
Odkrywanie sekretów SEO: to wszystko semantyczne w wyszukiwarce Google
Opublikowany: 2017-10-17Kamienie milowe, takie jak Knowledge Graph, Hummingbird i RankBrain, pomogły Google o kilka kroków zbliżyć się do stania się doskonałą wyszukiwarką. Ważną rolę odgrywają statystyki, teorie i struktury semantyczne oraz uczenie maszynowe. W najnowszym Unwrapping the Secrets of SEO gościnny autor Olaf Kopp analizuje aspekty semantyki i uczenia maszynowego w wyszukiwarce Google.

W ostatniej części Unwrapping the Secrets of SEO przedstawiłem swój pogląd na to, jak Google interpretuje zapytania wyszukiwania i stojące za nimi intencje użytkownika. Teraz nadszedł czas, aby przyjrzeć się , jak Google wykonuje tak dobrą robotę w poprawianiu dokładności wyszukiwania.
Wyszukiwanie semantyczne czy pobieranie informacji statystycznych?
Miałem wiele gorących sporów (cywilizowanej debaty?) z innym SEO Jensem Fauldrathem o to, czy Google naprawdę jest semantyczną wyszukiwarką.
Wyniki, które Google prezentuje swoim użytkownikom, z pewnością sprawiają, że wygląda na to, że gigant wyszukiwarek ma wysoko rozwinięte rozumienie semantyczne dotyczące zapytań i dokumentów. Jednak wiele z tego, co prowadzi do tego pojawienia się, opiera się na metodach statystycznych, a nie na jakimkolwiek prawdziwym zrozumieniu semantycznym. Ale dzięki strukturom semantycznym, w połączeniu ze statystykami i uczeniem maszynowym, Google jest teraz w stanie zbliżyć się do zrozumienia semantycznego.
„Na przykład stwierdzamy, że użytecznych relacji semantycznych można automatycznie nauczyć się na podstawie statystyk zapytań wyszukiwania i odpowiadających im wyników lub ze zgromadzonych dowodów wzorców tekstowych opartych na sieci Web i sformatowanych tabel, w obu przypadkach bez konieczności wprowadzania ręcznie adnotowanych danych. ” Źródło: The Unreasonable Effectiveness of Data, IEEE Computer Society, 2009
Jak działa Word2Vec
Aby to wyraźniej pokazać, pokrótce przejdę do pracy nad statystyczną analizą tekstu. Google wykorzystuje analizy przestrzeni wektorowej do oceny trafności i identyfikacji relacji. Przestrzeń wektorowa składa się z pojedynczych punktów danych, które można połączyć za pomocą wektorów w przestrzeni wektorowej. Kąt między wektorami mówi nam o podobieństwach i/lub relacjach między punktami danych. Im większy kąt, tym mniejsze podobieństwo. Im mniejszy kąt, tym większe podobieństwo. Dla analizy głównych składowych, na przykład, tworzony jest wektor w przestrzeni wektorowej z zapytania wyszukiwania i wszystkich dostępnych odpowiednich dokumentów. W tym tak zwanym procesie „osadzania słów” Google używa Word2vec.
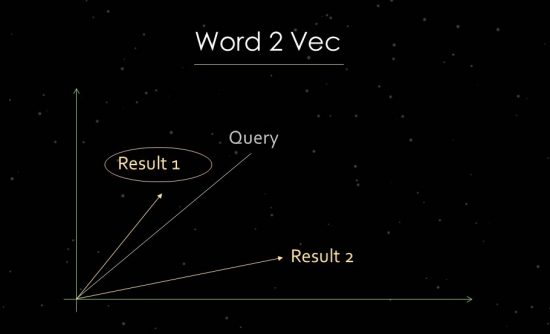
Wykorzystanie bliskości punktów danych względem siebie umożliwia ukazanie semantycznych relacji między nimi. Zazwyczaj wektory są tworzone dla zapytań wyszukiwania i dokumentów, które można umieszczać względem siebie. Innym zastosowaniem jest tworzenie wektorów z dokumentu i zawartych w nim terminów w celu zidentyfikowania jego koncepcji lub tematu. Możliwe byłoby również tworzenie wektorów z podmiotów takich jak ludzie, marki, firmy lub tematy.
Aby skorzystać z analizy przestrzeni wektorowej, dokumenty muszą najpierw zostać zindeksowane i zmapowane do pojęć lub obszarów tematycznych, które następnie tworzą odpowiedni korpus tematyczny. Procesem realizacji tego kroku jest Latent Semantic Indexing (LSI), które umożliwia tworzenie przestrzeni wektorowych zapewniających najlepsze wyniki pod względem precyzji i przywołania. Za pomocą tej metody można również przeprowadzić klasyfikację semantyczną lub grupowanie terminów związanych z tematem.

Jak wyszukiwane hasła mogą być automatycznie klasyfikowane
W przeszłości głównym problemem był brak skalowalności, ponieważ zapytania wyszukiwania musiały być klasyfikowane ręcznie. Oto słowa byłej wiceprezes Google Marissy Mayer na ten temat z wywiadu z 2009 roku:
„Kiedy ludzie mówią o wyszukiwaniu semantycznym i sieci semantycznej, zwykle mają na myśli coś, co jest bardzo ręczne, z mapami różnych powiązań między słowami i tego typu rzeczami. Uważamy, że można osiągnąć znacznie lepszy poziom zrozumienia poprzez dopasowywanie danych do wzorców, budując systemy na dużą skalę. Tak działa mózg. To dlatego masz te wszystkie rozmyte połączenia, ponieważ mózg nieustannie przetwarza mnóstwo danych… Problem w tym, że język się zmienia. Strony internetowe się zmieniają. Zmienia się sposób, w jaki ludzie wyrażają siebie. I wszystkie te rzeczy mają znaczenie, jeśli chodzi o to, jak dobrze stosuje się wyszukiwanie semantyczne. Dlatego lepiej jest mieć podejście oparte na uczeniu maszynowym, które zmienia, iteruje i reaguje na dane. To bardziej solidne podejście. Nie oznacza to, że wyszukiwanie semantyczne nie ma żadnego udziału w wyszukiwaniu. Po prostu dla nas naprawdę wolimy skupiać się na rzeczach, które można skalować. Gdybyśmy mogli wymyślić rozwiązanie wyszukiwania semantycznego, które można by skalować, bylibyśmy bardzo podekscytowani. Na razie widzimy, że wiele naszych metod przybliża inteligencję wyszukiwania semantycznego, ale robi to za pomocą innych środków”. Źródło: http://www.pcworld.com/article/181874/article.html
Wiele z tego, co nazywamy rozumieniem semantycznym, gdy mówimy o Google identyfikującym znaczenie zapytania lub dokumentu, opiera się na metodach statystycznych, takich jak analizy przestrzeni wektorowej lub metody statystycznej analizy tekstu, takie jak TF-IDF. Ściśle mówiąc, nie jest to zatem oparte na autentycznej semantyce. Ale wyniki są bardzo zbliżone do zrozumienia semantycznego. Zwiększone zastosowanie uczenia maszynowego – i bardziej szczegółowe analizy, które to umożliwia – znacznie ułatwia semantyczną interpretację zapytań i dokumentów.
Zrozumienie semantyczne jako jeden z celów Google
Jednym z najważniejszych celów Google jest osiągnięcie semantycznego zrozumienia wyszukiwanych terminów i indeksowanych dokumentów w celu wyświetlania bardziej trafnych wyników wyszukiwania. Rozumienie semantyczne istnieje wtedy, gdy zapytanie (wyszukiwane) i zawarte w nim terminy mogą być jednoznacznie zrozumiane. Jednoznaczną interpretację utrudniają często zapytania zawierające terminy o wielu znaczeniach, terminy nieznane systemowi, niejasne sformułowania, indywidualne rozumienie itp.
Aby ułatwić zrozumienie, przeprowadzana jest analiza użytych słów, ich kolejności oraz kontekstu ich tematu, czasu i miejsca. Uczenie maszynowe i/lub RankBrain umożliwiają Google korzystanie z analiz klastrowych w celu automatycznego tworzenia nowych klas i przypisywania do nich zapytań wyszukiwania. Zapewnia to nie tylko wysoki poziom szczegółowości, ale także zapewnia skalowalność i zwiększa wydajność. Możliwe jest również tworzenie nowych przestrzeni wektorowych do analiz przestrzeni wektorowych.
W ten sposób statystyki łączą się z uczeniem maszynowym, dając coraz bardziej semantyczną interpretację, która jest bardzo zbliżona do semantycznego rozumienia zapytań wyszukiwania i dokumentów. Google chce móc odtworzyć prawdziwie semantyczne wyszukiwanie za pomocą metod statystycznych i uczenia maszynowego. Ponadto centralny element nowoczesnej wyszukiwarki Google, Graf wiedzy, również opiera się na strukturach semantycznych.
W trzeciej części tej serii artykułów na temat semantyki Google i uczenia maszynowego Olaf Kopp przyjrzy się podstawom semantyki: wykresom, encji i ontologii.