
R でエマ・ワトソンのツイートをマイニング
公開: 2018-02-03誰の Twitter ストリームにも、その人物について多くのことを明らかにできる豊富なソーシャル データが含まれています。 Twitter のデータは公開されており、API は誰でも使用できるため、データ マイニング技術を簡単に適用して、タイミング パターンやユーザーが注目しているトピックから、意見や考えを表現するために使用されるテキスト パターンまで、あらゆるものを見つけることができます。

この調査では、 Rを使用して、最も有名な有名人の 1 人であるエマ ワトソンが投稿したツイートを分析します。 最初に探索的分析を行い、次にテキスト分析に移ります。
Emma Watson の Twitter データの抽出
Twitter API を使用すると、最近の 3,200 件のツイートをダウンロードできます。Twitter アプリを作成して、API キーとアクセス トークンを取得するだけです。 アプリを作成するには、次の手順に従います。
- https://apps.twitter.comを開く
- 「新しいアプリを作成」をクリック
- 詳細を入力し、「Create your Twitter application」をクリックします
- [キーとアクセス トークン] タブをクリックし、API キーとシークレットをコピーします。
- 下にスクロールして、「Create my access token」をクリックします
ツイートをダウンロードしてデータ フレームを作成するために使用されるrtweetというRライブラリがあります。 以下のコードを使用して続行します。
[コード言語=”r”]
install.packages(“httr”)
install.packages(“rtweet”)
ライブラリ(“httr”)
ライブラリ(“rtweet”)
# 作成した Twitter アプリの名前
appname <-「ツイート分析」
# api キー (次のサンプルを自分のキーに置き換えてください)
キー <-「8YnCioFqKFaebTwjoQfcVLPS」
# api シークレット (以下を自分のシークレットに置き換えてください)
シークレット <-「uszkAOXnNpSDsaDAaDDDSddsA6Cukfds8a3tRtSG」
# 「twitter_token」という名前のトークンを作成
twitter_token <- create_token(
アプリ = アプリ名、
consumer_key = キー、
consumer_secret = シークレット)
#エマ・ワトソンが投稿したツイートのダウンロード
ew_tweets <- get_timeline(“エマワトソン”, n = 3200)
[/コード]
探索的分析
ここでは、以下を視覚化してデータセットを要約します。
- 2010年から2018年までのツイート投稿数
- 数か月にわたるツイートの頻度
- 1 週間のツイート頻度
- 一日のつぶやき密度
- リツイート数とオリジナルツイート数の比較
年間ツイート数
すばらしいggplot2とlubridateライブラリを使用して、グラフをプロットし、日付を操作します。 以下のコードに従って、パッケージをインストールしてロードします。
[コード言語=”r”]
install.packages(“ggplot2”)
install.packages(“lubridate”)
ライブラリ(“ggplot2”)
ライブラリ(「滑らかにする」)
[/コード]
次のコードを実行して、数年にわたるツイート数を月ごとにプロットします。
[コード言語=”r”]
ggplot(data = ew_tweets,
aes(month(created_at, label=TRUE, abbr=TRUE),
グループ=係数(年(作成時))、色=係数(年(作成時))))+
geom_line(stat="カウント") +
geom_point(stat="カウント") +
labs(x=”月”, color=”年”) +
xlab(“月”) + ylab(“ツイート数”) +
theme_minimal()
[/コード]
その結果が次のチャートです。
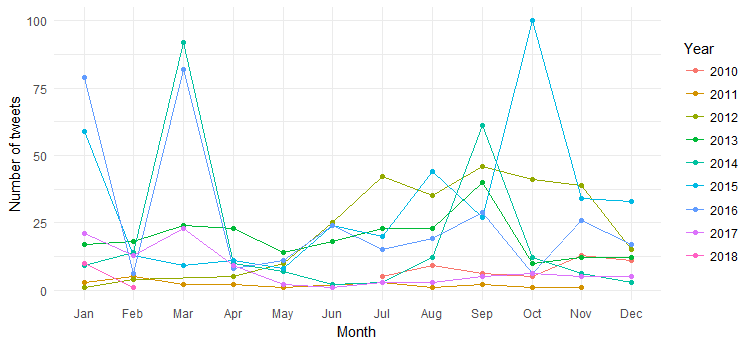
月ごとのつぶやき (2014 年 3 月、2016 年 3 月、2015 年 10 月のスパイク) の分裂は何年にもわたって見られますが、解釈は困難です。 では、年ごとのツイート数のみをプロットして、グラフを単純化してみましょう。
[コード言語=”r”]
ggplot(data = ew_tweets, aes(x = year(created_at))) +
geom_bar(aes(fill = ..count..)) +
xlab(“年”) + ylab(“ツイート数”) +
scale_x_continuous (休憩 = c(2010:2018)) +
theme_minimal() +
scale_fill_gradient(low = “cadetblue3”, high = “chartreuse4”)
[/コード]
結果のグラフは、彼女が 2015 年と 2016 年に最も活動的だったのに対し、2011 年は活動が最も少なかったことを示しています。
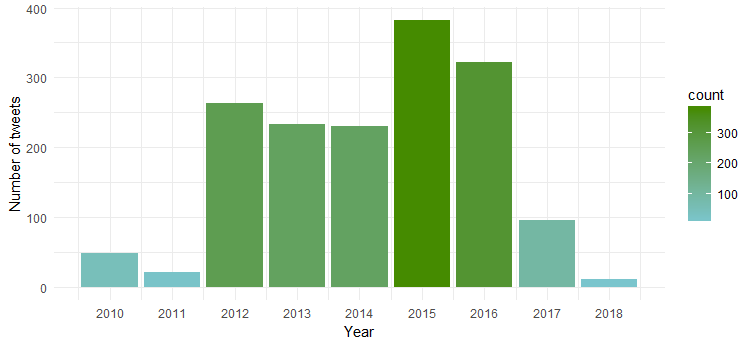
数か月にわたるツイートの頻度
次に、エマ・ワトソンの Twitter データを調べて、彼女が 1 年の月間で同じようにツイートするか、または彼女が最も多くツイートする特定の月があるかを調べてみましょう。 次のコードを使用してグラフを作成します。
[コード言語=”r”]
ggplot(data = ew_tweets, aes(x = month(created_at, label = TRUE))) +
geom_bar(aes(fill = ..count..)) +
xlab(“月”) + ylab(“ツイート数”) +
theme_minimal() +
scale_fill_gradient(low = “cadetblue3”, high = “chartreuse4”)
[/コード]
明らかに、彼女は「1 月」、「3 月」、「9 月」に最も活動的です。
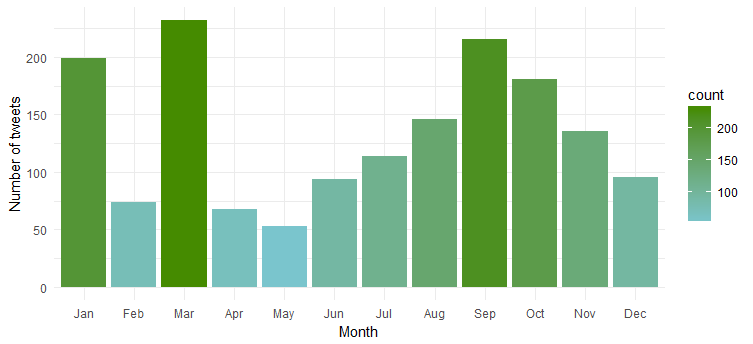
1 週間のツイート頻度
彼女が最も活発な特定の曜日はありますか? 次のコードを実行してチャートをプロットしましょう。
[コード言語=”r”]
ggplot(data = ew_tweets, aes(x = wday(created_at, label = TRUE))) +
geom_bar(aes(fill = ..count..)) +
xlab(“曜日”) + ylab(“ツイート数”) +
theme_minimal() +
scale_fill_gradient(low = “ターコイズ3”, high = “ダークグリーン”)
[/コード]
うーん…彼女は金曜日が一番活発です。 おそらくパーティーモードに入る準備ができていますか?
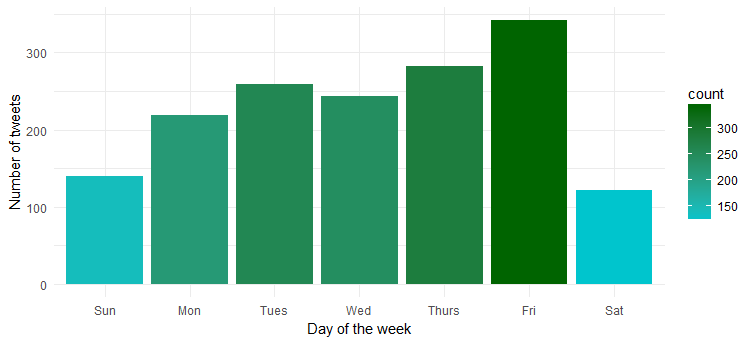
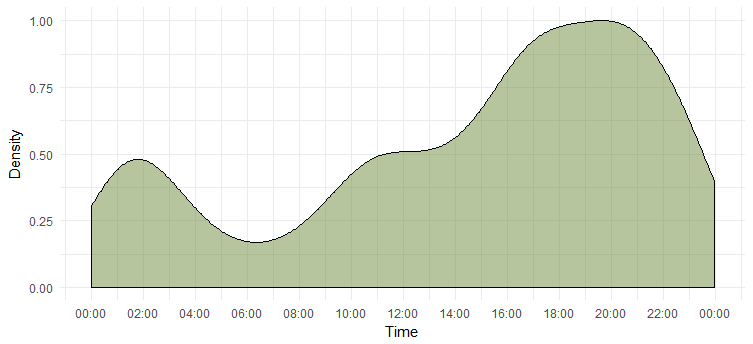
一日のつぶやき密度
最も活動的な日はわかりましたが、彼女が最も活動的な時間帯はわかりません。 次の図がその答えです。
[コード言語=”r”]
# 時刻を保存してフォーマットするパッケージ
install.packages(“hms”)
# 休憩時間とラベルを追加するパッケージ
install.packages(“スケール”)
ライブラリ(「hms」)
ライブラリ(「スケール」)
# タイムスタンプから時間、つまり時、分、秒のみを抽出する
ew_tweets$time <- hms::hms(second(ew_tweets$created_at),
分(ew_tweets$created_at)、
hour(ew_tweets$created_at))
# ggplot は hms と互換性がないため、POSIXct に変換
ew_tweets$time <- as.POSIXct(ew_tweets$time)
ggplot(データ = ew_tweets)+
geom_density(aes(x = 時間, y = ..スケーリングされた..),
fill=”darkolivegreen4″, アルファ=0.3) +
xlab(“時間”) + ylab(“密度”) +
scale_x_datetime(breaks = date_breaks(“2 時間”),
ラベル = date_format(“%H:%M”)) +
theme_minimal()
[/コード]

これは、彼女が午後 6 時から 8 時の間に最も活動的であることを示しています。タイムゾーンは UTC であることに注意してください (`unclass` 関数を使用して確認できます。Emma をツイートするときは、この点に注意してください。
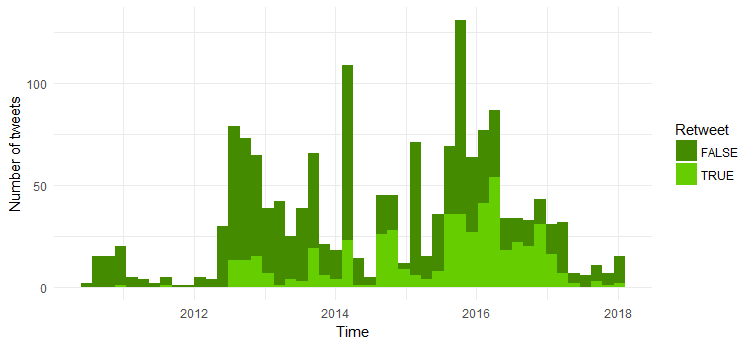
リツイート数とオリジナルツイート数の比較
次に、元のツイートとリツイートの数を比較します。 以下にコードを示します。
[コード言語=”r”]
ggplot(data = ew_tweets, aes(x = created_at, fill = is_retweet)) +
geom_histogram(bins=48) +
xlab(“時間”) + ylab(“ツイート数”) + theme_minimal() +
scale_fill_manual(values = c(“chartreuse4”, “chartreuse3”),
名前 = 「リツイート」)
[/コード]
ツイートの大半はオリジナルのツイートです。 2014年からリツイート数が増えているのは興味深い。
テキストマイニング
それでは、より興味深い領域に入りましょう。NLP を含むテキスト マイニング技術を実行して、次のことを調べます。
1.よく使うハッシュタグ
2. ツイートテキストのワードクラウド
3.感情分析
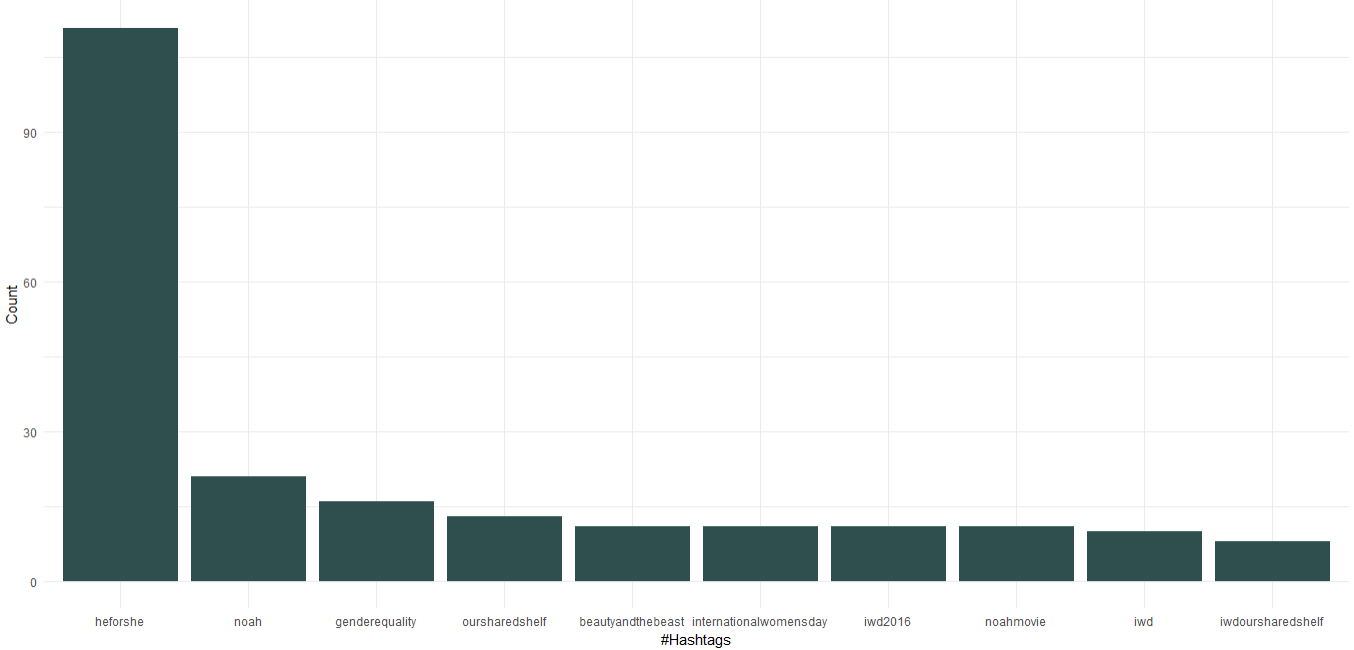
1.よく使うハッシュタグ
ダウンロードされたデータセットには、ハッシュタグを含む列が既に含まれています。 これを使用して、Emma が使用した上位 10 個のハッシュタグを見つけます。 以下は、ハッシュタグのグラフを作成するコードです。
[コード言語=”r”]
#データフレームを簡単に操作するためのパッケージ
install.packages(“dplyr”)
ライブラリ(“dplyr”)
# リストからハッシュタグを取得する
ew_tags_split <- unlist(strsplit(as.character(unlist(ew_tweets$hashtags)),'^c(|,|”|)'))
# 空白を取り除いてフォーマットするa
ew_tags <- sapply(ew_tags_split, function(y) nchar(trimws(y)) > 0 & !is.na(y))
ew_tag_df <- as_data_frame(table(tolower(ew_tags_split[ew_tags])))
ew_tag_df <- ew_tag_df[with(ew_tag_df,order(-n)),]
ew_tag_df <- ew_tag_df[1:10,]
ggplot(ew_tag_df, aes(x = reorder(Var1, -n), y=n)) +
geom_bar(stat="identity", fill="darkslategray")+
theme_minimal() +
xlab(“#ハッシュタグ”) + ylab(“カウント”)
[/コード]
UN Women の親善大使として、エマ・ワトソンが男女平等に焦点を当てた「HeForShe」キャンペーンを推進していることがわかります。 それとは別に、彼女は「Our Shared Shelf」と「International Women's Day」と呼ばれる読書クラブを宣伝しています。 映画では「ノア」「美女と野獣」がハッシュタグトップ10入り。
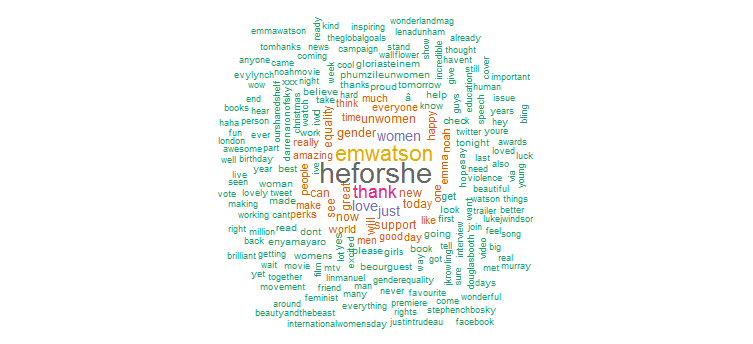
2.ワードクラウド
次に、ツイートのテキストを分析して、最も頻繁に使用される単語を見つけ、ワード クラウドを作成します。 次のコードを実行して続行します。
[コード言語=”r”]
#テキストマイニングとワードクラウドパッケージをインストール
install.packages(c(“tm”, “wordcloud”))
ライブラリ(「tm」)
ライブラリ(「ワードクラウド」)
tweet_text <- ew_tweets$text
#数字、句読点、リンク、英数字コンテンツの削除
tweet_text<- gsub('[[:digit:]]+', ”, tweet_text)
tweet_text<- gsub('[[:punct:]]+', ”, tweet_text)
tweet_text<- gsub(“http[[:alnum:]]*”, “”, tweet_text)
tweet_text<- gsub(“([[:alpha:]])1+”, “”, tweet_text)
#テキストコーパスの作成
docs <- Corpus(VectorSource(tweet_text))
# エンコーディングを UTF-8 に変換して、変な文字を処理する
docs <- tm_map(docs, function(x) iconv(enc2utf8(x), sub = “byte”))
# テキストを小文字に変換
docs <- tm_map(docs, content_transformer(tolower))
# 英語の一般的なストップワードの削除
docs <- tm_map(docs, removeWords, stopwords(“english”))
# 文字ベクトルとして指定されたストップワードの削除
docs <- tm_map(docs, removeWords, c(“amp”))
# 用語ドキュメント マトリックスの作成
tdm <- TermDocumentMatrix(ドキュメント)
# tdm を行列として定義
m <- as.matrix(tdm)
# 単語数を降順で取得
word_freqs = sort(rowSums(m), 減少=TRUE)
# 単語とその頻度でデータ フレームを作成する
ew_wf <- data.frame(word=names(word_freqs), freq=word_freqs)
# ワードクラウドのプロット
セット.シード(1234)
wordcloud(単語 = ew_wf$単語、頻度 = ew_wf$頻度、
min.freq = 1,scale=c(1.8,.5),
max.words=200、random.order=FALSE、rot.per=0.15、
colors=brewer.pal(8, "Dark2"))
[/コード]
明らかに、彼女は「HeforShe」キャンペーンのために大規模なプロモーションを行っています. 他によく使われる言葉は、「ありがとう」「愛」「女性」「ジェンダー」「UNWomen」など。 これは、彼女の Twitter での活動が女性の問題にかなり焦点を当てていることを示唆するハッシュタグと明らかに一致しています。
3.感情分析
感情の抽出とプロットには、 syuzhetパッケージを適用します。 このパッケージは、さまざまな単語をさまざまな感情 (喜び、恐怖、怒り、驚きなど) と感情の極性 (正/負) にマッピングする感情辞書に基づいています。 ツイートに含まれる単語に基づいて感情スコアを計算し、それをプロットする必要があります。
[コード言語=”r”]
install.packages(“シュゼット”)
図書館(シュゼット)
# ツイートを ASCII に変換して奇妙な文字を追跡する
tweet_text <- iconv(tweet_text, from=”UTF-8”, to=”ASCII”, sub=””)
# リツイートの削除
tweet_text<-gsub(“(RT|via)((?:bw*@w+)+)”,””,tweet_text)
# メンションの削除
tweet_text<-gsub(“@w+”,””,tweet_text)
ew_sentiment<-get_nrc_sentiment((tweet_text))
センチメントスコア<-data.frame(colSums(ew_sentiment[,]))
names(sentimentscores) <- 「スコア」
センチメントスコア <- cbind(“センチメント”=rownames(センチメントスコア),センチメントスコア)
行名 (センチメントスコア) <- NULL
ggplot(データ=センチメントスコア,aes(x=センチメント,y=スコア))+
geom_bar(aes(fill=感情),stat = “アイデンティティ”)+
テーマ(legend.position="なし")+
xlab(“センチメント”)+ylab(“スコア”)+
ggtitle(“スコアに基づく総感情”)+
theme_minimal()
[/コード]
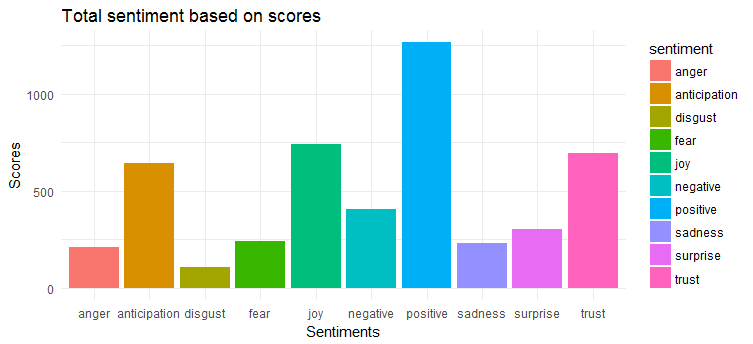
次のグラフは、ツイートの大部分が肯定的な感情であることを示しています。 最も表現された感情のトップ 3 は、「喜び」、「信頼」、「期待」です。
あなたに
この研究では、エマ・ワトソンが投稿したツイートのパターンと根底にあるテーマを理解するための探索的データ分析とテキストマイニング手法について説明しました。 さらに分析を実行して、頻繁に言及されている Twitter ユーザーを見つけ、ネットワーク グラフを作成し、トピック モデリングを使用してツイートを分類することができます。
このチュートリアルに従って、コメント セクションで調査結果を共有してください。
