
SEO'nun Sırlarını Çözmek: Google Arama İçin Her Şey Anlamsaldır
Yayınlanan: 2017-10-17Bilgi Grafiği, Hummingbird ve RankBrain gibi kilometre taşları, Google'ı mükemmel bir arama motoru olmaya birkaç adım daha yaklaştırdı. İstatistikler, anlamsal teoriler ve yapılar ve makine öğrenimi önemli bir rol oynamaktadır. Konuk yazar Olaf Kopp , SEO'nun Sırlarını Açmak'ın son makalesinde, Google aramada anlambilim ve makine öğreniminin özelliklerini inceliyor.

Unwrapping the Secrets of SEO'nun son bölümünde, Google'ın arama sorgularını nasıl yorumladığı ve bunların arkasındaki kullanıcının niyetiyle ilgili görüşümü özetledim. Şimdi, Google'ın arama doğruluğunu iyileştirmede nasıl bu kadar iyi bir iş çıkardığına bakmanın zamanı geldi.
Semantik Arama mı yoksa İstatistiksel Bilgi Erişimi mi?
Google'ın gerçekten semantik bir arama motoru olup olmadığı konusunda SEO arkadaşım Jens Fauldrath ile birçok hararetli tartışma yaşadım (medeni tartışma?).
Google'ın kullanıcılarına sunduğu sonuçlar, arama motoru devinin arama sorguları ve belgeler konusunda oldukça gelişmiş bir semantik anlayışa sahip olduğunu kesinlikle gösteriyor. Bununla birlikte, bu görünüme yol açan şeylerin çoğu, herhangi bir gerçek anlamsal anlayışa değil, istatistiksel yöntemlere dayanmaktadır. Ancak, istatistik ve makine öğrenimi ile birlikte anlamsal yapılar sayesinde, Google artık anlamsal anlayışa yaklaşabilmektedir.
"Örneğin, yararlı semantik ilişkilerin, arama sorgularının istatistiklerinden ve karşılık gelen sonuçlardan veya Web tabanlı metin kalıplarının ve biçimlendirilmiş tabloların birikmiş kanıtlarından, her iki durumda da, manuel olarak herhangi bir açıklama eklenmiş verilere ihtiyaç duymadan otomatik olarak öğrenilebileceğini bulduk. ” Kaynak: The Unresonable Effity of Data, IEEE Computer Society, 2009
Word2Vec Nasıl Çalışır?
Bunu daha açık bir şekilde göstermek için istatistiksel metin analizi çalışmasına kısaca gireceğim. Google, alaka düzeyinin değerlendirilmesi ve ilişkilerin tanımlanması için vektör uzayı analizlerini kullanır. Bir vektör uzayı, vektör uzayındaki vektörler aracılığıyla bağlanabilen bireysel veri noktalarından oluşur. Vektörler arasındaki açı bize veri noktaları arasındaki benzerlikler ve/veya ilişkiler hakkında bilgi verir. Açı ne kadar büyük olursa, benzerlik o kadar az olur. Açı ne kadar küçük olursa, benzerlik o kadar büyük olur. Ana bileşenlerin analizi için, örneğin, vektör uzayında arama sorgusu ve mevcut tüm ilgili belgelerden bir vektör oluşturulur. Bu sözde "kelime yerleştirme" işlemi için Google, Word2vec'i kullanır.
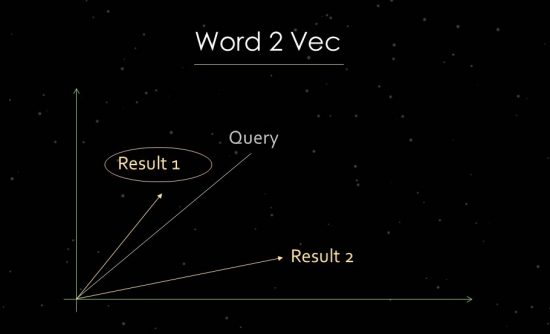
Veri noktalarının birbirine yakınlığını kullanmak, aralarındaki anlamsal ilişkileri göstermeyi mümkün kılar. Tipik olarak vektörler, arama sorguları ve birbirleriyle ilişkili olarak yerleştirilebilen belgeler için oluşturulur. Başka bir kullanım, bir belgeden ve içindeki terimlerden, onun kavramını veya konusunu belirlemek için vektörler oluşturmaktır. Kişiler, markalar, şirketler veya konular gibi varlıklardan vektörler oluşturmak da mümkün olacaktır.
Vektör uzayı analizlerinden faydalanmak için, belgelerin önce indekslenmesi ve ardından ilgili topikal korpusu oluşturan kavramlar veya konu alanları ile eşlenmesi gerekir. Bu adımı gerçekleştirmek için bir süreç, kesinlik ve geri çağırma açısından en iyi sonuçları sağlayan vektör uzayları yaratmayı mümkün kılan Gizli Semantik İndekslemedir (LSI). Bu yöntemi kullanarak, bir konuyla ilgili terimlerin anlamsal sınıflandırmasını veya kümelenmesini yapmak da mümkündür.

Arama Sorguları Otomatik Olarak Nasıl Sınıflandırılabilir?
Geçmişte, arama sorgularının manuel olarak sınıflandırılması gerektiğinden temel sorun ölçeklenebilirlik eksikliğiydi. Bunlar, eski Google Başkan Yardımcısı Marissa Mayer'in 2009 röportajından konuyla ilgili sözleri:
"İnsanlar semantik arama ve semantik Web hakkında konuştuklarında, genellikle çok manuel olan, kelimeler ve bunun gibi şeyler arasındaki çeşitli çağrışımların haritalarını içeren bir şeyi kastediyorlar. Model eşleştirme verileriyle, büyük ölçekli sistemler kurarak çok daha iyi bir anlayış düzeyine ulaşabileceğinizi düşünüyoruz. Beyin böyle çalışır. İşte bu yüzden tüm bu belirsiz bağlantılara sahipsiniz, çünkü beyin sürekli olarak çok ve çok sayıda veri işliyor… Sorun, dilin değişmesidir. Web sayfaları değişir. İnsanların kendilerini ifade etme biçimleri değişir. Ve tüm bunlar, anlamsal aramanın ne kadar iyi uygulandığı açısından önemlidir. Bu nedenle, makine öğrenimini temel alan ve verileri değiştiren, yineleyen ve yanıtlayan bir yaklaşıma sahip olmak daha iyidir. Bu daha sağlam bir yaklaşım. Bu, anlamsal aramanın aramada hiçbir yeri olmadığı anlamına gelmez. Sadece bizim için ölçeklenebilecek şeylere odaklanmayı tercih ediyoruz. Ölçeklenebilen bir anlamsal arama çözümü bulabilirsek, bunun için çok heyecanlanırdık. Şimdilik, birçok yöntemimizin anlamsal aramanın zekasına yaklaştığını, ancak bunu başka yollarla yaptığını görüyoruz.” Kaynak: http://www.pcworld.com/article/181874/article.html
Google'ın bir arama sorgusunun veya belgenin anlamını belirlemesinden bahsettiğimizde anlamsal anlama dediğimiz şeylerin çoğu, vektör uzayı analizleri gibi istatistiksel yöntemler veya TF-IDF gibi istatistiksel metin analizi yöntemleri üzerine kuruludur. Kesin olarak söylemek gerekirse, bu nedenle gerçek anlambilime dayalı değildir. Ancak sonuçlar anlamsal anlayışa çok yaklaşıyor. Artan makine öğrenimi uygulaması - ve bunun sağladığı daha ayrıntılı analizler - arama sorgularının ve belgelerin anlamsal yorumunu çok daha kolay hale getirir.
Google'ın Hedeflerinden Biri Olarak Semantik Anlama
Google'ın en önemli hedeflerinden biri, daha alakalı arama sonuçları görüntülemek için arama terimleri ve dizine eklenen belgelerle ilgili anlamsal anlayışa ulaşmaktır. Bir (arama) sorgusu ve içerdiği terimler açık bir şekilde anlaşılabildiğinde anlamsal bir anlayış vardır. Belirsiz yorumlama genellikle birden çok anlama sahip terimler, sistem tarafından bilinmeyen terimler, belirsiz ifadeler, bireysel anlama vb. içeren sorgular tarafından zorlaştırılır.
Anlamaya yardımcı olmak için, kullanılan kelimelerin, sıralarının ve konularının, zamanlarının ve yerlerinin bağlamlarının analizi yapılır. Makine öğrenimi ve/veya RankBrain, Google'ın otomatik olarak yeni sınıflar oluşturmak ve bunlara arama sorguları atamak için küme analizlerini kullanmasını sağlar. Bu, yalnızca yüksek düzeyde ayrıntı oluşturmakla kalmaz, aynı zamanda ölçeklenebilirlik yaratır ve performansı artırır. Vektör uzayı analizleri için yeni vektör uzaylarının oluşturulması da mümkün kılınmıştır.
Bu şekilde, istatistikler, arama sorguları ve belgelerin anlamsal olarak anlaşılmasına çok yaklaşan, giderek daha fazla anlamsal bir yorum sağlamak için makine öğrenimi ile birleşir. Google, istatistiksel yöntemler ve makine öğrenimi yardımıyla gerçekten anlamsal bir aramayı yeniden oluşturabilmek istiyor. Ayrıca, modern Google arama motorunun merkezi bir unsuru olan Bilgi Grafiği de anlamsal yapılara dayanmaktadır.
Google'ın anlambilimi ve makine öğrenimi hakkındaki bu makale dizisinin üçüncü bölümünde Olaf Kopp , Anlambilimin Temelleri: Grafikler, Varlıklar ve Ontolojiler'e bakacaktır.