
ไขความลับของ SEO: ทั้งหมดมีความหมายสำหรับ Google Search
เผยแพร่แล้ว: 2017-10-17เหตุการณ์สำคัญ เช่น กราฟความรู้ Hummingbird และ RankBrain ได้ช่วยให้ Google เข้าใกล้การเป็นเสิร์ชเอ็นจิ้นที่สมบูรณ์แบบมากขึ้นอีกไม่กี่ก้าว สถิติ ทฤษฎีและโครงสร้างเชิงความหมาย และแมชชีนเลิร์นนิงล้วนมีบทบาทสำคัญ ใน Unwrapping the Secrets of SEO ล่าสุด Olaf Kopp ผู้เขียนรับเชิญได้ตรวจสอบแง่มุมของความหมายและการเรียนรู้ของเครื่องในการค้นหาของ Google

ในภาคล่าสุดของ Unwrapping the Secrets of SEO ฉันได้สรุปมุมมองของฉันเกี่ยวกับวิธีที่ Google ตีความคำค้นหาและเจตนาของผู้ใช้ที่อยู่เบื้องหลัง ถึงเวลามาดูกัน ว่า Google ปรับปรุงความแม่นยำในการค้นหาได้ดีเพียงใด
การค้นหาความหมายหรือการดึงข้อมูลทางสถิติ?
ฉันมีข้อโต้แย้งที่ร้อนแรง (การอภิปรายอารยะธรรม?) กับเพื่อน SEO Jens Fauldrath ว่า Google เป็นเสิร์ชเอ็นจิ้นที่มีความหมายจริงๆ หรือไม่
ผลลัพธ์ที่ Google นำเสนอแก่ผู้ใช้ทำให้ดูเหมือนว่ายักษ์ใหญ่ของเครื่องมือค้นหามีความเข้าใจในความหมายเกี่ยวกับคำค้นหาและเอกสารที่พัฒนาขึ้นอย่างมาก อย่างไรก็ตาม สิ่งที่นำไปสู่ลักษณะนี้ส่วนใหญ่ขึ้นอยู่กับวิธีการทางสถิติ ไม่ใช่ความเข้าใจในความหมายที่แท้จริง แต่เนื่องจากโครงสร้างทางความหมาย ร่วมกับสถิติและการเรียนรู้ของเครื่อง ตอนนี้ Google สามารถเข้าถึงความเข้าใจเชิงความหมายได้อย่างใกล้ชิด
“ตัวอย่างเช่น เราพบว่าความสัมพันธ์เชิงความหมายที่เป็นประโยชน์สามารถเรียนรู้ได้โดยอัตโนมัติจากสถิติของคำค้นหาและผลลัพธ์ที่เกี่ยวข้อง หรือจากหลักฐานสะสมของรูปแบบข้อความบนเว็บและตารางที่จัดรูปแบบ ในทั้งสองกรณีโดยไม่ต้องใช้ข้อมูลที่มีคำอธิบายประกอบด้วยตนเอง ” ที่มา: The Unreasonable Effectiveness of Data, IEEE Computer Society, 2009
Word2Vec ทำงานอย่างไร
เพื่อแสดงให้ชัดเจนยิ่งขึ้น ฉันจะเข้าสู่งานการวิเคราะห์ข้อความทางสถิติโดยสังเขป Google ใช้การวิเคราะห์พื้นที่เวกเตอร์เพื่อประเมินความเกี่ยวข้องและการระบุความสัมพันธ์ พื้นที่เวกเตอร์ประกอบด้วยจุดข้อมูลแต่ละจุดที่สามารถเชื่อมโยงผ่านเวกเตอร์ในพื้นที่เวกเตอร์ มุมระหว่างเวกเตอร์บอกเราเกี่ยวกับความเหมือนและ/หรือความสัมพันธ์ระหว่างจุดข้อมูล ยิ่งมุมมีขนาดใหญ่เท่าใด ความคล้ายคลึงก็จะน้อยลงเท่านั้น ยิ่งมุมเล็กลง ความคล้ายคลึงก็จะยิ่งมากขึ้น สำหรับการวิเคราะห์องค์ประกอบหลัก เช่น เวกเตอร์จะถูกสร้างขึ้นในพื้นที่เวกเตอร์จากคำค้นหาและเอกสารที่เกี่ยวข้องทั้งหมดที่มี สำหรับกระบวนการที่เรียกว่า "การฝังคำ" Google ใช้ Word2vec
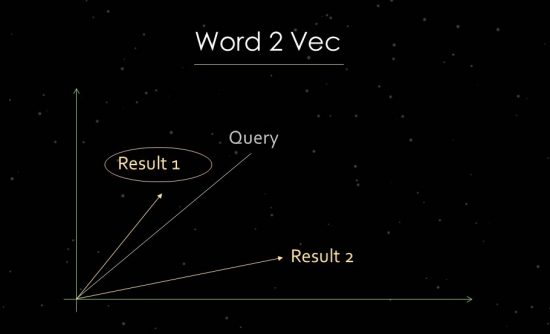
การใช้จุดข้อมูลใกล้เคียงกันทำให้สามารถแสดงความสัมพันธ์ทางความหมายระหว่างกัน โดยทั่วไปแล้ว เวกเตอร์จะถูกสร้างขึ้นสำหรับคำค้นหาและเอกสารที่สามารถวางสัมพันธ์กัน การใช้งานอื่นคือการสร้างเวกเตอร์จากเอกสารและข้อกำหนดภายในเพื่อระบุแนวคิดหรือหัวข้อ นอกจากนี้ยังเป็นไปได้ที่จะสร้างเวกเตอร์จากหน่วยงานต่างๆ เช่น บุคคล แบรนด์ บริษัท หรือหัวข้อ
เพื่อที่จะใช้การวิเคราะห์เวคเตอร์สเปซ เอกสารก่อนอื่นจะต้องมีการจัดทำดัชนีและแมปกับแนวคิดหรือพื้นที่หัวข้อที่ประกอบเป็นคลังข้อมูลเฉพาะที่เกี่ยวข้อง กระบวนการในการดำเนินการตามขั้นตอนนี้คือ Latent Semantic Indexing (LSI) ซึ่งทำให้สามารถสร้างช่องว่างเวกเตอร์ที่ให้ผลลัพธ์ที่ดีที่สุดในแง่ของความแม่นยำและการเรียกคืน การใช้วิธีนี้ทำให้สามารถจัดประเภทความหมายหรือจัดกลุ่มคำศัพท์ที่เกี่ยวข้องกับหัวข้อได้
คำค้นหาสามารถจำแนกโดยอัตโนมัติได้อย่างไร
ในอดีต ปัญหาหลักคือการขาดความสามารถในการปรับขนาดเนื่องจากต้องจัดประเภทคำค้นหาด้วยตนเอง นี่เป็นคำพูดของ Marissa Mayer อดีตรองประธาน Google ในหัวข้อนี้จากการสัมภาษณ์ปี 2009:

“เมื่อผู้คนพูดถึงการค้นหาเชิงความหมายและเว็บเชิงความหมาย พวกเขามักจะหมายถึงบางสิ่งที่เข้าใจได้ด้วยตนเอง โดยมีแผนที่ของการเชื่อมโยงต่างๆ ระหว่างคำและสิ่งต่างๆ เช่นนั้น เราคิดว่าคุณสามารถมีความเข้าใจในระดับที่ดีขึ้นมากผ่านข้อมูลการจับคู่รูปแบบ การสร้างระบบขนาดใหญ่ นั่นเป็นวิธีที่สมองทำงาน นั่นเป็นเหตุผลที่คุณมีการเชื่อมต่อที่คลุมเครือเหล่านี้ เนื่องจากสมองกำลังประมวลผลข้อมูลจำนวนมากตลอดเวลา... ปัญหาคือภาษานั้นเปลี่ยนไป หน้าเว็บมีการเปลี่ยนแปลง วิธีที่ผู้คนแสดงออกเปลี่ยนแปลง และทุกสิ่งเหล่านั้นมีความสำคัญในแง่ของการใช้การค้นหาเชิงความหมายที่ดีเพียงใด นั่นเป็นเหตุผลว่าทำไมจึงดีกว่าที่จะมีวิธีการที่อิงจากการเรียนรู้ของเครื่องและการเปลี่ยนแปลง ทำซ้ำ และตอบสนองต่อข้อมูล นั่นเป็นแนวทางที่แข็งแกร่งกว่า ไม่ได้หมายความว่าการค้นหาเชิงความหมายไม่มีส่วนในการค้นหา สำหรับเราเท่านั้น เราชอบที่จะมุ่งเน้นในสิ่งที่สามารถขยายได้ หากเราสามารถคิดค้นโซลูชันการค้นหาเชิงความหมายที่สามารถปรับขนาดได้ เราจะตื่นเต้นมากเกี่ยวกับเรื่องนี้ สำหรับตอนนี้ สิ่งที่เราเห็นคือวิธีการมากมายของเราใกล้เคียงกับความฉลาดของการค้นหาเชิงความหมาย แต่ใช้วิธีอื่น” ที่มา: http://www.pcworld.com/article/181874/article.html
สิ่งที่เราเรียกว่าความเข้าใจเชิงความหมายเมื่อเราพูดถึง Google ในการระบุความหมายของคำค้นหาหรือเอกสารนั้นสร้างขึ้นจากวิธีการทางสถิติ เช่น การวิเคราะห์พื้นที่เวกเตอร์หรือวิธีการวิเคราะห์ข้อความทางสถิติ เช่น TF-IDF พูดโดยเคร่งครัด เรื่องนี้ไม่ได้อิงจากความหมายที่แท้จริง แต่ผลลัพธ์นั้นใกล้เคียงกับความเข้าใจเชิงความหมายมาก การประยุกต์ใช้แมชชีนเลิร์นนิงที่เพิ่มขึ้น และการวิเคราะห์ที่มีรายละเอียดมากขึ้น ช่วยให้การแปลความหมายของคำค้นหาและเอกสารง่ายขึ้นมาก
ความเข้าใจเชิงความหมายเป็นหนึ่งในเป้าหมายของ Google
เป้าหมายที่สำคัญที่สุดอย่างหนึ่งของ Google คือการบรรลุความเข้าใจเชิงความหมายเกี่ยวกับข้อความค้นหาและเอกสารที่จัดทำดัชนี เพื่อแสดงผลการค้นหาที่เกี่ยวข้องมากขึ้น ความเข้าใจเชิงความหมายเกิดขึ้นเมื่อคำค้นหา (การค้นหา) และคำที่อยู่ในนั้นสามารถเข้าใจได้อย่างชัดเจน การตีความที่ไม่คลุมเครือมักทำให้ยากขึ้นจากข้อความค้นหา ซึ่งรวมถึงคำที่มีความหมายหลายความหมาย คำที่ระบบไม่รู้จัก การใช้ถ้อยคำที่ไม่ชัดเจน ความเข้าใจส่วนบุคคล เป็นต้น
เพื่อช่วยให้เข้าใจ จึงมีการวิเคราะห์คำที่ใช้ ลำดับ และบริบทของหัวข้อ เวลา และสถานที่ แมชชีนเลิร์นนิงและ/หรือ RankBrain ช่วยให้ Google ใช้การวิเคราะห์คลัสเตอร์เพื่อสร้างคลาสใหม่และกำหนดการค้นหาให้กับคลาสโดยอัตโนมัติ ซึ่งไม่เพียงแต่สร้างรายละเอียดในระดับสูง แต่ยังสร้างความสามารถในการปรับขนาดและเพิ่มประสิทธิภาพอีกด้วย การสร้างช่องว่างเวกเตอร์ใหม่สำหรับการวิเคราะห์พื้นที่เวกเตอร์ก็เป็นไปได้เช่นกัน
ด้วยวิธีนี้ สถิติจะรวมกับการเรียนรู้ของเครื่องเพื่อให้มีการตีความเชิงความหมายมากขึ้น ซึ่งใกล้เคียงกับความเข้าใจในความหมายของคำค้นหาและเอกสาร Google ต้องการให้สามารถสร้างการค้นหาเชิงความหมายได้อย่างแท้จริงโดยใช้วิธีการทางสถิติและการเรียนรู้ของเครื่อง นอกจากนี้ องค์ประกอบสำคัญของเครื่องมือค้นหาของ Google สมัยใหม่อย่างกราฟความรู้ยังอิงตามโครงสร้างทางความหมายด้วย
ในตอนที่ 3 ของบทความชุดเกี่ยวกับความหมายของ Google และแมชชีนเลิร์นนิง Olaf Kopp จะกล่าวถึง Foundations of Semantics: Graphs, Entities และ Ontology