
تعدين تغريدات إيما واتسون مع R.
نشرت: 2018-02-03يحتوي دفق Twitter لأي شخص على بيانات اجتماعية غنية يمكن أن تكشف الكثير عن هذا الشخص. نظرًا لأن بيانات Twitter عامة و API مفتوحة لأي شخص لاستخدامها ، يمكن تطبيق تقنيات استخراج البيانات بسهولة لمعرفة كل شيء بدءًا من أنماط التوقيت والمواضيع التي يركز عليها الشخص إلى أنماط النص المستخدمة للتعبير عن الآراء والأفكار.

في هذه الدراسة ، سنستخدم R لإجراء تحليلات على التغريدات التي نشرها أحد أشهر المشاهير ، أي إيما واتسون. أولاً سننتقل إلى التحليل الاستكشافي ثم ننتقل إلى التحليلات النصية.
استخراج بيانات تويتر إيما واتسون
يتيح لنا Twitter API تنزيل 3200 تغريدة حديثة - كل ما نحتاج إليه هو إنشاء تطبيق Twitter للحصول على مفتاح API ورمز الوصول. اتبع الخطوات الواردة أدناه لإنشاء التطبيق:
- افتح https://apps.twitter.com
- انقر فوق "إنشاء تطبيق جديد"
- أدخل التفاصيل وانقر فوق "إنشاء تطبيق Twitter الخاص بك"
- انقر فوق علامة التبويب "المفاتيح ورموز الوصول" وانسخ مفتاح API والسر
- قم بالتمرير لأسفل وانقر على "إنشاء رمز الوصول الخاص بي"
توجد مكتبة R تسمى rtweet والتي سيتم استخدامها لتنزيل التغريدات وإنشاء إطار بيانات. استخدم الكود أدناه للمتابعة:
[لغة الكود = "r"]
install.packages ("HTR")
install.packages ("rtweet")
مكتبة ("HTR")
مكتبة ("rtweet")
# اسم تطبيق twitter الذي أنشأته
appname <- "tweet-analytics"
# مفتاح api (استبدل النموذج التالي بمفتاحك)
المفتاح <- "8YnCioFqKFaebTwjoQfcVLPS"
# سر واجهة برمجة التطبيقات (استبدل ما يلي بسرك)
سري <- "uSzkAOXnNpSDsaDAaDDDSddsA6Cukfds8a3tRtSG"
# إنشاء رمز باسم “twitter_token”
twitter_token <- create_token (
app = appname ،
Consumer_key = مفتاح ،
Consumer_secret = سر)
# تنزيل التغريدات التي نشرتها إيما واتسون
ew_tweets <- get_timeline ("إيماواتسون" ، العدد = 3200)
[/الشفرة]
التحليل الاستكشافي
سنلخص هنا مجموعة البيانات من خلال تصور ما يلي:
- عدد التغريدات المنشورة من 2010 إلى 2018
- تواتر التغريدات على مدار الأشهر
- تواتر التغريد خلال أسبوع
- كثافة التغريدات خلال يوم واحد
- مقارنة بين عدد إعادات التغريد والتغريدات الأصلية
تغريدات العام
سنستخدم مكتبة lubridate و ggplot2 المذهلة لرسم المخططات والعمل مع التواريخ. تابع واتبع الكود الموضح أدناه لتثبيت وتحميل الحزم:
[لغة الكود = "r"]
install.packages ("ggplot2")
install.packages ("lubridate")
مكتبة ("ggplot2")
مكتبة ("lubridate")
[/الشفرة]
نفِّذ الكود التالي لرسم عدد التغريدات على مر السنين عن طريق تقسيمها إلى أشهر:
[لغة الكود = "r"]
ggplot (البيانات = ew_tweets ،
aes (month (created_at، label = TRUE، abbr = TRUE)،
المجموعة = العامل (السنة (تم إنشاؤه)) ، اللون = العامل (السنة (تم إنشاؤه)))) +
geom_line (stat = ”count”) +
geom_point (stat = ”count”) +
labs (س = "شهر" ، اللون = "السنة") +
xlab ("الشهر") + ylab ("عدد التغريدات") +
theme_minimal ()
[/الشفرة]
والنتيجة هي الرسم البياني التالي:
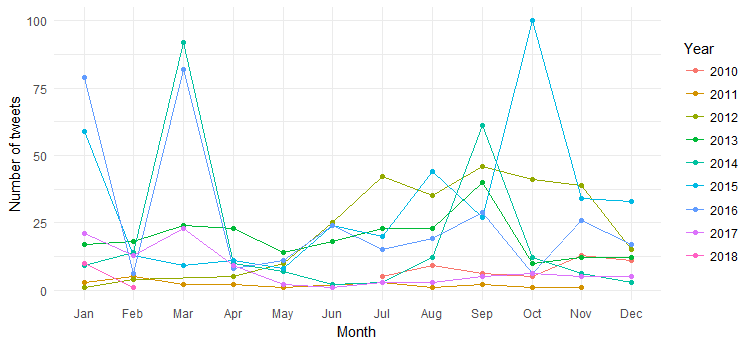
يمكننا أن نرى تفكك التغريدات الشهرية (ارتفاعات في مارس 2014 ، مارس 2016 وأكتوبر 2015) على مر السنين ، لكن التفسير صعب. دعنا الآن نبسط المخطط عن طريق رسم عدد التغريدات على مدار العام فقط.
[لغة الكود = "r"]
ggplot (data = ew_tweets، aes (x = year (created_at))) +
geom_bar (aes (fill = ..count ..)) +
xlab ("السنة") + ylab ("عدد التغريدات") +
scale_x_continuous (فواصل = c (2010: 2018)) +
theme_minimal () +
scale_fill_gradient (منخفض = "cadetblue3" ، مرتفع = "مخطط 4")
[/الشفرة]
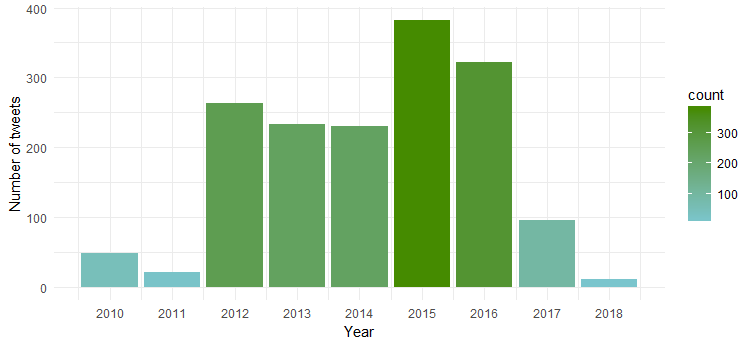
يُظهر الرسم البياني الناتج أنها كانت أكثر نشاطًا في عامي 2015 و 2016 بينما شهد عام 2011 أقل نشاط.
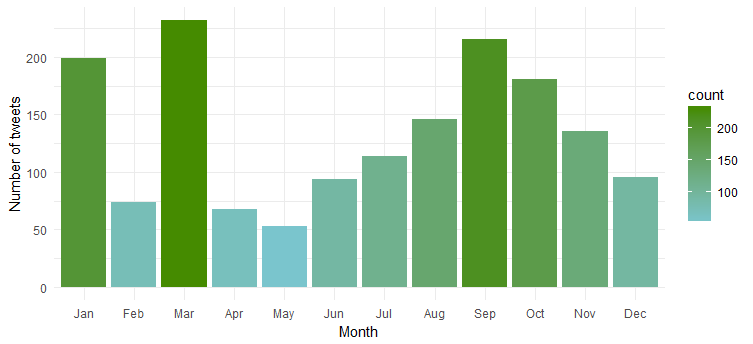
تواتر التغريدات على مدار الأشهر
دعنا الآن نكتشف في Emma Watson Twitter Data لنرى ما إذا كانت تغرد بشكل متساوٍ على مدار أشهر السنة أو أن هناك أي أشهر محددة تغرد فيها أكثر من غيرها. استخدم الكود التالي لإنشاء المخطط:
[لغة الكود = "r"]
ggplot (data = ew_tweets، aes (x = month (created_at، label = TRUE))) +
geom_bar (aes (fill = ..count ..)) +
xlab ("الشهر") + ylab ("عدد التغريدات") +
theme_minimal () +
scale_fill_gradient (منخفض = "cadetblue3" ، مرتفع = "مخطط 4")
[/الشفرة]
من الواضح أنها أكثر نشاطًا خلال "يناير" و "مارس" و "سبتمبر".
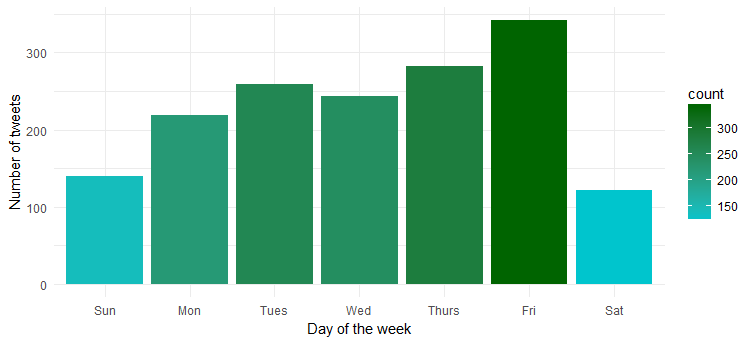
تواتر التغريد خلال أسبوع
هل هناك يوم محدد في الأسبوع تكون فيه أكثر نشاطًا؟ دعنا نرسم المخطط عن طريق تنفيذ الكود التالي:
[لغة الكود = "r"]
ggplot (data = ew_tweets، aes (x = wday (created_at، label = TRUE))) +
geom_bar (aes (fill = ..count ..)) +
xlab ("يوم الأسبوع") + ylab ("عدد التغريدات") +
theme_minimal () +
scale_fill_gradient (منخفض = "تركواز 3" ، مرتفع = "أخضر غامق")
[/الشفرة]
حسنًا ... هي أكثر نشاطًا يوم الجمعة. ربما تستعد للدخول في وضع الحفلة؟
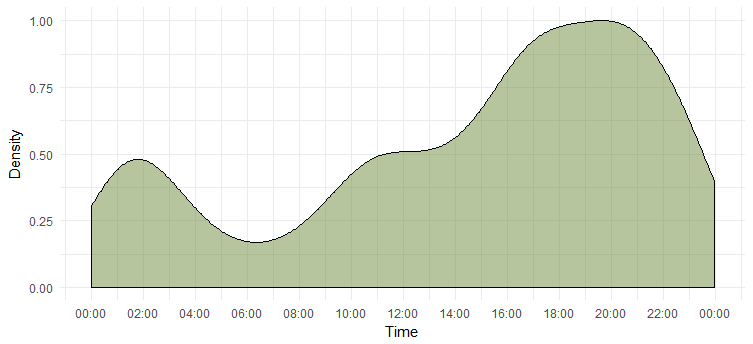
كثافة التغريدات خلال يوم واحد
لقد اكتشفنا اليوم الأكثر نشاطًا ، لكننا لا نعرف الوقت الذي تكون فيه أكثر نشاطًا. سيعطينا الرسم البياني التالي الإجابة.

[لغة الكود = "r"]
# حزمة لتخزين وتنسيق وقت اليوم
install.packages ("hms")
# حزمة لإضافة فواصل زمنية والتسميات
install.packages ("موازين")
مكتبة ("hms")
مكتبة ("موازين")
# استخرج الوقت فقط من الطابع الزمني ، أي الساعة والدقيقة والثانية
ew_tweets $ time <- hms :: hms (second (ew_tweets $ created_at)،
دقيقة (ew_tweets $ created_at) ،
ساعة (ew_tweets $ created_at))
# التحويل إلى "POSIXct" لأن ggplot غير متوافق مع "hms"
ew_tweets $ time <- as.POSIXct (ew_tweets $ time)
ggplot (البيانات = ew_tweets) +
كثافة الأرض (أيس (س = الوقت ، ص = .. المقياس ..) ،
ملء = "darkolivegreen4 ″ ، ألفا = 0.3) +
xlab ("الوقت") + ylab ("الكثافة") +
scale_x_datetime (فواصل = فواصل التاريخ ("ساعتان") ،
labels = date_format (“٪ H:٪ M”)) +
theme_minimal ()
[/الشفرة]
يخبرنا هذا أنها تكون أكثر نشاطًا خلال 6-8 مساءً. لاحظ أن المنطقة الزمنية هي التوقيت العالمي المنسق (يمكن اكتشاف ذلك باستخدام وظيفة "unclass". ضع ذلك في الاعتبار أثناء التغريد لـ Emma.
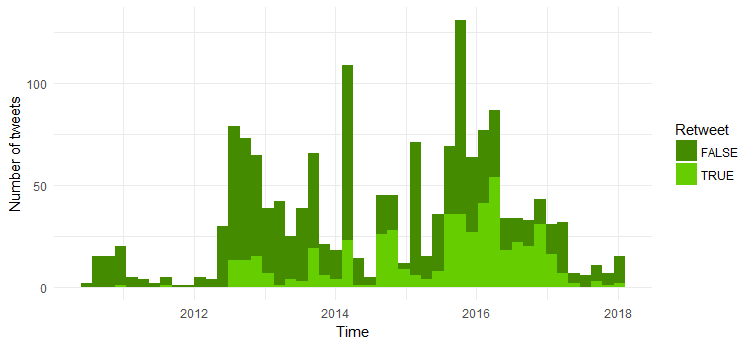
مقارنة بين عدد إعادات التغريد والتغريدات الأصلية
سنقوم الآن بمقارنة عدد التغريدات الأصلية وإعادة التغريدات. أدناه هو الرمز:
[لغة الكود = "r"]
ggplot (data = ew_tweets، aes (x = created_at، fill = is_retweet)) +
geom_histogram (صناديق = 48) +
xlab ("الوقت") + ylab ("عدد التغريدات") + theme_minimal () +
scale_fill_manual (القيم = c ("chartreuse4" ، "chartreuse3") ،
name = "إعادة تغريد")
[/الشفرة]
غالبية التغريدات هي تغريدات أصلية. من المثير للاهتمام أن نرى أن عدد عمليات إعادة التغريد قد زاد منذ عام 2014.
تحليل النصوص
دعنا الآن ندخل إلى منطقة أكثر إثارة للاهتمام - سنقوم بتنفيذ تقنيات التنقيب عن النصوص بما في ذلك البرمجة اللغوية العصبية (NLP) لاكتشاف ما يلي:
1. كثرة استخدام الهاشتاقات
2. سحابة كلمات نصوص التغريدات
3. تحليل المشاعر
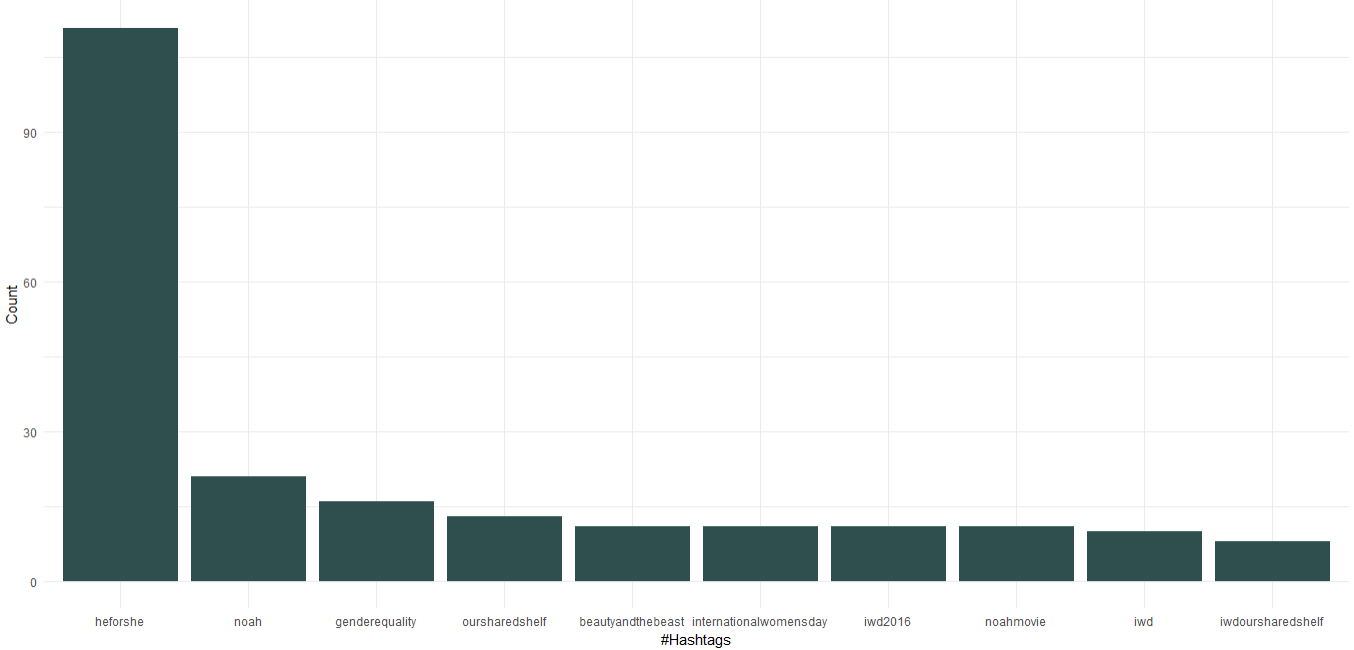
1. كثرة استخدام الهاشتاقات
تحتوي مجموعة البيانات التي تم تنزيلها بالفعل على عمود يحتوي على علامات تصنيف ؛ سنستخدم ذلك لمعرفة أفضل 10 علامات تصنيف تستخدمها Emma. فيما يلي رمز إنشاء مخطط لعلامات التصنيف:
[لغة الكود = "r"]
# حزمة للعمل بسهولة مع إطارات البيانات
install.packages ("dplyr")
مكتبة ("dplyr")
# الحصول على الهاشتاج من القائمة
ew_tags_split <- unlist (strsplit (as.character (unlist (ew_tweets $ hashtags))، '^ c (|، | ”|)'))
# التنسيق عن طريق إزالة الفراغ الأبيض
ew_tags <- sapply (ew_tags_split، function (y) nchar (trimws (y))> 0 &! is.na (y))
ew_tag_df <- as_data_frame (جدول (tolower (ew_tags_split [ew_tags])))
ew_tag_df <- ew_tag_df [with (ew_tag_df، order (-n))،]
ew_tag_df <- ew_tag_df [1:10،]
ggplot (ew_tag_df، aes (x = إعادة ترتيب (Var1، -n)، y = n)) +
geom_bar (stat = ”Identity” ، fill = “darkslategray”) +
theme_minimal () +
xlab (“# Hashtags”) + ylab (“Count”)
[/الشفرة]
يمكننا أن نرى أنه بصفتها سفيرة الأمم المتحدة للنوايا الحسنة ، قامت إيما واتسون بالترويج لحملة "HeForShe" التي تركز على المساواة بين الجنسين. بصرف النظر عن ذلك ، روجت لنادي الكتاب المسمى "رفنا المشترك" و "اليوم العالمي للمرأة". تأتي الأفلام ، "نوح" ، "الجميلة والوحش" في أفضل 10 علامات تصنيف.
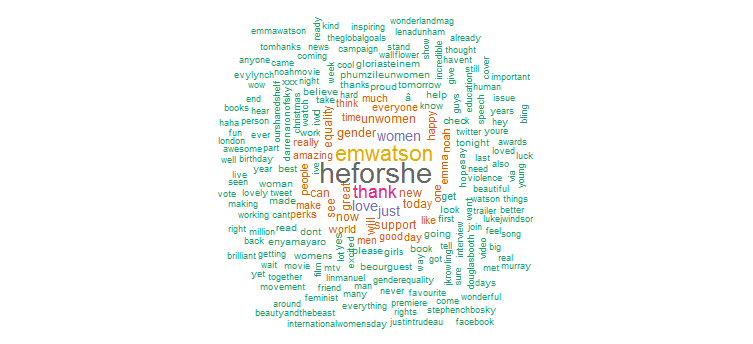
2. سحابة الكلمات
سنقوم الآن بتحليل نص التغريدة لمعرفة الكلمات الأكثر شيوعًا وإنشاء سحابة كلمات. قم بتنفيذ التعليمات البرمجية التالية للمتابعة:
[لغة الكود = "r"]
# install تعدين النص وحزمة سحابة الكلمات
install.packages (c ("tm"، "wordcloud"))
مكتبة ("tm")
مكتبة ("wordcloud")
tweet_text <- ew_tweets $ text
# إزالة الأرقام وعلامات الترقيم والروابط والمحتوى الأبجدي الرقمي
tweet_text <- gsub ('[[: digit:]] +'، "، tweet_text)
tweet_text <- gsub ('[[: punct:]] +'، "، tweet_text)
tweet_text <- gsub ("http [[: alnum:]] *"، ""، tweet_text)
tweet_text <- gsub (“([[: alpha:]]) 1+"، ""، tweet_text)
#creating نص
docs <- Corpus (VectorSource (tweet_text))
# تغطية الترميز إلى UTF-8 للتعامل مع الشخصيات المضحكة
docs <- tm_map (مستندات ، الوظيفة (x) iconv (enc2utf8 (x) ، sub = "بايت"))
# تحويل النص إلى أحرف صغيرة
docs <- tm_map (docs، content_transformer (tolower))
# إزالة كلمات التوقف الإنجليزية الشائعة
docs <- tm_map (docs، removeWords، stopwords ("english"))
# إزالة كلمات الإيقاف المحددة من قبلنا كمتجه للشخصية
docs <- tm_map (docs، removeWords، c (“amp”))
# إنشاء مصفوفة وثيقة المدى
tdm <- TermDocumentMatrix (مستندات)
# تعريف tdm كمصفوفة
م <- مصفوفة (تدم)
# الحصول على عدد الكلمات بترتيب تنازلي
word_freqs = الترتيب (rowSums (m) ، تناقص = TRUE)
# إنشاء إطار بيانات بالكلمات وتردداتها
ew_wf <- data.frame (word = names (word_freqs) ، freq = word_freqs)
# التآمر wordcloud
set.seed (1234)
wordcloud (الكلمات = ew_wf $ word ، freq = ew_wf $ freq ،
الحد الأدنى للتكرار = 1 ، المقياس = ج (1.8 ، .5) ،
max.words = 200 ، random.order = FALSE ، rot.per = 0.15 ،
الألوان = brewer.pal (8، “Dark2”))
[/الشفرة]
من الواضح أنها قامت بترويج مكثف لحملة "HeforShe". والكلمات الأخرى التي يكثر استخدامها هي "الشكر" و "الحب" و "المرأة" و "الجنس" و "هيئة الأمم المتحدة للمرأة". يتماشى هذا بوضوح مع علامات التصنيف التي تشير إلى أن نشاطها على Twitter يركز تمامًا على قضايا المرأة.
3. تحليل المشاعر
لاستخراج المشاعر والتخطيط ، سنقوم بتطبيق حزمة syuzhet . تعتمد هذه الحزمة على معجم العاطفة الذي يرسم كلمات مختلفة بمشاعر مختلفة (الفرح ، الخوف ، الغضب ، المفاجأة ، إلخ) وقطبية المشاعر (إيجابية / سلبية). سيتعين علينا حساب درجة العاطفة بناءً على الكلمات الموجودة في التغريدات ونفس الشيء.
[لغة الكود = "r"]
install.packages ("syuzhet")
مكتبة (syuzhet)
# تحويل التغريدات إلى ASCII لتتبع الشخصيات الغريبة
tweet_text <- iconv (tweet_text، from = ”UTF-8 ″، to =“ ASCII ”، sub =” ”)
# إزالة التغريدات
tweet_text <-gsub ("(RT | عبر) ((؟: bw * @ w +) +)" ، "" ، tweet_text)
# إزالة الإشارات
tweet_text <-gsub ("@ w +"، ""، tweet_text)
ew_sentiment <-get_nrc_sentiment ((tweet_text))
المعنويات <-data.frame (colSums (ew_sentiment [،]))
أسماء (مشاعر) <- "نقاط"
sentimentscores <- cbind ("المعنويات" = أسماء rown (sentimentscores) ، المشاعر)
أسماء rownames (sentimentscores) <- NULL
ggplot (البيانات = المشاعر ، aes (x = العاطفة ، y = الدرجة)) +
geom_bar (aes (ملء = الشعور) ، stat = "الهوية") +
موضوع (legend.position = "لا شيء") +
xlab ("المشاعر") + ylab ("النتائج") +
ggtitle ("المشاعر الإجمالية بناءً على النتائج") +
theme_minimal ()
[/الشفرة]
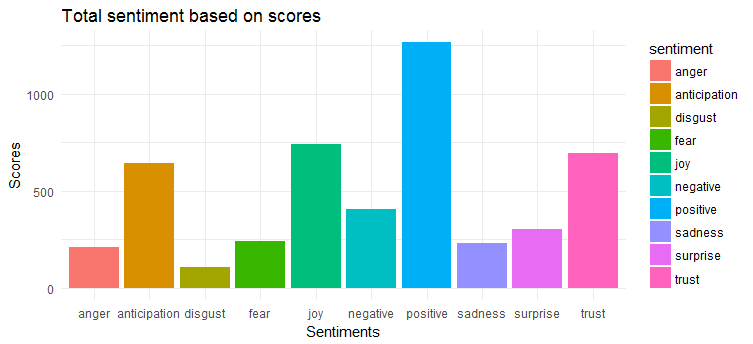
يظهر الرسم البياني التالي أن التغريدات لها مشاعر إيجابية إلى حد كبير. العواطف الثلاثة الأكثر تعبيرًا هي "الفرح" و "الثقة" و "الترقب".
انتهى اليك
في هذه الدراسة ، قمنا بتغطية تحليل البيانات الاستكشافية وتقنيات التنقيب عن النصوص لفهم أنماط التغريد والموضوع الأساسي للتغريدات التي نشرتها إيما واتسون. يمكن إجراء مزيد من التحليل لمعرفة مستخدم Twitter الذي يتم ذكره بشكل متكرر ، وإنشاء رسم بياني للشبكة وتصنيف التغريدات باستخدام نمذجة الموضوع.
اتبع هذا البرنامج التعليمي وشارك نتائجك في قسم التعليقات.
