
Membuka Rahasia SEO: Semuanya Semantik Untuk Pencarian Google
Diterbitkan: 2017-10-17Tonggak sejarah seperti Grafik Pengetahuan, Hummingbird dan RankBrain telah membantu membawa Google beberapa langkah lebih dekat untuk menjadi mesin pencari yang sempurna. Statistik, teori dan struktur semantik, dan pembelajaran mesin semuanya memainkan peran penting. Dalam Unwrapping the Secrets of SEO terbaru, penulis tamu Olaf Kopp meneliti aspek semantik dan pembelajaran mesin dalam pencarian Google.

Dalam angsuran terakhir dari Membuka Bungkus Rahasia SEO, saya menguraikan pandangan saya tentang bagaimana Google menafsirkan permintaan pencarian dan maksud pengguna di belakangnya. Sekarang saatnya untuk melihat bagaimana Google melakukan pekerjaan yang baik dalam meningkatkan akurasi pencarian.
Pencarian Semantik atau Pengambilan Informasi Statistik?
Saya memiliki banyak argumen panas (debat beradab?) Dengan sesama SEO Jens Fauldrath mengenai apakah Google benar-benar merupakan mesin pencari semantik.
Hasil yang ditampilkan Google kepada para penggunanya tentu saja membuat raksasa mesin pencari ini memiliki pemahaman semantik yang sangat berkembang terkait permintaan pencarian dan dokumen. Namun, banyak dari apa yang mengarah pada penampilan ini didasarkan pada metode statistik, dan bukan pada pemahaman semantik asli. Tetapi karena struktur semantik, dalam kombinasi dengan statistik dan pembelajaran mesin, Google sekarang dapat mendekati pemahaman semantik.
“Misalnya, kami menemukan bahwa hubungan semantik yang berguna dapat dipelajari secara otomatis dari statistik kueri pencarian dan hasil yang sesuai, atau dari akumulasi bukti pola teks berbasis Web dan tabel yang diformat, dalam kedua kasus tanpa memerlukan data yang dianotasi secara manual. ” Sumber: Efektivitas Data yang Tidak Masuk Akal, IEEE Computer Society, 2009
Cara Kerja Word2Vec
Untuk menunjukkan ini lebih jelas, saya akan secara singkat memasuki pekerjaan analisis teks statistik. Google menggunakan analisis ruang vektor untuk evaluasi relevansi dan identifikasi hubungan. Ruang vektor terdiri dari titik-titik data individual yang dapat dihubungkan melalui vektor-vektor dalam ruang vektor. Sudut antara vektor memberitahu kita tentang persamaan dan/atau hubungan antara titik data. Semakin besar sudutnya, semakin sedikit kesamaan yang ada. Semakin kecil sudutnya, semakin besar kemiripannya. Untuk analisis komponen utama, misalnya, vektor dibuat di ruang vektor dari permintaan pencarian dan semua dokumen relevan yang tersedia. Untuk apa yang disebut proses “penyematan kata” ini, Google menggunakan Word2vec.
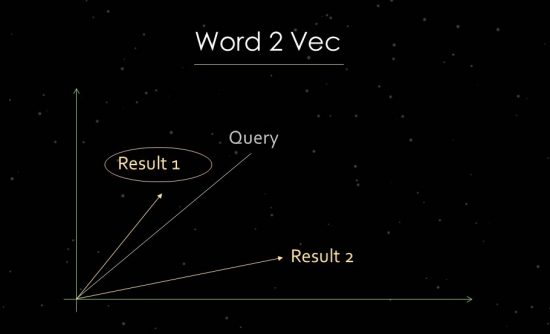
Menggunakan kedekatan titik data satu sama lain memungkinkan untuk menunjukkan hubungan semantik di antara mereka. Biasanya, vektor dibuat untuk kueri pencarian dan dokumen yang dapat ditempatkan dalam hubungan satu sama lain. Penggunaan lain adalah membuat vektor dari dokumen dan istilah di dalamnya untuk mengidentifikasi konsep atau topiknya. Dimungkinkan juga untuk membentuk vektor dari entitas seperti orang, merek, perusahaan, atau topik.
Untuk memanfaatkan analisis ruang vektor, dokumen pertama-tama perlu diindeks dan dipetakan ke konsep atau area topik yang kemudian membentuk korpus topikal yang relevan. Proses untuk melakukan langkah ini adalah Latent Semantic Indexing (LSI), yang memungkinkan untuk membuat ruang vektor yang memberikan hasil terbaik dalam hal presisi dan recall. Dengan menggunakan metode ini juga dimungkinkan untuk melakukan klasifikasi semantik atau pengelompokan istilah yang terkait dengan suatu topik.
Bagaimana Kueri Pencarian Dapat Diklasifikasikan Secara Otomatis
Di masa lalu, masalah utama adalah kurangnya skalabilitas karena permintaan pencarian harus diklasifikasikan secara manual. Ini adalah kata-kata mantan Wakil Presiden Google Marissa Mayer tentang masalah ini dari wawancara tahun 2009:

“Ketika orang berbicara tentang pencarian semantik dan Web semantik, mereka biasanya berarti sesuatu yang sangat manual, dengan peta berbagai asosiasi antara kata-kata dan hal-hal seperti itu. Kami pikir Anda dapat mencapai tingkat pemahaman yang jauh lebih baik melalui data pencocokan pola, membangun sistem skala besar. Begitulah cara kerja otak. Itulah mengapa Anda memiliki semua koneksi kabur ini, karena otak terus-menerus memproses banyak dan banyak data sepanjang waktu… Masalahnya adalah bahasa berubah. Halaman web berubah. Cara orang mengekspresikan diri berubah. Dan semua hal itu penting dalam hal seberapa baik pencarian semantik berlaku. Itulah mengapa lebih baik memiliki pendekatan yang didasarkan pada pembelajaran mesin dan yang mengubah, mengulangi, dan merespons data. Itu pendekatan yang lebih kuat. Itu tidak berarti bahwa pencarian semantik tidak memiliki bagian dalam pencarian. Hanya saja bagi kami, kami memang lebih suka fokus pada hal-hal yang bisa scale. Jika kami dapat menemukan solusi pencarian semantik yang dapat diskalakan, kami akan sangat senang dengan hal itu. Untuk saat ini, apa yang kami lihat adalah bahwa banyak metode kami mendekati kecerdasan pencarian semantik tetapi melakukannya melalui cara lain.” Sumber: http://www.pcworld.com/article/181874/article.html
Banyak dari apa yang kita sebut pemahaman semantik ketika kita berbicara tentang Google yang mengidentifikasi arti dari permintaan pencarian atau dokumen dibangun di atas metode statistik seperti analisis ruang vektor atau metode analisis teks statistik seperti TF-IDF. Sebenarnya, ini karena itu tidak didasarkan pada semantik asli. Tetapi hasilnya sangat mendekati pemahaman semantik. Peningkatan penerapan pembelajaran mesin – dan analisis yang lebih mendetail yang dimungkinkan – membuat interpretasi semantik dari kueri penelusuran dan dokumen menjadi lebih mudah.
Pemahaman Semantik sebagai salah satu Tujuan Google
Salah satu tujuan terpenting Google adalah mencapai pemahaman semantik mengenai istilah pencarian dan dokumen yang diindeks untuk menampilkan hasil pencarian yang lebih relevan. Pemahaman semantik ada ketika permintaan (pencarian) dan istilah yang terkandung di dalamnya dapat dipahami dengan jelas. Interpretasi yang tidak ambigu sering dibuat sulit oleh pertanyaan termasuk istilah dengan banyak arti, istilah yang tidak diketahui oleh sistem, ungkapan yang tidak jelas, pemahaman individu, dll.
Untuk membantu pemahaman, analisis dilakukan terhadap kata-kata yang digunakan, urutannya, dan konteks topik, waktu, dan lokasinya. Pembelajaran mesin dan/atau RankBrain memungkinkan Google menggunakan analisis klaster untuk membuat kelas baru secara otomatis dan menetapkan kueri penelusuran ke kelas tersebut. Ini tidak hanya menetapkan tingkat detail yang tinggi, tetapi juga menciptakan skalabilitas dan meningkatkan kinerja. Penciptaan ruang vektor baru untuk analisis ruang vektor juga dimungkinkan.
Dengan cara ini, statistik digabungkan dengan pembelajaran mesin untuk memberikan interpretasi semantik yang semakin mendekati pemahaman semantik kueri dan dokumen penelusuran. Google ingin dapat membuat ulang pencarian semantik yang sesungguhnya dengan bantuan metode statistik dan pembelajaran mesin. Selanjutnya, elemen sentral dari mesin pencari Google modern, Grafik Pengetahuan, juga didasarkan pada struktur semantik.
Di bagian ketiga dari seri artikel tentang semantik dan pembelajaran mesin Google ini, Olaf Kopp akan melihat Dasar-dasar Semantik: Grafik, Entitas, dan Ontologi.