberitahu kita bahwa dia paling aktif selama 6-8 malam Perhatikan bahwa zona waktunya adalah UTC (dapat ditemukan menggunakan fungsi `unclass`. Ingatlah hal ini saat menge-tweet Emma.
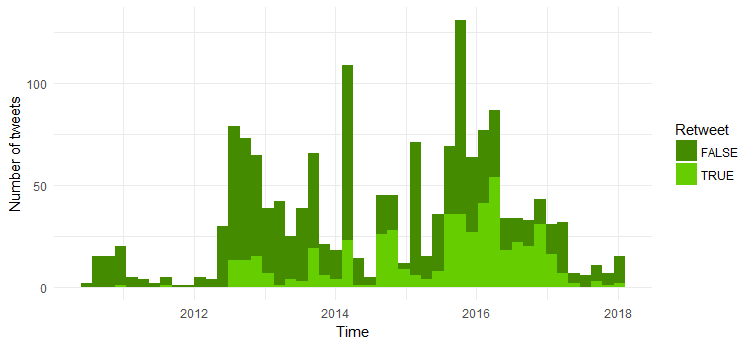
Perbandingan jumlah tweet ulang dan tweet asli
Sekarang kita akan membandingkan jumlah tweet asli dan tweet ulang. Diberikan di bawah ini adalah kode:
[bahasa kode="r"]
ggplot(data = ew_tweets, aes(x = create_at, isi = is_retweet)) +
geom_histogram(tempat sampah=48) +
xlab(“Waktu”) + ylab(“Jumlah tweet”) + theme_minimal() +
scale_fill_manual(nilai = c(“chartreuse4”, “chartreuse3”),
nama = “Retweet”)
[/kode]
Mayoritas tweet adalah tweet asli. Menarik untuk melihat bahwa jumlah re-tweet meningkat dari tahun 2014.
Penambangan Teks
Sekarang mari masuk ke area yang lebih menarik — kita akan melakukan teknik text mining termasuk NLP untuk mengetahui hal berikut:
1. Hashtag yang sering digunakan
2. Awan kata dari teks tweet
3. Analisis sentimen
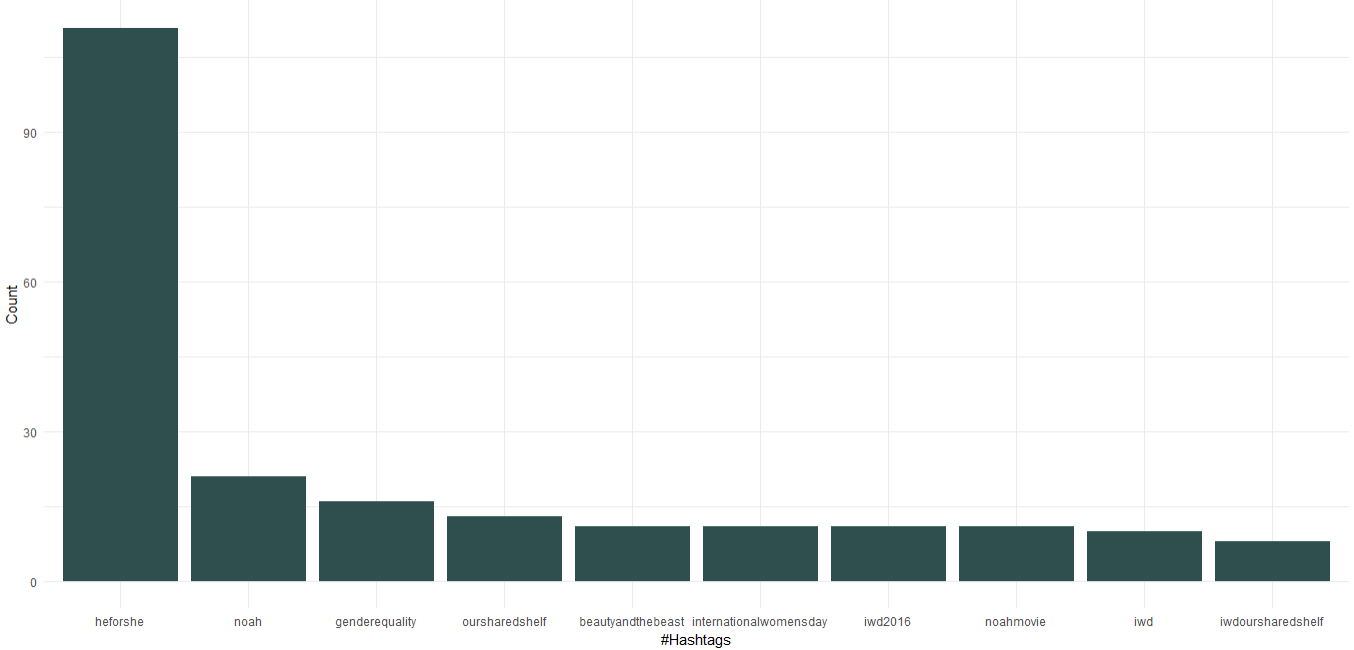
1. Hashtag yang sering digunakan
Dataset yang diunduh sudah memiliki kolom yang berisi hashtag; kami akan menggunakannya untuk mengetahui 10 tagar teratas yang digunakan oleh Emma. Diberikan di bawah ini adalah kode untuk membuat bagan untuk tagar:
[bahasa kode="r"]
# Paket untuk bekerja dengan mudah dengan bingkai data
install.packages("dplyr")
perpustakaan("dplr")
# Mendapatkan tagar dari daftar
ew_tags_split <- unlist(strsplit(as.character(unlist(ew_tweets$hashtags)),'^c(|,|”|)'))
# Memformat dengan menghapus spasia
ew_tags <- sapply(ew_tags_split, function(y) nchar(trimws(y)) > 0 & !is.na(y))
ew_tag_df <- sebagai_data_frame(tabel(tolower(ew_tags_split[ew_tags])))
ew_tag_df <- ew_tag_df[dengan(ew_tag_df,pesan(-n)),]
ew_tag_df <- ew_tag_df[1:10,]
ggplot(ew_tag_df, aes(x = menyusun ulang(Var1, -n), y=n)) +
geom_bar(stat=”identity”, fill=”darkslategray”)+
tema_minimal() +
xlab("#Hashtag") + ylab("Hitung")
[/kode]
Kita dapat melihat bahwa sebagai Duta Niat Baik Wanita PBB, Emma Watson telah mempromosikan kampanye “HeForShe” yang berfokus pada kesetaraan gender. Selain itu, ia juga mempromosikan klub bukunya yang disebut “Rak Bersama Kami” dan “Hari Perempuan Internasional”. Datang ke bioskop, “Noah”, “Beauty and the Beast” masuk dalam 10 tagar teratas.
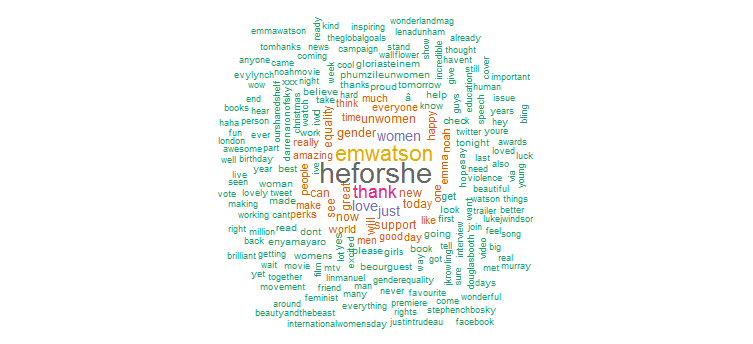
2. Awan kata
Sekarang kita akan menganalisis teks tweet untuk mengetahui kata-kata yang paling sering dan membuat cloud kata. Jalankan kode berikut untuk melanjutkan:
[bahasa kode="r"]
#instal paket penambangan teks dan cloud kata
install.packages(c("tm", "wordcloud"))
perpustakaan("tm")
perpustakaan("wordcloud")
tweet_text <- ew_tweets$teks
#Menghapus nomor, tanda baca, tautan, dan konten alfanumerik
tweet_text<- gsub('[[:digit:]]+', ”, tweet_text)
tweet_text<- gsub('[[:punct:]]+', ”, tweet_text)
tweet_text<- gsub(“http[[:alnum:]]*”, “”, tweet_text)
tweet_text<- gsub(“([[:alpha:]])1+”, “”, tweet_text)
#membuat korpus teks
dokumen <- Corpus(Sumber Vektor(teks_tweet))
# menutupi pengkodean ke UTF-8 untuk menangani karakter lucu
dokumen <- tm_map(docs, function(x) iconv(enc2utf8(x), sub = “byte”))
# Mengubah teks menjadi huruf kecil
dokumen <- tm_map(docs, content_transformer(tolower))
# Menghapus stopword umum bahasa Inggris
docs <- tm_map(docs, removeWords, stopwords(“english”))
# Menghapus stopword yang kami tentukan sebagai vektor karakter
docs <- tm_map(docs, removeWords, c(“amp”))
# membuat matriks dokumen istilah
tdm <- TermDocumentMatrix(docs)
# mendefinisikan tdm sebagai matriks
m <- sebagai.matriks(tdm)
# mendapatkan jumlah kata dalam urutan menurun
word_freqs = sort(rowSums(m), menurun=TRUE)
# membuat bingkai data dengan kata-kata dan frekuensinya
ew_wf <- data.frame(word=names(word_freqs), freq=word_freqs)
# merencanakan wordcloud
set.seed(1234)
wordcloud(kata = ew_wf$kata, frekuensi = ew_wf$frekuensi,
min.freq = 1,skala=c(1.8,.5),
max.words=200, random.order=FALSE, rot.per=0.15,
warna=brewer.pal(8, “Dark2”))
[/kode]
Jelas dia telah melakukan promosi besar-besaran untuk kampanye "HeforShe". Kata-kata lain yang sering digunakan adalah “terima kasih”, “cinta”, “wanita”, “gender” dan “UNWomen”. Hal ini jelas sejalan dengan hastag yang menunjukkan bahwa aktivitas Twitter-nya cukup terfokus pada isu-isu perempuan.
3. Analisis sentimen
Untuk ekstraksi dan plot sentimen, kami akan menerapkan paket syuzhet . Paket ini didasarkan pada leksikon emosi yang memetakan kata-kata yang berbeda dengan berbagai emosi (gembira, takut, marah, terkejut, dll) dan polaritas sentimen (positif/negatif). Kita harus menghitung skor emosi berdasarkan kata-kata yang ada di tweet dan plot yang sama.
[bahasa kode="r"]
install.packages("syuzhet")
perpustakaan (syuzhet)
# Mengonversi tweet ke ASCII untuk melacak karakter aneh
tweet_text <- iconv(tweet_text, from=”UTF-8″, to=”ASCII”, sub=””)
# menghapus retweet
tweet_text<-gsub(“(RT|via)((?:bw*@w+)+)”,””,tweet_text)
# menghapus sebutan
tweet_text<-gsub(“@w+”,””,tweet_text)
ew_sentiment<-get_nrc_sentiment((tweet_text))
skor sentimen<-data.frame(colSums(ew_sentiment[,]))
nama(skor sentimen) <- “Skor”
sentimenscores <- cbind(“sentiment”=rownames(sentimentscores),sentimentscores)
nama baris(sentimentscores) <- NULL
ggplot(data=nilai sentimen,aes(x=sentimen,y=nilai))+
geom_bar(aes(isi=sentimen),stat = “identitas”)+
tema(legend.position="none")+
xlab(“Sentimen”)+ylab(“Skor”)+
ggtitle(“Total sentimen berdasarkan skor”)+
tema_minimal()
[/kode]
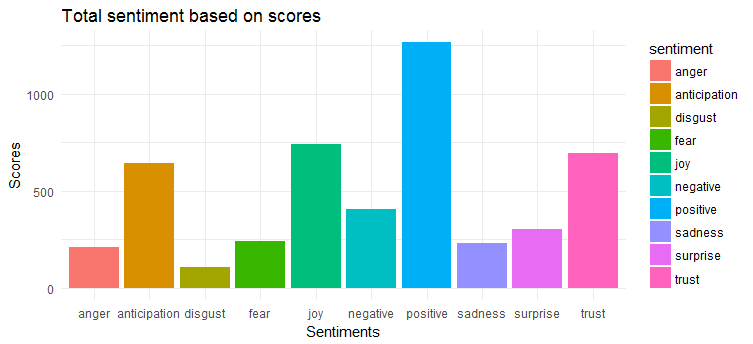
Grafik berikut menunjukkan bahwa tweet sebagian besar memiliki sentimen positif. Tiga emosi teratas yang paling banyak diungkapkan adalah 'kegembiraan', 'kepercayaan', dan 'antisipasi'.
Ke Anda
Dalam studi ini kami membahas analisis data eksplorasi dan teknik penambangan teks untuk memahami pola tweeting dan tema yang mendasari tweet yang diposting oleh Emma Watson. Analisis lebih lanjut dapat dilakukan untuk mengetahui pengguna twitter yang sering disebut, membuat grafik jaringan dan mengklasifikasikan tweet dengan menggunakan pemodelan topik.
Ikuti tutorial ini dan bagikan temuan Anda di bagian komentar.
