
Desenvolviendo los secretos del SEO: todo es semántico para la búsqueda de Google
Publicado: 2017-10-17Hitos como Knowledge Graph, Hummingbird y RankBrain han ayudado a que Google se acerque un poco más a convertirse en un motor de búsqueda perfecto. Las estadísticas, las teorías y estructuras semánticas y el aprendizaje automático juegan un papel importante. En el último Unwrapping the Secrets of SEO, el autor invitado Olaf Kopp examina aspectos de la semántica y el aprendizaje automático en la búsqueda de Google.

En la última entrega de Unwrapping the Secrets of SEO, describí mi punto de vista sobre cómo Google interpreta las consultas de búsqueda y la intención del usuario detrás de ellas. Ahora es el momento de echar un vistazo a cómo Google hace un trabajo tan bueno para mejorar la precisión de la búsqueda.
¿Búsqueda semántica o recuperación de información estadística?
He tenido muchas discusiones acaloradas (¿debate civilizado?) con mi compañero SEO Jens Fauldrath sobre si Google es realmente un motor de búsqueda semántico.
Los resultados que Google presenta a sus usuarios ciertamente hacen que parezca que el gigante de los motores de búsqueda tiene una comprensión semántica muy desarrollada con respecto a las consultas de búsqueda y los documentos. Sin embargo, gran parte de lo que conduce a esta apariencia se basa en métodos estadísticos y no en una comprensión semántica genuina. Pero debido a las estructuras semánticas, en combinación con las estadísticas y el aprendizaje automático, Google ahora puede acercarse a la comprensión semántica.
“Por ejemplo, encontramos que las relaciones semánticas útiles se pueden aprender automáticamente de las estadísticas de consultas de búsqueda y los resultados correspondientes, o de la evidencia acumulada de patrones de texto basados en la web y tablas formateadas, en ambos casos sin necesidad de datos anotados manualmente. ” Fuente: La efectividad irrazonable de los datos, IEEE Computer Society, 2009
Cómo funciona Word2Vec
Para demostrar esto más claramente, entraré brevemente en el trabajo del análisis de textos estadísticos. Google utiliza análisis de espacio vectorial para la evaluación de la relevancia y la identificación de relaciones. Un espacio vectorial consta de puntos de datos individuales que se pueden vincular a través de vectores en el espacio vectorial. El ángulo entre los vectores nos dice acerca de las similitudes y/o relaciones entre los puntos de datos. Cuanto mayor es el ángulo, menos similitud hay. Cuanto menor es el ángulo, mayor es la similitud. Para el análisis de los componentes principales, por ejemplo, se crea un vector en el espacio vectorial a partir de la consulta de búsqueda y todos los documentos relevantes disponibles. Para este llamado proceso de "incrustación de palabras", Google usa Word2vec.
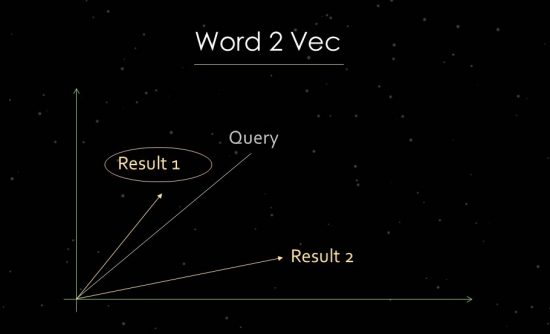
El uso de la proximidad de los puntos de datos entre sí permite mostrar las relaciones semánticas entre ellos. Por lo general, los vectores se crean para consultas de búsqueda y documentos que se pueden colocar en relación unos con otros. Otro uso es crear vectores a partir de un documento y los términos que contiene para identificar su concepto o tema. También sería posible formar vectores a partir de entidades como personas, marcas, empresas o temas.
Para hacer uso de los análisis de espacio vectorial, los documentos primero deben indexarse y asignarse a conceptos o áreas temáticas que luego conforman el corpus temático relevante. Un proceso para llevar a cabo este paso es el Latent Semantic Indexing (LSI), que permite crear espacios vectoriales que brindan los mejores resultados en términos de precisión y recuperación. Mediante este método, también es posible realizar una clasificación semántica o agrupamiento de términos relacionados con un tema.
Cómo se pueden clasificar automáticamente las consultas de búsqueda
En el pasado, el principal problema era la falta de escalabilidad, ya que las consultas de búsqueda debían clasificarse manualmente. Estas son las palabras de la exvicepresidenta de Google, Marissa Mayer, sobre el tema en una entrevista de 2009:

“Cuando la gente habla de búsqueda semántica y de la Web semántica, por lo general se refiere a algo muy manual, con mapas de diversas asociaciones entre palabras y cosas por el estilo. Creemos que puede llegar a un nivel mucho mejor de comprensión a través de datos de coincidencia de patrones, construyendo sistemas a gran escala. Así es como funciona el cerebro. Es por eso que tienes todas estas conexiones borrosas, porque el cerebro está procesando constantemente montones y montones de datos todo el tiempo... El problema es que el lenguaje cambia. Las páginas web cambian. La forma en que las personas se expresan cambia. Y todas esas cosas importan en términos de qué tan bien se aplica la búsqueda semántica. Por eso es mejor tener un enfoque que se base en el aprendizaje automático y que cambie, itere y responda a los datos. Ese es un enfoque más robusto. Eso no quiere decir que la búsqueda semántica no tenga parte en la búsqueda. Es solo que para nosotros, realmente preferimos centrarnos en cosas que pueden escalar. Si pudiéramos encontrar una solución de búsqueda semántica que pudiera escalar, estaríamos muy entusiasmados con eso. Por ahora, lo que estamos viendo es que muchos de nuestros métodos se aproximan a la inteligencia de la búsqueda semántica, pero lo hacen a través de otros medios”. Fuente: http://www.pcworld.com/article/181874/article.html
Gran parte de lo que llamamos comprensión semántica cuando hablamos de que Google identifica el significado de una consulta de búsqueda o un documento se basa en métodos estadísticos como análisis de espacio vectorial o métodos de análisis de texto estadístico como TF-IDF. Estrictamente hablando, por lo tanto, esto no se basa en una semántica genuina. Pero los resultados se acercan mucho a la comprensión semántica. La mayor aplicación del aprendizaje automático, y los análisis más detallados que esto permite, hace que la interpretación semántica de las consultas de búsqueda y los documentos sea mucho más fácil.
La comprensión semántica como uno de los objetivos de Google
Uno de los objetivos más importantes de Google es lograr la comprensión semántica de los términos de búsqueda y los documentos indexados para mostrar resultados de búsqueda más relevantes. Existe una comprensión semántica cuando una consulta (de búsqueda) y los términos contenidos en ella pueden entenderse sin ambigüedades. La interpretación inequívoca a menudo se ve dificultada por consultas que incluyen términos con múltiples significados, términos desconocidos por el sistema, redacción poco clara, comprensión individual, etc.
Para facilitar la comprensión, se analizan las palabras utilizadas, su orden y los contextos de su tema, tiempo y lugar. El aprendizaje automático y/o RankBrain le permiten a Google usar análisis de clúster para crear automáticamente nuevas clases y asignarles consultas de búsqueda. Esto no solo establece un alto nivel de detalle, sino que también crea escalabilidad y aumenta el rendimiento. También es posible la creación de nuevos espacios vectoriales para análisis de espacios vectoriales.
De esta manera, las estadísticas se combinan con el aprendizaje automático para brindar una interpretación cada vez más semántica que se acerca mucho a una comprensión semántica de consultas y documentos de búsqueda. Google quiere poder recrear una búsqueda verdaderamente semántica con la ayuda de métodos estadísticos y aprendizaje automático. Además, un elemento central del moderno motor de búsqueda de Google, Knowledge Graph, también se basa en estructuras semánticas.
En la tercera parte de esta serie de artículos sobre la semántica y el aprendizaje automático de Google, Olaf Kopp analizará los fundamentos de la semántica: gráficos, entidades y ontologías.