
Minería de los tweets de Emma Watson con R
Publicado: 2018-02-03El flujo de Twitter de cualquier persona contiene abundante información social que puede revelar mucho sobre esa persona. Dado que los datos de Twitter son públicos y la API está abierta para que cualquiera la use, las técnicas de extracción de datos se pueden aplicar fácilmente para descubrir todo, desde los patrones de tiempo y los temas en los que se enfoca la persona hasta los patrones de texto utilizados para expresar puntos de vista y pensamientos.

En este estudio, usaremos R para realizar análisis en los tweets publicados por una de las celebridades más famosas, es decir, Emma Watson. Primero pasaremos por el análisis exploratorio y luego pasaremos al análisis de texto.
Extrayendo los datos de Twitter de Emma Watson
La API de Twitter nos permite descargar 3200 tweets recientes; todo lo que tenemos que hacer es crear una aplicación de Twitter para obtener la clave API y el token de acceso. Siga los pasos que se indican a continuación para crear la aplicación:
- Abre https://apps.twitter.com
- Haga clic en 'Crear nueva aplicación'
- Introduce los datos y haz clic en 'Crea tu aplicación de Twitter'
- Haga clic en la pestaña 'Claves y tokens de acceso' y copie la clave API y el secreto
- Desplácese hacia abajo y haga clic en "Crear mi token de acceso"
Hay una biblioteca R llamada rtweet que se usará para descargar los tweets y crear un marco de datos. Use el código que se proporciona a continuación para continuar:
[lenguaje del código=”r”]
instalar.paquetes(“httr”)
instalar.paquetes ("rtweet")
biblioteca ("httr")
biblioteca ("rtweet")
# el nombre de la aplicación de twitter creada por ti
nombre de la aplicación <- "análisis de tweets"
# clave api (reemplace la siguiente muestra con su clave)
clave <- “8YnCioFqKFaebTwjoQfcVLPS”
# api secret (reemplace lo siguiente con su secreto)
secreto <- “uSzkAOXnNpSDsaDAaDDDSddsA6Cukfds8a3tRtSG”
# crear token llamado "twitter_token"
twitter_token <- crear_token(
aplicación = nombre de la aplicación,
consumidor_clave = clave,
consumidor_secreto = secreto)
#Descargando los tuits publicados por Emma Watson
ew_tweets <- get_timeline(“EmmaWatson”, n = 3200)
[/código]
Análisis exploratorio
Aquí resumiremos el conjunto de datos visualizando lo siguiente:
- Número de tuits publicados entre 2010 y 2018
- Frecuencia de tuits a lo largo de los meses
- Frecuencia de tweets a lo largo de una semana
- Densidad de tweets a lo largo de un día
- Comparación del número de retuits y tuits originales
Tweets por año
Usaremos la increíble biblioteca ggplot2 y lubridate para trazar gráficos y trabajar con las fechas. Continúe y siga el código que se proporciona a continuación para instalar y cargar los paquetes:
[lenguaje del código=”r”]
instalar.paquetes ("ggplot2")
install.packages(“lubricar”)
biblioteca ("ggplot2")
biblioteca ("lubridar")
[/código]
Ejecute el siguiente código para trazar el recuento de tweets a lo largo de los años desglosándolos en meses:
[lenguaje del código=”r”]
ggplot(datos = ew_tweets,
aes(mes(creado_en, etiqueta=VERDADERO, abbr=VERDADERO),
grupo=factor(año(creado_en)), color=factor(año(creado_en))))+
geom_line(stat=”recuento”) +
geom_point(stat=”recuento”) +
labs(x=”Mes”, color=”Año”) +
xlab(“Mes”) + ylab(“Número de tweets”) +
tema_minimal()
[/código]
El resultado es el siguiente gráfico:
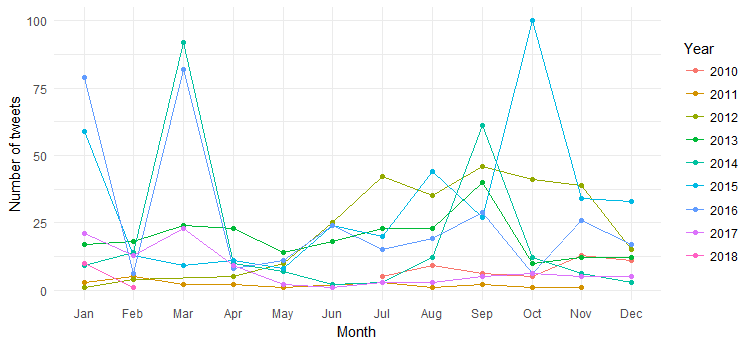
Podemos ver la ruptura de los tweets mensuales (picos en marzo de 2014, marzo de 2016 y octubre de 2015) a lo largo de los años, pero la interpretación es difícil. Ahora simplifiquemos el gráfico trazando solo los recuentos de tweets por año.
[lenguaje del código=”r”]
ggplot(datos = ew_tweets, aes(x = año(creado_en))) +
geom_bar(aes(llenar = ..contar..)) +
xlab(“Año”) + ylab(“Número de tuits”) +
scale_x_continuous (descansos = c(2010:2018)) +
tema_minimal() +
scale_fill_gradient(bajo = “cadetblue3”, alto = “chartreuse4”)
[/código]
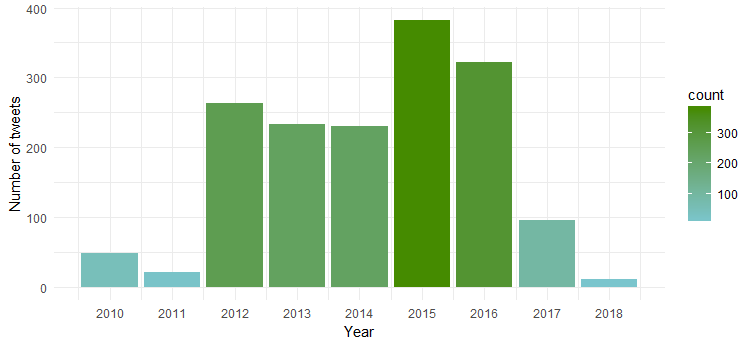
El gráfico resultante muestra que estuvo más activa en 2015 y 2016, mientras que 2011 fue testigo de la menor actividad.
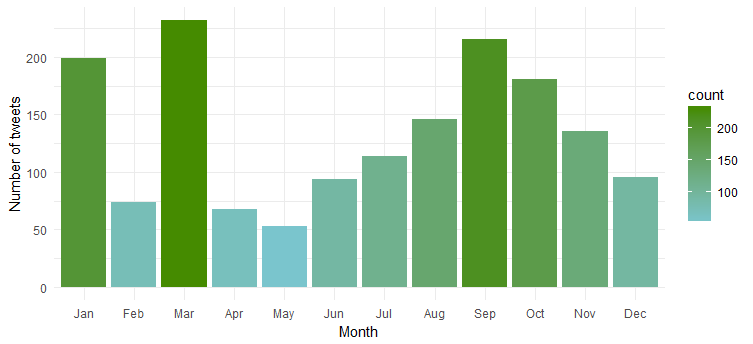
Frecuencia de tuits a lo largo de los meses
Averigüemos ahora en los datos de Twitter de Emma Watson para ver si tuitea por igual durante los meses de un año o si hay meses específicos en los que tuitea más. Use el siguiente código para crear el gráfico:
[lenguaje del código=”r”]
ggplot(datos = ew_tweets, aes(x = mes(creado_en, etiqueta = VERDADERO))) +
geom_bar(aes(llenar = ..contar..)) +
xlab(“Mes”) + ylab(“Número de tweets”) +
tema_minimal() +
scale_fill_gradient(bajo = “cadetblue3”, alto = “chartreuse4”)
[/código]
Claramente, es más activa durante 'enero', 'marzo' y 'septiembre'.
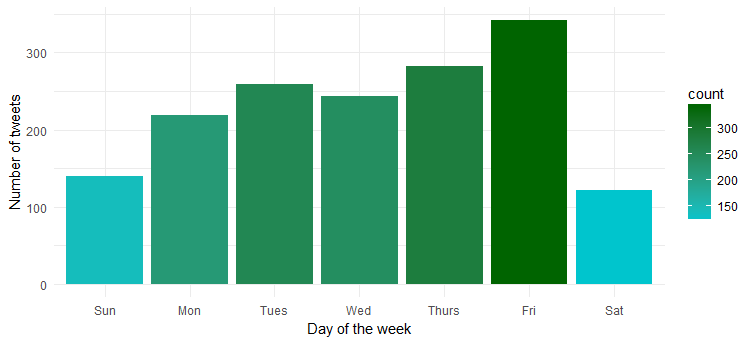
Frecuencia de tweets a lo largo de una semana
¿Hay algún día específico de la semana en el que sea más activa? Tracemos el gráfico ejecutando el siguiente código:
[lenguaje del código=”r”]
ggplot(data = ew_tweets, aes(x = wday(created_at, label = TRUE))) +
geom_bar(aes(llenar = ..contar..)) +
xlab(“Día de la semana”) + ylab(“Número de tuits”) +
tema_minimal() +
scale_fill_gradient(bajo = “turquesa3”, alto = “verde oscuro”)
[/código]
Hmm… ella está más activa los viernes. ¿Probablemente preparándose para entrar en modo fiesta?
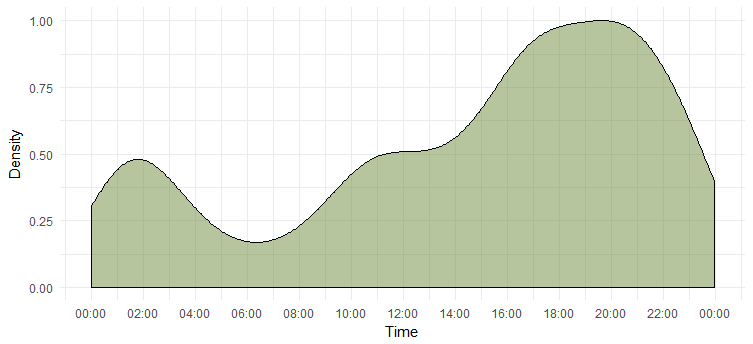
Densidad de tweets a lo largo de un día
Hemos averiguado el día más activo, pero no sabemos el momento en el que está más activa. El siguiente cuadro nos dará la respuesta.
[lenguaje del código=”r”]
# paquete para almacenar y formatear la hora del día
instalar.paquetes(“hms”)
# paquete para agregar pausas de tiempo y etiquetas
install.packages(“escalas”)
biblioteca ("hms")
biblioteca ("escalas")
# Extraiga solo el tiempo de la marca de tiempo, es decir, hora, minuto y segundo
ew_tweets$tiempo <- hms::hms(segundo(ew_tweets$creado_en),
minuto(ew_tweets$creado_en),
hora(ew_tweets$created_at))
# Convertir a `POSIXct` ya que ggplot no es compatible con `hms`
ew_tweets$tiempo <- as.POSIXct(ew_tweets$tiempo)
ggplot(datos = ew_tweets)+
geom_density(aes(x = tiempo, y = ..escalado..),
relleno = "verde vivo oscuro 4", alfa = 0.3) +
xlab(“Tiempo”) + ylab(“Densidad”) +
scale_x_datetime(breaks = date_breaks(“2 horas”),
etiquetas = formato_fecha(“%H:%M”)) +
tema_minimal()
[/código]

Esto nos dice que ella está más activa entre las 6 y las 8 p. m. Tenga en cuenta que la zona horaria es UTC (se puede averiguar usando la función `unclass`).
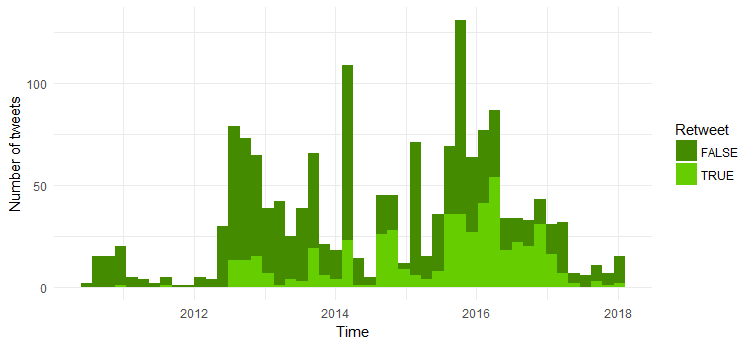
Comparación del número de retuits y tuits originales
Ahora compararemos la cantidad de tweets originales y retweets. A continuación se muestra el código:
[lenguaje del código=”r”]
ggplot(datos = ew_tweets, aes(x = created_at, fill = is_retweet)) +
geom_histograma(contenedores=48) +
xlab(“Tiempo”) + ylab(“Número de tweets”) + theme_minimal() +
scale_fill_manual(valores = c(“chartreuse4”, “chartreuse3”),
nombre = “Retwittear”)
[/código]
La mayoría de los tweets son tweets originales. Es interesante ver que el número de re-tweets aumentó desde 2014.
Extracción de textos
Pasemos ahora a un área más interesante: realizaremos técnicas de minería de texto, incluida la PNL, para descubrir lo siguiente:
1. Hashtags de uso frecuente
2. Nube de palabras de los textos de los tuits
3. Análisis de sentimiento
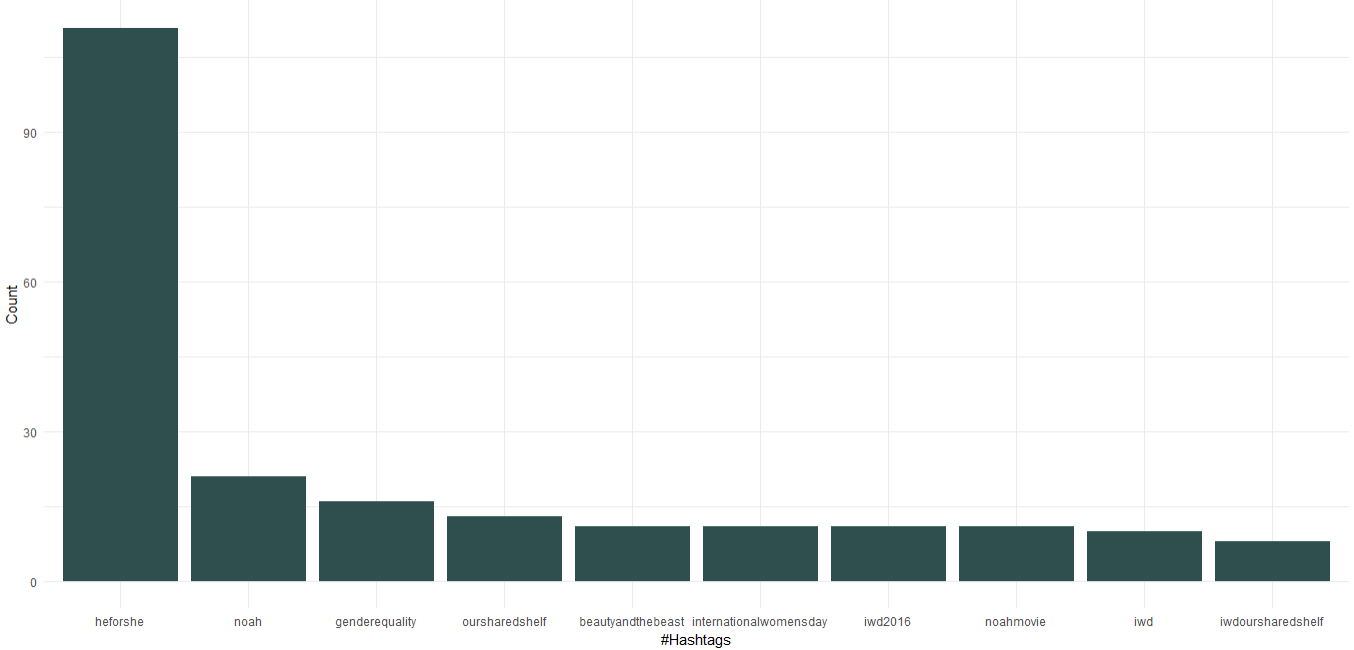
1. Hashtags de uso frecuente
El conjunto de datos descargado ya tiene una columna que contiene hashtags; lo usaremos para descubrir los 10 hashtags principales utilizados por Emma. A continuación se muestra el código para crear el gráfico para los hashtags:
[lenguaje del código=”r”]
# Paquete para trabajar fácilmente con marcos de datos
instalar.paquetes(“dplyr”)
biblioteca ("dplyr")
# Obtener los hashtags de la lista
ew_tags_split <- unlist(strsplit(as.character(unlist(ew_tweets$hashtags)),'^c(|,|”|)'))
# Formateo eliminando el espacio en blancoa
ew_tags <- sapply(ew_tags_split, function(y) nchar(trimws(y)) > 0 & !is.na(y))
ew_tag_df <- as_data_frame(table(tolower(ew_tags_split[ew_tags])))
ew_tag_df <- ew_tag_df[con(ew_tag_df,orden(-n)),]
ew_tag_df <- ew_tag_df[1:10,]
ggplot(ew_tag_df, aes(x = reordenar(Var1, -n), y=n)) +
geom_bar(stat=”identidad”, fill=”darkslategray”)+
tema_minimal() +
xlab(“#Hashtags”) + ylab(“Recuento”)
[/código]
Podemos ver que, como Embajadora de Buena Voluntad de ONU Mujeres, Emma Watson ha promovido la campaña “HeForShe” que se centra en la igualdad de género. Aparte de eso, ha promovido su club de lectura llamado "Nuestro estante compartido" y "Día internacional de la mujer". Viniendo al cine, "Noah", "La Bella y la Bestia" aparecen entre los 10 hashtags principales.
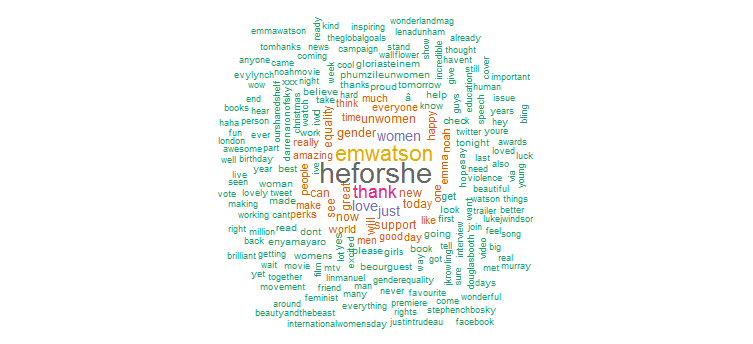
2. Nube de palabras
Ahora analizaremos el texto del tweet para encontrar las palabras más frecuentes y crear una nube de palabras. Ejecute el siguiente código para continuar:
[lenguaje del código=”r”]
#instalar paquete de minería de texto y nube de palabras
install.packages(c(“tm”, “nube de palabras”))
biblioteca ("tm")
biblioteca ("nube de palabras")
tweet_text <- ew_tweets$texto
#Eliminación de números, signos de puntuación, enlaces y contenido alfanumérico
tweet_text<- gsub('[[:dígito:]]+', ”, tweet_text)
tweet_text<- gsub('[[:punto:]]+', ”, tweet_text)
tweet_text<- gsub(“http[[:alnum:]]*”, “”, tweet_text)
tweet_text<- gsub(“([[:alpha:]])1+”, “”, tweet_text)
#creando un corpus de texto
documentos <- Corpus(VectorSource(tweet_text))
# convertir la codificación a UTF-8 para manejar personajes divertidos
documentos <- tm_map(docs, function(x) iconv(enc2utf8(x), sub = “byte”))
# Convirtiendo el texto a minúsculas
documentos <- tm_map(docs, content_transformer(tolower))
# Eliminar palabras vacías comunes en inglés
docs <- tm_map(docs, removeWords, stopwords(“english”))
# Eliminar palabras vacías especificadas por nosotros como un vector de caracteres
documentos <- tm_map(docs, removeWords, c(“amp”))
# creando una matriz de documentos de términos
tdm <- TermDocumentMatrix(docs)
# definiendo tdm como matriz
m <- como.matriz(tdm)
# obtener recuentos de palabras en orden decreciente
word_freqs = sort(rowSums(m), decreciente=VERDADERO)
# creando un marco de datos con palabras y sus frecuencias
ew_wf <- data.frame(palabra=nombres(palabra_frecuencias), frecuencia=palabra_frecuencias)
# nube de palabras de trazado
set.seed(1234)
wordcloud(palabras = ew_wf$palabra, frecuencia = ew_wf$frecuencia,
min.freq = 1,escala=c(1.8,.5),
max.words=200, random.order=FALSE, rot.per=0.15,
colores=cervecero.pal(8, “Oscuro2”))
[/código]
Claramente, ha realizado una gran promoción para la campaña "HeforShe". Otras palabras de uso frecuente son “gracias”, “amor”, “mujeres”, “género” y “ONU-Mujeres”. Esto está claramente en línea con los hashtags que sugieren que su actividad en Twitter está bastante enfocada en temas de mujeres.
3. Análisis de sentimiento
Para la extracción de sentimientos y el trazado, aplicaremos el paquete syuzhet . Este paquete se basa en un léxico de emociones que mapea diferentes palabras con varias emociones (alegría, miedo, ira, sorpresa, etc.) y polaridad de sentimiento (positivo/negativo). Tendremos que calcular la puntuación de emoción en función de las palabras presentes en los tweets y trazar lo mismo.
[lenguaje del código=”r”]
install.packages(“syuzhet”)
biblioteca (syuzhet)
# Conversión de tweets a ASCII para rastrear caracteres extraños
tweet_text <- iconv(tweet_text, from=”UTF-8″, to=”ASCII”, sub=””)
# eliminando retuits
tweet_text<-gsub(“(RT|via)((?:bw*@w+)+)”,””,tweet_text)
# eliminando menciones
tweet_text<-gsub(“@w+”,””,tweet_text)
ew_sentiment<-get_nrc_sentiment((tweet_text))
puntuaciones de sentimientos<-data.frame(colSums(ew_sentiment[,]))
nombres(puntuaciones de sentimientos) <- “Puntuación”
puntuaciones de opinión <- cbind(“opinión”=nombresdefila(puntuaciones de opinión),puntuaciones de opinión)
nombres de filas (puntuaciones de opiniones) <- NULL
ggplot(data=puntuaciones de sentimientos,aes(x=sentimiento,y=puntuación))+
geom_bar(aes(fill=sentimiento),stat = “identidad”)+
tema(leyenda.posición=”ninguno”)+
xlab(“Sentimientos”)+ylab(“Puntajes”)+
ggtitle(“Total sentimiento basado en puntajes”)+
tema_minimal()
[/código]
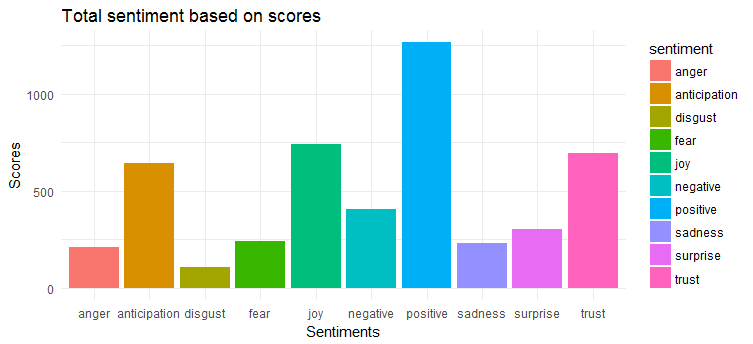
El siguiente gráfico muestra que los tweets tienen un sentimiento mayormente positivo. Las tres emociones más expresadas son 'alegría', 'confianza' y 'anticipación'.
A ti
En este estudio, cubrimos el análisis exploratorio de datos y las técnicas de minería de textos para comprender los patrones de tuits y el tema subyacente de los tuits publicados por Emma Watson. Se pueden realizar análisis adicionales para encontrar el usuario de Twitter mencionado con frecuencia, crear un gráfico de red y clasificar los tweets mediante el modelado de temas.
Siga este tutorial y comparta sus hallazgos en la sección de comentarios.
