
Découvrir les secrets du référencement : tout est sémantique pour la recherche Google
Publié: 2017-10-17Des jalons tels que Knowledge Graph, Hummingbird et RankBrain ont contribué à rapprocher Google de quelques pas pour devenir un moteur de recherche parfait. Les statistiques, les théories et structures sémantiques et l'apprentissage automatique jouent tous un rôle important. Dans le dernier Unwrapping the Secrets of SEO, l'auteur invité Olaf Kopp examine les aspects de la sémantique et de l'apprentissage automatique dans la recherche Google.

Dans le dernier épisode de Unwrapping the Secrets of SEO, j'ai exposé mon point de vue sur la façon dont Google interprète les requêtes de recherche et l'intention de l'utilisateur derrière elles. Il est maintenant temps d'examiner comment Google fait un si bon travail pour améliorer la précision de la recherche.
Recherche sémantique ou récupération d'informations statistiques ?
J'ai eu de nombreuses discussions animées (débat civilisé ?) Avec mon collègue SEO Jens Fauldrath sur la question de savoir si Google est vraiment un moteur de recherche sémantique.
Les résultats que Google présente à ses utilisateurs donnent certainement l'impression que le géant des moteurs de recherche a une compréhension sémantique très développée concernant les requêtes de recherche et les documents. Cependant, une grande partie de ce qui conduit à cette apparition est basée sur des méthodes statistiques, et non sur une véritable compréhension sémantique. Mais grâce aux structures sémantiques, en combinaison avec les statistiques et l'apprentissage automatique, Google est désormais en mesure de se rapprocher de la compréhension sémantique.
« Par exemple, nous constatons que des relations sémantiques utiles peuvent être automatiquement apprises à partir des statistiques des requêtes de recherche et des résultats correspondants, ou à partir des preuves accumulées de modèles de texte Web et de tableaux formatés, dans les deux cas sans avoir besoin de données annotées manuellement. ” Source : L'efficacité déraisonnable des données, IEEE Computer Society, 2009
Comment fonctionne Word2Vec
Pour le démontrer plus clairement, j'aborderai brièvement le travail d'analyse statistique de texte. Google utilise des analyses d'espace vectoriel pour l'évaluation de la pertinence et l'identification des relations. Un espace vectoriel se compose de points de données individuels qui peuvent être liés via des vecteurs dans l'espace vectoriel. L'angle entre les vecteurs nous renseigne sur les similitudes et/ou les relations entre les points de données. Plus l'angle est grand, moins il y a de similarité. Plus l'angle est petit, plus la similitude est grande. Pour l'analyse des composants principaux, par exemple, un vecteur est créé dans l'espace vectoriel à partir de la requête de recherche et de tous les documents pertinents disponibles. Pour ce processus dit de "word embedding", Google utilise Word2vec.
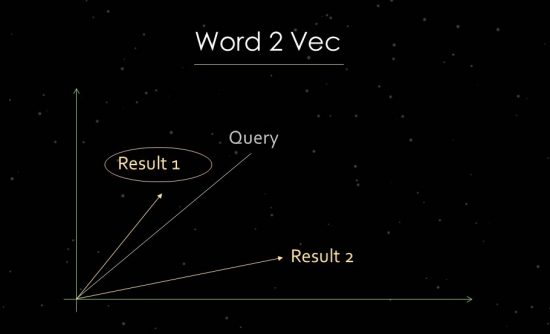
L'utilisation de la proximité des points de données entre eux permet de montrer les relations sémantiques entre eux. En règle générale, les vecteurs sont créés pour les requêtes de recherche et les documents qui peuvent être placés les uns par rapport aux autres. Une autre utilisation consiste à créer des vecteurs à partir d'un document et des termes qu'il contient afin d'identifier son concept ou son sujet. Il serait également possible de former des vecteurs à partir d'entités telles que des personnes, des marques, des entreprises ou des sujets.
Afin d'utiliser les analyses d'espace vectoriel, les documents doivent d'abord être indexés et mis en correspondance avec des concepts ou des domaines thématiques qui constituent ensuite le corpus thématique pertinent. Un procédé pour réaliser cette étape est l'indexation sémantique latente (LSI), qui permet de créer des espaces vectoriels offrant les meilleurs résultats en termes de précision et de rappel. En utilisant cette méthode, il est également possible d'effectuer une classification sémantique ou un regroupement de termes liés à un sujet.
Comment les requêtes de recherche peuvent être classées automatiquement
Dans le passé, le principal problème était le manque d'évolutivité car les requêtes de recherche devaient être classées manuellement. Voici les mots de l'ancienne vice-présidente de Google, Marissa Mayer, sur le sujet, tirés d'une interview de 2009 :

« Lorsque les gens parlent de recherche sémantique et du Web sémantique, ils veulent généralement dire quelque chose de très manuel, avec des cartes de diverses associations entre des mots et des choses comme ça. Nous pensons que vous pouvez atteindre un bien meilleur niveau de compréhension grâce à des données de correspondance de modèles, en construisant des systèmes à grande échelle. C'est ainsi que fonctionne le cerveau. C'est pourquoi vous avez toutes ces connexions floues, parce que le cerveau traite constamment beaucoup, beaucoup de données tout le temps… Le problème est que le langage change. Les pages Web changent. La façon dont les gens s'expriment change. Et toutes ces choses comptent en termes d'application de la recherche sémantique. C'est pourquoi il est préférable d'avoir une approche basée sur l'apprentissage automatique et qui change, itère et répond aux données. C'est une approche plus robuste. Cela ne veut pas dire que la recherche sémantique n'a aucun rôle dans la recherche. C'est juste que pour nous, nous préférons vraiment nous concentrer sur des choses qui peuvent évoluer. Si nous pouvions proposer une solution de recherche sémantique qui puisse évoluer, nous serions très enthousiastes à ce sujet. Pour l'instant, ce que nous constatons, c'est que beaucoup de nos méthodes se rapprochent de l'intelligence de la recherche sémantique, mais le font par d'autres moyens. Source : http://www.pcworld.com/article/181874/article.html
Une grande partie de ce que nous appelons la compréhension sémantique lorsque nous parlons de l'identification par Google de la signification d'une requête de recherche ou d'un document repose sur des méthodes statistiques telles que des analyses d'espace vectoriel ou des méthodes d'analyse statistique de texte telles que TF-IDF. À proprement parler, cela ne repose donc pas sur une véritable sémantique. Mais les résultats sont très proches de la compréhension sémantique. L'application accrue de l'apprentissage automatique - et les analyses plus détaillées que cela permet - rend l'interprétation sémantique des requêtes de recherche et des documents beaucoup plus facile.
La compréhension sémantique comme l'un des objectifs de Google
L'un des objectifs les plus importants de Google est de parvenir à une compréhension sémantique des termes de recherche et des documents indexés afin d'afficher des résultats de recherche plus pertinents. Une compréhension sémantique existe lorsqu'une requête (de recherche) et les termes qu'elle contient peuvent être compris sans ambiguïté. L'interprétation sans ambiguïté est souvent rendue difficile par des requêtes comprenant des termes à significations multiples, des termes inconnus du système, des formulations peu claires, une compréhension individuelle, etc.
Pour faciliter la compréhension, une analyse est effectuée des mots utilisés, de leur ordre et des contextes de leur sujet, de leur heure et de leur lieu. L'apprentissage automatique et/ou RankBrain permettent à Google d'utiliser des analyses de cluster pour créer automatiquement de nouvelles classes et leur attribuer des requêtes de recherche. Cela établit non seulement un haut niveau de détail, mais crée également une évolutivité et augmente les performances. La création de nouveaux espaces vectoriels pour les analyses d'espace vectoriel est également rendue possible.
De cette façon, les statistiques se combinent avec l'apprentissage automatique pour donner une interprétation de plus en plus sémantique qui se rapproche beaucoup d'une compréhension sémantique des requêtes de recherche et des documents. Google veut pouvoir recréer une véritable recherche sémantique à l'aide de méthodes statistiques et de machine learning. De plus, un élément central du moteur de recherche Google moderne, le Knowledge Graph, est également basé sur des structures sémantiques.
Dans la troisième partie de cette série d'articles sur la sémantique et l'apprentissage automatique de Google, Olaf Kopp se penchera sur les fondements de la sémantique : graphes, entités et ontologies.