
SEOの秘密を解き明かす:それはGoogle検索のすべての意味論です
公開: 2017-10-17ナレッジグラフ、ハミングバード、ランクブレインなどのマイルストーンは、Googleを完璧な検索エンジンに近づけるのに役立ちました。 統計、意味論と構造、機械学習はすべて重要な役割を果たします。 最新のUnwrappingtheSecrets of SEOでは、ゲスト著者のOlaf Koppが、Google検索でのセマンティクスと機械学習の側面を検証しています。

Unwrapping the Secrets of SEOの前回の記事では、Googleが検索クエリをどのように解釈するかとその背後にあるユーザーの意図についての私の見解を概説しました。 それでは、Googleが検索精度の向上にどのように優れているかを見てみましょう。
セマンティック検索または統計情報検索?
私は、Googleが本当にセマンティック検索エンジンであるかどうかについて、SEOの仲間であるJens Fauldrathと多くの白熱した議論(文明的な議論?)をしました。
Googleがユーザーに提示する結果は、検索エンジンの巨人が検索クエリとドキュメントに関して高度に発達したセマンティック理解を持っているように見えることを確かに示しています。 ただし、この外観につながるものの多くは、統計的手法に基づいており、真の意味論的理解に基づいていません。 しかし、セマンティック構造により、統計と機械学習を組み合わせることで、Googleはセマンティックの理解に近づくことができるようになりました。
「たとえば、有用なセマンティック関係は、検索クエリの統計と対応する結果から、またはWebベースのテキストパターンとフォーマットされたテーブルの蓄積された証拠から、どちらの場合も手動で注釈を付けたデータを必要とせずに自動的に学習できることがわかりました。 」 出典:データの不当な有効性、IEEE Computer Society、2009年
Word2Vecのしくみ
これをより明確に示すために、統計テキスト分析の作業を簡単に説明します。 Googleは、関連性の評価と関係の特定にベクトル空間分析を使用しています。 ベクトル空間は、ベクトル空間内のベクトルを介してリンクできる個々のデータポイントで構成されます。 ベクトル間の角度は、データポイント間の類似性および/または関係について教えてくれます。 角度が大きいほど、類似性は低くなります。 角度が小さいほど、類似性は高くなります。 たとえば、主要コンポーネントの分析では、検索クエリと利用可能なすべての関連ドキュメントからベクトル空間にベクトルが作成されます。 このいわゆる「単語の埋め込み」プロセスでは、GoogleはWord2vecを使用します。
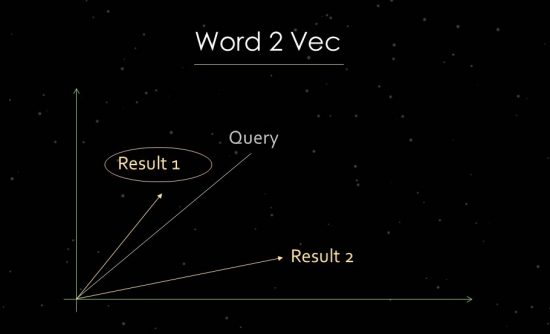
データポイントの相互の近接性を使用すると、それらの間の意味関係を示すことができます。 通常、ベクターは、相互に関連して配置できる検索クエリとドキュメント用に作成されます。 もう1つの使用法は、ドキュメントとその中の用語からベクトルを作成して、その概念またはトピックを識別することです。 人、ブランド、企業、トピックなどのエンティティからベクトルを形成することも可能です。
ベクトル空間分析を利用するには、最初にドキュメントにインデックスを付けて、関連するトピックコーパスを構成する概念またはトピック領域にマッピングする必要があります。 このステップを実行するためのプロセスは、潜在意味索引付け(LSI)です。これにより、適合率と再現率の点で最良の結果を提供するベクトル空間を作成できます。 この方法を使用すると、トピックに関連する用語の意味分類またはクラスタリングを実行することもできます。

検索クエリを自動的に分類する方法
これまでの主な問題は、検索クエリを手動で分類する必要があったため、スケーラビリティが不足していたことでした。 これらは、2009年のインタビューからの主題に関する元GoogleVPのマリッサメイヤーの言葉です。
「人々がセマンティック検索とセマンティックWebについて話すとき、それらは通常、単語とそのようなものの間のさまざまな関連のマップを備えた、非常に手動の何かを意味します。 大規模なシステムを構築し、パターンマッチングデータを使用することで、より深いレベルの理解を得ることができると思います。 それが脳の働きです。 脳は常に大量のデータを処理しているので、これらすべてのあいまいな接続があるのはそのためです…問題は言語が変化することです。 Webページが変更されます。 人々が自分自身を表現する方法は変化します。 そして、これらすべてのことは、セマンティック検索がどれだけうまく適用されるかという点で重要です。 そのため、機械学習に基づいており、データを変更、反復、応答するアプローチを採用することをお勧めします。 これは、より堅牢なアプローチです。 それは、セマンティック検索が検索に関与しないということではありません。 それは私たちにとって、スケーリングできるものに焦点を当てることを本当に好みます。 拡張可能なセマンティック検索ソリューションを考え出すことができれば、それについて非常に興奮するでしょう。 今のところ、私たちが目にしているのは、私たちのメソッドの多くがセマンティック検索のインテリジェンスを近似しているが、他の方法でそれを実行しているということです。」 出典:http://www.pcworld.com/article/181874/article.html
検索クエリまたはドキュメントの意味を識別するGoogleについて話すときにセマンティック理解と呼ぶものの多くは、ベクトル空間分析などの統計的手法またはTF-IDFなどの統計的テキスト分析手法に基づいています。 したがって、厳密に言えば、これは本物のセマンティクスに基づいていません。 しかし、結果は意味理解に非常に近くなります。 機械学習のアプリケーションの増加、およびこれにより可能になるより詳細な分析により、検索クエリとドキュメントのセマンティック解釈がはるかに簡単になります。
Googleの目標の1つとしての意味理解
Googleの最も重要な目標の1つは、より関連性の高い検索結果を表示するために、検索用語とインデックス付きドキュメントに関する意味理解を達成することです。 (検索)クエリとそれに含まれる用語を明確に理解できる場合、意味的理解が存在します。 複数の意味を持つ用語、システムによって未知の用語、不明瞭な言い回し、個人の理解などを含むクエリによって、明確な解釈が困難になることがよくあります。
理解を助けるために、使用されている単語、それらの順序、およびそれらのトピック、時間、場所のコンテキストの分析が行われます。 機械学習やRankBrainを使用すると、Googleはクラスター分析を使用して新しいクラスを自動的に作成し、それらに検索クエリを割り当てることができます。 これにより、高レベルの詳細が確立されるだけでなく、スケーラビリティが作成され、パフォーマンスが向上します。 ベクトル空間解析用の新しいベクトル空間の作成も可能になります。
このように、統計は機械学習と組み合わされて、検索クエリとドキュメントのセマンティックな理解に非常に近いセマンティックな解釈を提供します。 Googleは、統計的手法と機械学習の助けを借りて、真にセマンティックな検索を再現できるようにしたいと考えています。 さらに、最新のGoogle検索エンジンの中心的な要素であるナレッジグラフも、セマンティック構造に基づいています。
Googleのセマンティクスと機械学習に関するこのシリーズのパート3では、Olaf Koppがセマンティクスの基礎:グラフ、エンティティ、オントロジーについて説明します。