
Enthüllen Sie die Geheimnisse von SEO: Es ist alles semantisch für die Google-Suche
Veröffentlicht: 2017-10-17Meilensteine wie der Knowledge Graph, Hummingbird und RankBrain haben dazu beigetragen, Google dem Weg zur perfekten Suchmaschine ein paar Schritte näher zu bringen. Dabei spielen Statistiken, semantische Theorien und Strukturen sowie maschinelles Lernen eine wichtige Rolle. Im aktuellen Unwrapping the Secrets of SEO untersucht Gastautor Olaf Kopp Aspekte der Semantik und des maschinellen Lernens in der Google-Suche.

In der letzten Folge von Unwrapping the Secrets of SEO habe ich meine Ansicht darüber dargelegt, wie Google Suchanfragen und die dahinter stehende Benutzerabsicht interpretiert. Jetzt ist es an der Zeit, einen Blick darauf zu werfen, warum Google so gute Arbeit bei der Verbesserung der Suchgenauigkeit leistet.
Semantische Suche oder statistische Informationsbeschaffung?
Ich hatte viele hitzige Auseinandersetzungen (zivilisierte Debatten?) mit SEO-Kollegen Jens Fauldrath darüber, ob Google wirklich eine semantische Suchmaschine ist.
Die Ergebnisse, die Google seinen Nutzern präsentiert, lassen durchaus den Eindruck entstehen, dass der Suchmaschinengigant über ein hoch entwickeltes semantisches Verständnis für Suchanfragen und Dokumente verfügt. Vieles, was zu diesem Erscheinungsbild führt, basiert jedoch auf statistischen Methoden und nicht auf einem echten semantischen Verständnis. Aber durch semantische Strukturen in Kombination mit Statistik und maschinellem Lernen ist Google nun in der Lage, dem semantischen Verständnis nahe zu kommen.
„Zum Beispiel stellen wir fest, dass nützliche semantische Beziehungen automatisch aus den Statistiken von Suchanfragen und den entsprechenden Ergebnissen oder aus den gesammelten Beweisen von webbasierten Textmustern und formatierten Tabellen gelernt werden können, in beiden Fällen, ohne dass manuell annotierte Daten erforderlich sind. ” Quelle: The Unreasonable Effectiveness of Data, IEEE Computer Society, 2009
Wie Word2Vec funktioniert
Um dies deutlicher zu demonstrieren, werde ich kurz auf die Arbeit der statistischen Textanalyse eingehen. Google verwendet Vektorraumanalysen zur Bewertung der Relevanz und zur Identifizierung von Zusammenhängen. Ein Vektorraum besteht aus einzelnen Datenpunkten, die über Vektoren im Vektorraum verknüpft werden können. Der Winkel zwischen den Vektoren sagt uns etwas über Ähnlichkeiten und/oder Beziehungen zwischen Datenpunkten. Je größer der Winkel, desto geringer ist die Ähnlichkeit. Je kleiner der Winkel, desto größer die Ähnlichkeit. Für die Analyse der Hauptkomponenten wird beispielsweise aus der Suchanfrage und allen verfügbaren relevanten Dokumenten ein Vektor im Vektorraum erstellt. Für dieses sogenannte „Word Embedding“-Verfahren verwendet Google Word2vec.
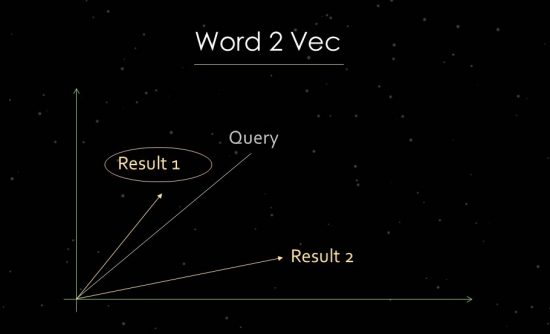
Die Nutzung der Nähe von Datenpunkten zueinander ermöglicht es, die semantischen Beziehungen zwischen ihnen aufzuzeigen. Typischerweise werden Vektoren für Suchanfragen und Dokumente erstellt, die zueinander in Beziehung gesetzt werden können. Eine andere Verwendung besteht darin, Vektoren aus einem Dokument und den darin enthaltenen Begriffen zu erstellen, um sein Konzept oder Thema zu identifizieren. Auch die Bildung von Vektoren aus Entitäten wie Personen, Marken, Unternehmen oder Themen wäre möglich.
Um Vektorraumanalysen nutzen zu können, müssen Dokumente zunächst indiziert und Konzepten oder Themenbereichen zugeordnet werden, die dann das relevante Themenkorpus bilden. Ein Verfahren zur Durchführung dieses Schritts ist Latent Semantic Indexing (LSI), das es ermöglicht, Vektorräume zu erstellen, die die besten Ergebnisse in Bezug auf Genauigkeit und Abruf liefern. Auch eine semantische Klassifikation oder Clusterung von themenbezogenen Begriffen ist mit dieser Methode möglich.

Wie Suchanfragen automatisch klassifiziert werden können
In der Vergangenheit war das Hauptproblem die mangelnde Skalierbarkeit, da Suchanfragen manuell klassifiziert werden mussten. Dies sind die Worte der ehemaligen Google-Vizepräsidentin Marissa Mayer zu diesem Thema aus einem Interview von 2009:
„Wenn Leute über semantische Suche und das semantische Web sprechen, meinen sie normalerweise etwas, das sehr manuell ist, mit Karten verschiedener Assoziationen zwischen Wörtern und ähnlichen Dingen. Wir glauben, dass Sie durch Mustervergleichsdaten und den Aufbau großer Systeme zu einem viel besseren Verständnis gelangen können. So funktioniert das Gehirn. Deshalb haben Sie all diese unscharfen Verbindungen, weil das Gehirn ständig und ständig viele, viele Daten verarbeitet … Das Problem ist, dass sich die Sprache ändert. Webseiten ändern sich. Wie sich Menschen ausdrücken, ändert sich. Und all diese Dinge spielen eine Rolle, wenn es darum geht, wie gut die semantische Suche funktioniert. Deshalb ist es besser, einen Ansatz zu haben, der auf maschinellem Lernen basiert und die Daten ändert, iteriert und darauf reagiert. Das ist ein robusterer Ansatz. Das heißt nicht, dass die semantische Suche keinen Anteil an der Suche hat. Es ist nur so, dass wir uns wirklich lieber auf Dinge konzentrieren, die skalierbar sind. Wenn wir eine semantische Suchlösung entwickeln könnten, die skalierbar ist, würden wir uns sehr darüber freuen. Im Moment sehen wir, dass viele unserer Methoden der Intelligenz der semantischen Suche nahekommen, dies aber auf andere Weise tun.“ Quelle: http://www.pcworld.com/article/181874/article.html
Vieles von dem, was wir semantisches Verständnis nennen, wenn wir davon sprechen, dass Google die Bedeutung einer Suchanfrage oder eines Dokuments erkennt, basiert auf statistischen Methoden wie Vektorraumanalysen oder Methoden der statistischen Textanalyse wie TF-IDF. Streng genommen liegt dem also keine echte Semantik zugrunde. Aber die Ergebnisse kommen dem semantischen Verständnis sehr nahe. Der verstärkte Einsatz von maschinellem Lernen – und die dadurch ermöglichten detaillierteren Analysen – erleichtert die semantische Interpretation von Suchanfragen und Dokumenten erheblich.
Semantisches Verstehen als eines der Ziele von Google
Eines der wichtigsten Ziele von Google ist es, ein semantisches Verständnis von Suchbegriffen und indexierten Dokumenten zu erreichen, um relevantere Suchergebnisse anzuzeigen. Ein semantisches Verständnis liegt vor, wenn eine (Such-)Anfrage und die darin enthaltenen Begriffe eindeutig verstanden werden können. Eine eindeutige Interpretation wird oft durch Abfragen mit Begriffen mit mehreren Bedeutungen, dem System unbekannte Begriffe, unklare Formulierungen, individuelles Verständnis usw. erschwert.
Um das Verständnis zu unterstützen, werden die verwendeten Wörter, ihre Reihenfolge und der Kontext ihres Themas, ihrer Zeit und ihres Ortes analysiert. Machine Learning und/oder RankBrain ermöglichen es Google, durch Clusteranalysen automatisch neue Klassen zu erstellen und diesen Suchanfragen zuzuordnen. Dies stellt nicht nur einen hohen Detaillierungsgrad her, sondern schafft auch Skalierbarkeit und erhöht die Performance. Auch die Erstellung neuer Vektorräume für Vektorraumanalysen wird ermöglicht.
Statistik verbindet sich so mit maschinellem Lernen zu einer zunehmend semantischen Interpretation, die einem semantischen Verständnis von Suchanfragen und Dokumenten sehr nahe kommt. Google will mit Hilfe von statistischen Methoden und maschinellem Lernen eine wirklich semantische Suche nachbilden können. Darüber hinaus basiert auch ein zentrales Element der modernen Google-Suchmaschine, der Knowledge Graph, auf semantischen Strukturen.
Im dritten Teil dieser Artikelserie zu Googles Semantik und maschinellem Lernen befasst sich Olaf Kopp mit den Grundlagen der Semantik: Graphen, Entitäten und Ontologien.