
Explorând tweeturile lui Emma Watson cu R
Publicat: 2018-02-03Fluxul Twitter al oricărei persoane conține date sociale bogate care pot dezvălui multe despre acea persoană. Deoarece datele Twitter sunt publice și API-ul poate fi folosit oricui, tehnicile de extragere a datelor pot fi aplicate cu ușurință pentru a afla totul, de la tiparele de sincronizare și subiectele pe care persoana se concentrează până la tiparele de text utilizate pentru a exprima opinii și gânduri.

În acest studiu, vom folosi R pentru a efectua analize pe tweet-urile postate de una dintre cele mai cunoscute celebrități, adică Emma Watson. Mai întâi vom trece prin analiza exploratorie și apoi vom trece la analiza textului.
Extragerea datelor de pe Twitter ale Emma Watson
Twitter API ne permite să descarcăm 3.200 de tweet-uri recente — tot ce trebuie să facem este să creăm o aplicație Twitter pentru a obține cheia API și tokenul de acces. Urmați pașii de mai jos pentru a crea aplicația:
- Deschideți https://apps.twitter.com
- Faceți clic pe „Creați o nouă aplicație”
- Introduceți detaliile și faceți clic pe „Creați-vă aplicația Twitter”
- Faceți clic pe fila „Chei și jetoane de acces” și copiați cheia API și secretul
- Derulați în jos și faceți clic pe „Creați simbolul meu de acces”
Există o bibliotecă R numită rtweet care va fi folosită pentru a descărca tweet-urile și a crea un cadru de date. Utilizați codul de mai jos pentru a continua:
[limba codului=”r”]
install.packages(„httr”)
install.packages(„rtweet”)
bibliotecă ("httr")
bibliotecă ("rtweet")
# numele aplicației Twitter creată de tine
appname <- „analitica-tweet”
# cheie api (înlocuiți următorul exemplu cu cheia dvs.)
tasta <- „8YnCioFqKFaebTwjoQfcVLPS”
# secret API (înlocuiește următorul secret cu secretul tău)
secret <- „uSzkAOXnNpSDsaDAaDDDSddsA6Cukfds8a3tRtSG”
# creați un token numit „twitter_token”
twitter_token <- create_token(
aplicație = nume aplicație,
consumer_key = cheie,
consumer_secret = secret)
#Descărcarea tweet-urilor postate de Emma Watson
ew_tweets <- get_timeline(„EmmaWatson”, n = 3200)
[/cod]
Analiza exploratorie
Aici vom rezuma setul de date vizualizând următoarele:
- Numărul de tweet-uri postate din 2010 până în 2018
- Frecvența de tweet de-a lungul lunilor
- Frecvența de tweet pe o săptămână
- Densitatea tweetului pe o zi
- Comparație între numărul de re-tweet-uri și tweet-uri originale
Tweeturi în funcție de an
Vom folosi uimitoarea bibliotecă ggplot2 și lubridate pentru a trasa diagrame și a lucra cu datele. Continuați și urmați codul de mai jos pentru a instala și încărca pachetele:
[limba codului=”r”]
install.packages(„ggplot2”)
install.packages(„lubridare”)
bibliotecă ("ggplot2")
bibliotecă ("lubridare")
[/cod]
Executați următorul cod pentru a reprezenta numărul de tweet-uri de-a lungul anilor, împărțind în luni:
[limba codului=”r”]
ggplot(data = ew_tweets,
aes(lună(created_at, label=TRUE, abbr=TRUE),
grup=factor(an(created_at)), culoare=factor(an(created_at))))+
geom_line(stat="count") +
geom_point(stat="count") +
labs(x=”Lună”, culoare=”An”) +
xlab(„Lună”) + ylab(„Numărul de tweet-uri”) +
theme_minimal()
[/cod]
Rezultatul este următorul grafic:
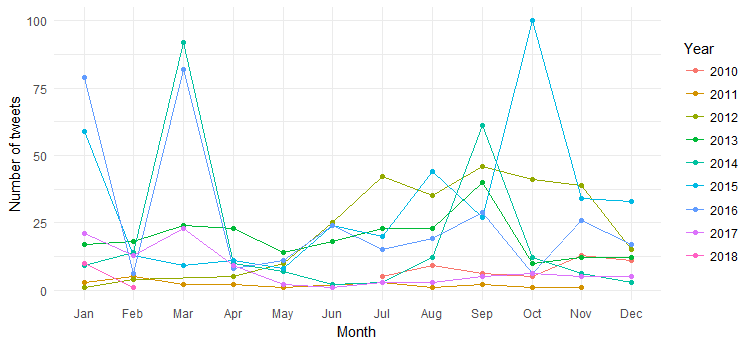
Putem vedea ruptura tweet-urilor lunare (puncte în martie 2014, martie 2016 și octombrie 2015) de-a lungul anilor, dar interpretarea este dificilă. Haideți acum să simplificăm graficul prin trasarea numai a numărului de tweet-uri pe an.
[limba codului=”r”]
ggplot(date = ew_tweets, aes(x = year(created_at))) +
geom_bar(aes(fill = ..count..)) +
xlab(„Anul”) + ylab(„Numărul de tweet-uri”) +
scară_x_continuă (pauze = c(2010:2018)) +
theme_minimal() +
scale_fill_gradient(jos = „cadetblue3”, mare = „chartreuse4”)
[/cod]
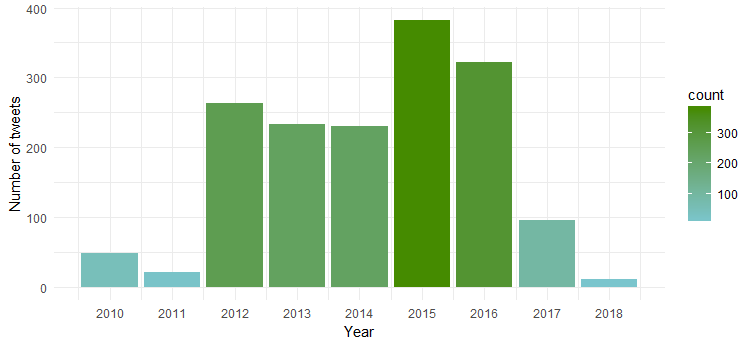
Graficul rezultat arată că ea a fost cea mai activă în 2015 și 2016, în timp ce 2011 a fost martor la cea mai mică activitate.
Frecvența de tweet de-a lungul lunilor
Să aflăm acum în Emma Watson Twitter Data pentru a vedea dacă tweetează în mod egal pe parcursul lunilor unui an sau există anumite luni în care tweetează cel mai mult. Utilizați următorul cod pentru a crea diagrama:
[limba codului=”r”]
ggplot(date = ew_tweets, aes(x = luna(created_at, label = TRUE))) +
geom_bar(aes(fill = ..count..)) +
xlab(„Lună”) + ylab(„Numărul de tweet-uri”) +
theme_minimal() +
scale_fill_gradient(jos = „cadetblue3”, mare = „chartreuse4”)
[/cod]
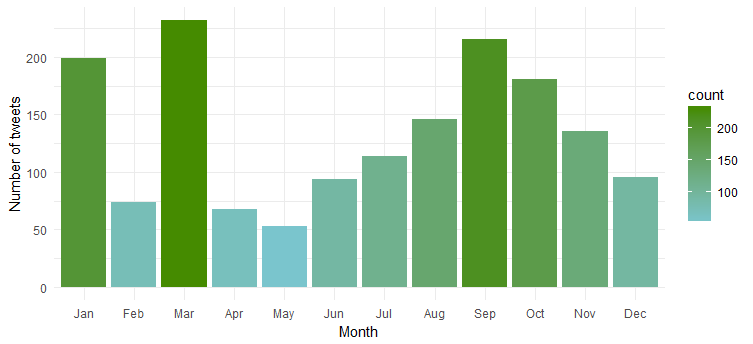
În mod clar, ea este cea mai activă în „ianuarie”, „martie” și „septembrie”.
Frecvența de tweet pe o săptămână
Există vreo zi anume a săptămânii în care este cea mai activă? Să trasăm graficul executând următorul cod:
[limba codului=”r”]
ggplot(date = ew_tweets, aes(x = wday(created_at, label = TRUE))) +
geom_bar(aes(fill = ..count..)) +
xlab(„Ziua săptămânii”) + ylab(„Numărul de tweet-uri”) +
theme_minimal() +
scale_fill_gradient(jos = „turcoaz3”, mare = „verde închis”)
[/cod]
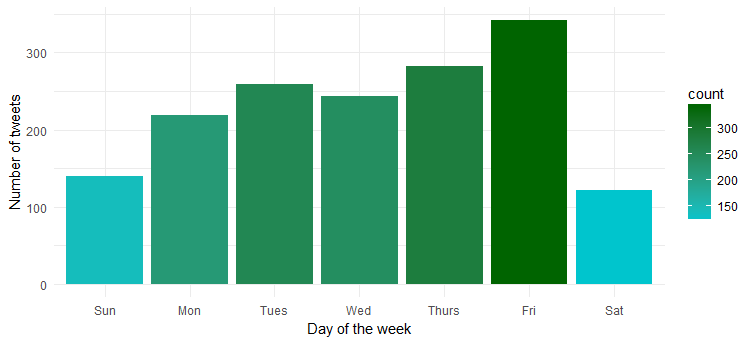
Hmm... ea este cea mai activă vineri. Probabil că te pregătești să intri în modul petrecere?
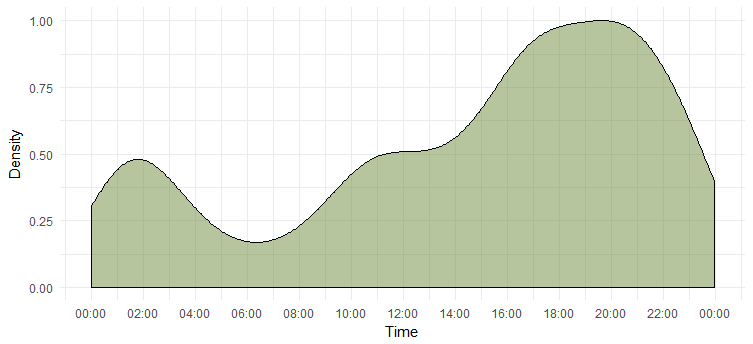
Densitatea tweetului pe o zi
Ne-am dat seama care este cea mai activă zi, dar nu știm la care ea este cea mai activă. Următorul grafic ne va oferi răspunsul.
[limba codului=”r”]
# pachet pentru a stoca și a formata ora din zi
install.packages(„hms”)
# pachet pentru a adăuga pauze și etichete
install.packages(„scale”)
bibliotecă ("hms")
bibliotecă ("cântare")
# Extrageți numai timpul din marcajul de timp, adică oră, minut și secundă
ew_tweets$time <- hms::hms(al doilea(ew_tweets$created_at),
minute(ew_tweets$created_at),
oră(ew_tweets$created_at))
# Convertirea în `POSIXct` ca ggplot nu este compatibilă cu `hms`
ew_tweets$time <- as.POSIXct(ew_tweets$time)
ggplot(data = ew_tweets)+
geom_density(aes(x = timp, y = ..scaled..),
umplere=”darkolivegreen4″, alfa=0,3) +
xlab ("Timp") + ylab ("Densitate") +
scale_x_datetime(breaks = date_breaks(„2 ore”),
etichete = data_format ("%H:%M") +
theme_minimal()
[/cod]

Acest lucru ne spune că ea este cea mai activă în intervalul 6-8 pm. Rețineți că fusul orar este UTC (poate fi găsit folosind funcția `unclass`. Țineți cont de acest lucru când scrieți pe Twitter pe Emma.
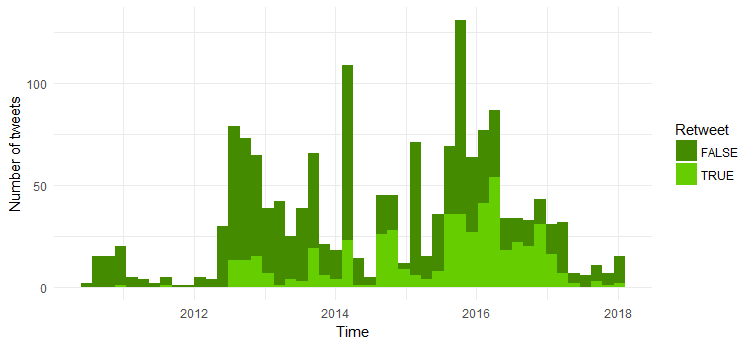
Comparație între numărul de re-tweet-uri și tweet-uri originale
Acum vom compara numărul de tweet-uri originale și re-tweet-uri. Mai jos este codul:
[limba codului=”r”]
ggplot(date = ew_tweets, aes(x = created_at, fill = is_retweet)) +
geom_histogram(bins=48) +
xlab(„Timp”) + ylab(„Numărul de tweet-uri”) + theme_minimal() +
scale_fill_manual(valori = c(„chartreuse4”, „chartreuse3”),
nume = „Retweet”)
[/cod]
Majoritatea tweet-urilor sunt tweet-uri originale. Este interesant de observat că numărul de retweet-uri a crescut din 2014.
Text Mining
Să intrăm acum într-o zonă mai interesantă - vom efectua tehnici de extragere a textului, inclusiv NLP, pentru a afla următoarele:
1. Hashtag-uri utilizate frecvent
2. Norul de cuvinte al textelor tweet
3. Analiza sentimentelor
1. Hashtag-uri utilizate frecvent
Setul de date descărcat are deja o coloană care conține hashtag-uri; îl vom folosi pentru a afla primele 10 hashtag-uri folosite de Emma. Mai jos este codul pentru a crea diagrama pentru hashtag-uri:
[limba codului=”r”]
# Pachet pentru a lucra cu ușurință cu cadre de date
install.packages(„dplyr”)
bibliotecă ("dplyr")
# Obținerea hashtag-urilor din listă
ew_tags_split <- unlist(strsplit(as.character(unlist(ew_tweets$hashtags)),'^c(|,|”|)'))
# Formatarea prin eliminarea spațiului alba
ew_tags <- sapply(ew_tags_split, function(y) nchar(trimws(y)) > 0 & !is.na(y))
ew_tag_df <- as_data_frame(tabel(în jos(ew_tags_split[ew_tags])))
ew_tag_df <- ew_tag_df[cu(ew_tag_df,ordine(-n)),]
ew_tag_df <- ew_tag_df[1:10,]
ggplot(ew_tag_df, aes(x = reorder(Var1, -n), y=n)) +
geom_bar(stat=”identitate”, umplere=”darkslategray”)+
theme_minimal() +
xlab ("#Hashtags") + ylab ("Număr")
[/cod]
Putem vedea că, în calitate de Ambasador al Bunăvoinței ONU Femei, Emma Watson a promovat campania „HeForShe” care se concentrează pe egalitatea de gen. În afară de asta, și-a promovat clubul de carte numit „Raftul nostru comun” și „Ziua internațională a femeii”. Venind la filme, „Noe”, „Frumoasa și Bestia” figurează în primele 10 hashtag-uri.
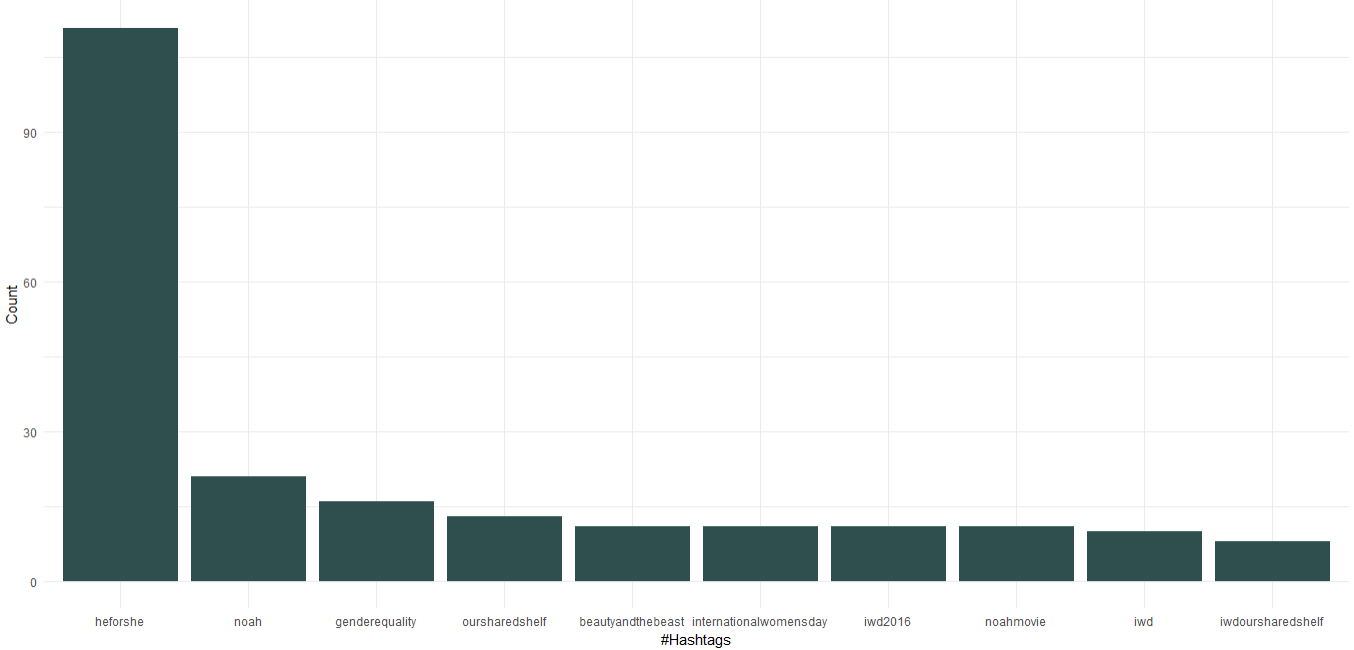
2. Nor de cuvinte
Acum vom analiza textul tweet-ului pentru a afla cele mai frecvente cuvinte și vom crea un nor de cuvinte. Executați următorul cod pentru a continua:
[limba codului=”r”]
#install text mining și pachet de word cloud
install.packages(c(„tm”, „wordcloud”))
bibliotecă ("tm")
bibliotecă ("wordcloud")
tweet_text <- ew_tweets$text
#Eliminarea numerelor, punctajelor, legăturilor și conținutului alfanumeric
tweet_text<- gsub('[[:digit:]]+', ”, tweet_text)
tweet_text<- gsub('[[:punct:]]+', ”, tweet_text)
tweet_text<- gsub(„http[[:alnum:]]*”, „”, tweet_text)
tweet_text<- gsub(„([[:alpha:]])1+”, „”, tweet_text)
#crearea unui corpus de text
documente <- Corpus(VectorSource(tweet_text))
# acoperirea codării în UTF-8 pentru a gestiona caractere amuzante
docs <- tm_map(docs, function(x) iconv(enc2utf8(x), sub = „octet”))
# Convertirea textului în minuscule
docs <- tm_map(docs, content_transformer(tolower))
# Eliminarea cuvintelor oprite comune în engleză
docs <- tm_map(docs, removeWords, stopwords(„engleză”))
# Eliminarea cuvintelor oprite specificate de noi ca vector de caractere
docs <- tm_map(docs, removeWords, c(„amp”))
# crearea matricei de documente pe termene
tdm <- TermDocumentMatrix(docs)
# definirea tdm ca matrice
m <- as.matrix(tdm)
# obținerea numărului de cuvinte în ordine descrescătoare
frecvențe_cuvinte = sortare (sume rânduri (m), descrescătoare = ADEVĂRAT)
# crearea unui cadru de date cu cuvinte și frecvențele acestora
ew_wf <- data.frame(word=names(word_freqs), freq=word_freqs)
# complot wordcloud
set.seed(1234)
wordcloud(cuvinte = ew_wf$cuvânt, frecvență = ew_wf$frecvență,
min.freq = 1,scale=c(1.8,.5),
max.words=200, random.order=FALSE, rot.per=0,15,
colors=brewer.pal(8, „Dark2”))
[/cod]
În mod clar, a făcut o promovare puternică pentru campania „HeforShe”. Alte cuvinte folosite frecvent sunt „mulțumesc”, „dragoste”, „femei”, „sex” și „UNFemei”. Acest lucru este în mod clar în concordanță cu hashtag-urile care sugerează că activitatea ei pe Twitter este destul de concentrată pe problemele femeilor.
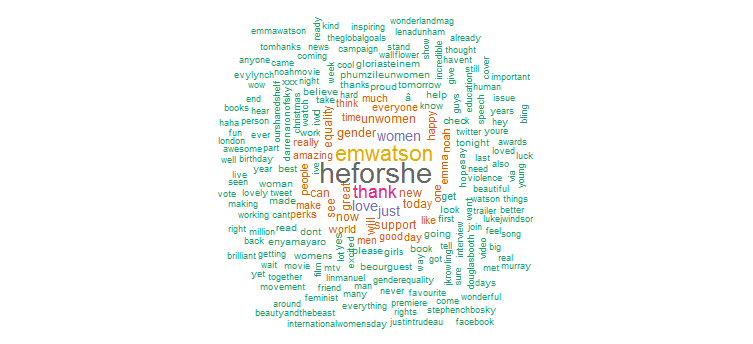
3. Analiza sentimentelor
Pentru extragerea sentimentelor și reprezentarea grafică, vom aplica pachetul syuzhet . Acest pachet se bazează pe lexiconul emoțiilor care mapează diferite cuvinte cu diverse emoții (bucurie, frică, furie, surpriză etc.) și polaritatea sentimentelor (pozitiv/negativ). Va trebui să calculăm scorul de emoție pe baza cuvintelor prezente în tweet-uri și să diagramăm același lucru.
[limba codului=”r”]
install.packages(„syuzhet”)
bibliotecă (syuzhet)
# Convertirea tweet-urilor în ASCII pentru a urmări caractere ciudate
tweet_text <- iconv(tweet_text, from=”UTF-8″, to=”ASCII”, sub="”)
# se elimină retweeturile
tweet_text<-gsub ("(RT|via)((?:bw*@w+)+)”,””,tweet_text)
# eliminând mențiuni
tweet_text<-gsub(„@w+”,””,tweet_text)
ew_sentiment<-get_nrc_sentiment((tweet_text))
sentimentscores<-data.frame(colSums(ew_sentiment[,]))
nume(scoruri sentimente) <- „Scor”
sentimentscores <- cbind(“sentiment”=rownames(sentimentscores),sentimentscores)
rownames(sentimentscores) <- NULL
ggplot(data=sentimentscores,aes(x=sentiment,y=Score))+
geom_bar(aes(fill=sentiment),stat = „identitate”)+
theme(legend.position=”none”)+
xlab(„Sentimente”)+ylab(„Scoruri”)+
ggtitle(„Sentiment total bazat pe scoruri”)+
theme_minimal()
[/cod]
Următorul grafic arată că tweet-urile au un sentiment în mare măsură pozitiv. Primele trei emoții cele mai exprimate sunt „bucuria”, „încrederea” și „anticiparea”.
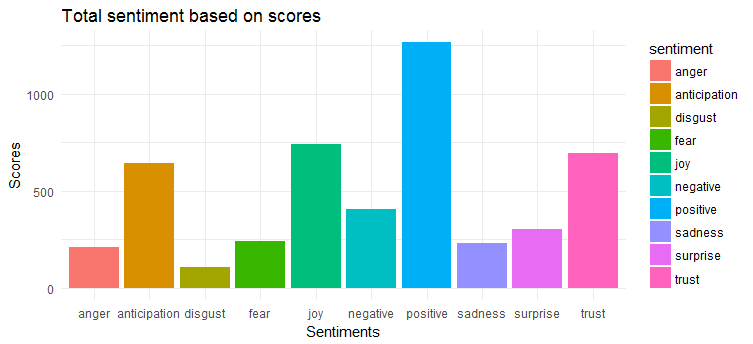
Este randul tau
În acest studiu am acoperit analiza exploratorie a datelor și tehnicile de extragere a textului pentru a înțelege tiparele de tweeting și tema de bază a tweet-urilor postate de Emma Watson. O analiză ulterioară poate fi efectuată pentru a afla utilizatorul twitter frecvent menționat, pentru a crea un grafic de rețea și pentru a clasifica tweet-urile folosind modelarea subiectelor.
Urmați acest tutorial și împărtășiți-vă descoperirile în secțiunea de comentarii.
