
SEO의 비밀 풀기: Google 검색의 모든 의미
게시 됨: 2017-10-17Knowledge Graph, Hummingbird 및 RankBrain과 같은 이정표는 Google이 완벽한 검색 엔진이 되는 데 몇 걸음 더 다가가는 데 도움이 되었습니다. 통계, 의미론적 이론과 구조, 기계 학습은 모두 중요한 역할을 합니다. 최신 Unwrapping Secrets of SEO에서 게스트 저자 Olaf Kopp은 Google 검색에서 의미론과 기계 학습의 측면을 조사합니다.

Unwrapping the Secrets of SEO의 마지막 기사에서 저는 Google이 검색어를 해석하는 방법과 검색어 이면의 사용자 의도에 대해 설명했습니다. 이제 Google이 검색 정확도를 개선하는 데 얼마나 훌륭한 역할을 하는지 살펴볼 때입니다.
의미 검색 또는 통계 정보 검색?
나는 Google이 정말로 의미 체계 검색 엔진인지에 대해 동료 SEO Jens Fauldrath와 열띤 논쟁(문명적인 논쟁?)을 많이 했습니다.
Google이 사용자에게 제공하는 결과는 확실히 검색 엔진 대기업이 검색 쿼리 및 문서에 대해 고도로 발달된 의미론적 이해를 갖고 있는 것처럼 보이게 만듭니다. 그러나 이러한 출현으로 이어지는 대부분은 진정한 의미론적 이해가 아니라 통계적 방법에 기반을 두고 있습니다. 그러나 의미 구조로 인해 통계 및 기계 학습과 함께 Google은 이제 의미론적 이해에 가까워질 수 있습니다.
"예를 들어, 우리는 수동으로 주석을 추가한 데이터가 필요 없이 두 경우 모두 검색 쿼리 및 해당 결과의 통계 또는 웹 기반 텍스트 패턴 및 형식이 지정된 테이블의 축적된 증거에서 유용한 의미론적 관계를 자동으로 학습할 수 있음을 발견했습니다. " 출처: 데이터의 불합리한 효율성, IEEE 컴퓨터 학회, 2009
Word2Vec 작동 방식
이를 보다 명확하게 설명하기 위해 통계적 텍스트 분석 작업에 대해 간략하게 설명하겠습니다. Google은 관련성을 평가하고 관계를 식별하기 위해 벡터 공간 분석을 사용합니다. 벡터 공간은 벡터 공간의 벡터를 통해 연결할 수 있는 개별 데이터 포인트로 구성됩니다. 벡터 사이의 각도는 데이터 포인트 간의 유사성 및/또는 관계에 대해 알려줍니다. 각도가 클수록 유사성이 적습니다. 각도가 작을수록 유사도가 커집니다. 예를 들어 주요 구성 요소의 분석을 위해 검색 쿼리 및 사용 가능한 모든 관련 문서에서 벡터 공간에 벡터가 생성됩니다. 이 소위 "단어 임베딩" 프로세스를 위해 Google은 Word2vec를 사용합니다.
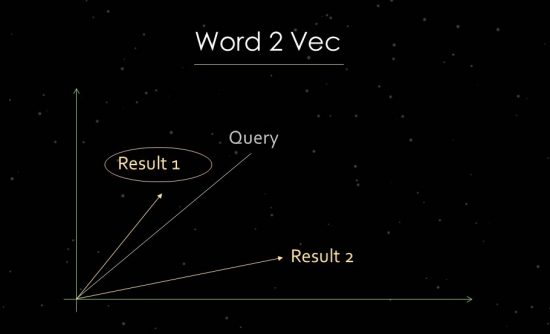
서로에 대한 데이터 포인트의 근접성을 사용하면 이들 간의 의미론적 관계를 표시할 수 있습니다. 일반적으로 벡터는 서로 관련하여 배치할 수 있는 검색 쿼리 및 문서에 대해 생성됩니다. 또 다른 사용법은 문서의 개념이나 주제를 식별하기 위해 문서와 문서 내의 용어에서 벡터를 만드는 것입니다. 사람, 브랜드, 회사 또는 주제와 같은 엔터티에서 벡터를 형성하는 것도 가능합니다.
벡터 공간 분석을 사용하려면 먼저 문서를 색인화하고 관련 주제 말뭉치를 구성하는 개념 또는 주제 영역에 매핑해야 합니다. 이 단계를 수행하는 프로세스는 LSI(Latent Semantic Indexing)로, 정밀도와 재현율 측면에서 최상의 결과를 제공하는 벡터 공간을 생성할 수 있습니다. 이 방법을 사용하면 주제와 관련된 용어의 의미 분류 또는 클러스터링도 수행할 수 있습니다.

검색어를 자동으로 분류하는 방법
과거에는 검색어를 수동으로 분류해야 했기 때문에 확장성 부족이 가장 큰 문제였습니다. 다음은 2009년 인터뷰에서 전 Google 부사장 Marissa Mayer가 이 주제에 대해 한 말입니다.
“사람들이 시맨틱 검색과 시맨틱 웹에 대해 이야기할 때, 그들은 일반적으로 단어와 그와 같은 것들 간의 다양한 연관성의 지도와 함께 매우 수동적인 것을 의미합니다. 패턴 매칭 데이터, 대규모 시스템 구축을 통해 훨씬 더 나은 이해 수준에 도달할 수 있다고 생각합니다. 그것이 뇌가 작동하는 방식입니다. 두뇌가 항상 끊임없이 많은 데이터를 처리하고 있기 때문에 이러한 모든 모호한 연결이 있는 것입니다. 문제는 언어가 변경된다는 것입니다. 웹 페이지가 변경됩니다. 사람들이 자신을 표현하는 방식이 바뀝니다. 그리고 이러한 모든 것들은 의미 검색이 얼마나 잘 적용되는지와 관련하여 중요합니다. 그렇기 때문에 머신 러닝을 기반으로 하고 데이터를 변경, 반복 및 응답하는 접근 방식을 사용하는 것이 좋습니다. 더 강력한 접근 방식입니다. 의미 검색이 검색에 포함되지 않는다는 말은 아닙니다. 다만 우리는 확장 가능한 것에 집중하는 것을 선호합니다. 확장할 수 있는 의미론적 검색 솔루션을 생각해 낼 수 있다면 매우 기쁠 것입니다. 현재 우리가 보고 있는 많은 방법이 의미 검색의 지능에 가깝지만 다른 수단을 통해 수행한다는 것입니다.” 출처: http://www.pcworld.com/article/181874/article.html
검색 쿼리 또는 문서의 의미를 식별하는 Google에 대해 이야기할 때 의미론적 이해라고 부르는 것의 대부분은 벡터 공간 분석과 같은 통계적 방법이나 TF-IDF와 같은 통계적 텍스트 분석 방법을 기반으로 합니다. 따라서 엄밀히 말해서 이것은 진정한 의미론을 기반으로 하지 않습니다. 그러나 결과는 의미론적 이해에 매우 가깝습니다. 기계 학습의 적용이 증가하고 이를 통해 보다 상세한 분석이 가능해짐에 따라 검색 쿼리 및 문서의 의미론적 해석이 훨씬 쉬워졌습니다.
Google의 목표 중 하나인 의미론적 이해
Google의 가장 중요한 목표 중 하나는 더 관련성 높은 검색 결과를 표시하기 위해 검색어 및 색인이 생성된 문서에 대한 의미론적 이해를 달성하는 것입니다. 의미론적 이해는 (검색) 쿼리와 그 안에 포함된 용어를 명확하게 이해할 수 있을 때 존재합니다. 여러 의미를 가진 용어, 시스템에서 알 수 없는 용어, 불명확한 표현, 개별적인 이해 등을 포함하는 쿼리로 인해 모호하지 않은 해석이 어려운 경우가 많습니다.
이해를 돕기 위해 사용된 단어, 단어의 순서, 주제의 맥락, 시간 및 위치에 대한 분석이 수행됩니다. 기계 학습 및/또는 RankBrain을 통해 Google은 클러스터 분석을 사용하여 새 클래스를 자동으로 생성하고 해당 클래스에 검색어를 할당할 수 있습니다. 이것은 높은 수준의 세부 사항을 설정할 뿐만 아니라 확장성을 만들고 성능을 향상시킵니다. 벡터 공간 분석을 위한 새로운 벡터 공간 생성도 가능합니다.
이러한 방식으로 통계는 기계 학습과 결합되어 검색 쿼리 및 문서의 의미론적 이해에 매우 근접한 의미론적 해석을 제공합니다. Google은 통계적 방법과 기계 학습의 도움으로 진정한 의미 검색을 재현할 수 있기를 원합니다. 또한 최신 Google 검색 엔진의 핵심 요소인 지식 정보도 의미 구조를 기반으로 합니다.
Google의 의미론 및 기계 학습에 대한 이 기사 시리즈의 3부에서 Olaf Kopp은 의미론의 기초: 그래프, 엔터티 및 온톨로지를 살펴볼 것입니다.