
揭开搜索引擎优化的秘密:谷歌搜索的全部语义
已发表: 2017-10-17Knowledge Graph、Hummingbird 和 RankBrain 等里程碑帮助 Google 离成为完美搜索引擎更近了一步。 统计、语义理论和结构以及机器学习都发挥着重要作用。 在最新一期的《揭开 SEO 的秘密》中,客座作者 Olaf Kopp 研究了 Google 搜索中语义和机器学习的各个方面。

在《揭开 SEO 的秘密》的最后一部分中,我概述了我对 Google 如何解释搜索查询及其背后的用户意图的看法。 现在是时候看看 Google如何在提高搜索准确性方面做得如此出色。
语义搜索还是统计信息检索?
我与 SEO Jens Fauldrath 就 Google 是否真的是一个语义搜索引擎进行了许多激烈的争论(文明辩论?)。
谷歌向用户展示的结果无疑让这家搜索引擎巨头看起来对搜索查询和文档具有高度发达的语义理解。 然而,导致这种外观的大部分原因是基于统计方法,而不是任何真正的语义理解。 但是由于语义结构,结合统计和机器学习,谷歌现在能够接近语义理解。
“例如,我们发现有用的语义关系可以从搜索查询的统计数据和相应的结果中自动学习,或者从基于 Web 的文本模式和格式化表格的累积证据中自动学习,在这两种情况下都不需要任何手动注释数据。 ” 资料来源:数据的不合理有效性,IEEE 计算机协会,2009
Word2Vec 的工作原理
为了更清楚地说明这一点,我将简要介绍统计文本分析的工作。 谷歌使用向量空间分析来评估相关性和识别关系。 向量空间由可以通过向量空间中的向量链接的各个数据点组成。 向量之间的角度告诉我们数据点之间的相似性和/或关系。 角度越大,相似度越低。 角度越小,相似度越大。 例如,对于主要成分的分析,在向量空间中从搜索查询和所有可用的相关文档中创建一个向量。 对于这个所谓的“词嵌入”过程,谷歌使用了 Word2vec。
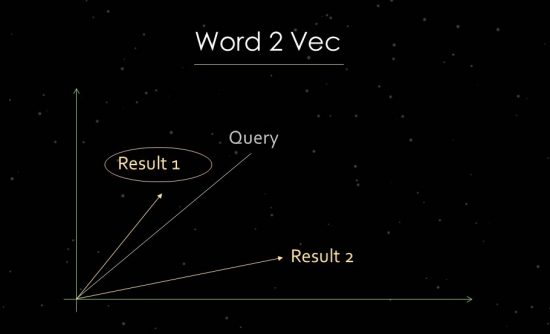
使用数据点彼此之间的接近性可以显示它们之间的语义关系。 通常,向量是为搜索查询和文档创建的,它们可以相互关联。 另一种用法是从文档和其中的术语创建向量,以识别其概念或主题。 也可以从人、品牌、公司或主题等实体形成向量。
为了利用向量空间分析,文档首先需要被索引并映射到概念或主题领域,然后构成相关的主题语料库。 执行此步骤的过程是潜在语义索引 (LSI),它可以创建在精度和召回率方面提供最佳结果的向量空间。 使用这种方法,还可以对与主题相关的术语进行语义分类或聚类。

如何自动分类搜索查询
过去,主要问题是缺乏可扩展性,因为搜索查询必须手动分类。 以下是 Google 前副总裁 Marissa Mayer 在 2009 年的一次采访中关于这个主题的话:
“当人们谈论语义搜索和语义网络时,他们通常指的是非常手动的东西,带有单词和类似事物之间各种关联的地图。 我们认为您可以通过模式匹配数据获得更好的理解,构建大规模系统。 大脑就是这样工作的。 这就是为什么你有所有这些模糊的联系,因为大脑一直在不断地处理大量的数据……问题是语言会发生变化。 网页发生变化。 人们表达自己的方式发生了变化。 就语义搜索的应用程度而言,所有这些事情都很重要。 这就是为什么最好有一种基于机器学习的方法,它会改变、迭代和响应数据。 这是一种更强大的方法。 这并不是说语义搜索与搜索无关。 只是对我们来说,我们真的更喜欢专注于可以扩展的东西。 如果我们能想出一个可以扩展的语义搜索解决方案,我们会非常兴奋。 目前,我们看到的是,我们的许多方法都近似于语义搜索的智能,但通过其他方式来实现。” 来源:http://www.pcworld.com/article/181874/article.html
当我们谈论谷歌识别搜索查询或文档的含义时,我们称之为语义理解的大部分内容都是建立在向量空间分析等统计方法或 TF-IDF 等统计文本分析方法之上的。 因此,严格来说,这不是基于真正的语义。 但结果确实非常接近语义理解。 机器学习应用的增加——以及由此实现的更详细的分析——使得搜索查询和文档的语义解释变得更加容易。
语义理解是谷歌的目标之一
Google 最重要的目标之一是实现对搜索词和索引文档的语义理解,以便显示更相关的搜索结果。 当(搜索)查询和其中包含的术语可以被明确理解时,就存在语义理解。 包括具有多种含义的术语、系统未知的术语、不明确的措辞、个人理解等在内的查询通常会使明确的解释变得困难。
为了帮助理解,对所使用的词、它们的顺序以及它们的主题、时间和位置的上下文进行分析。 机器学习和/或 RankBrain 使 Google 能够使用聚类分析来自动创建新类并将搜索查询分配给它们。 这不仅建立了高级别的细节,而且还创造了可扩展性并提高了性能。 也可以为向量空间分析创建新的向量空间。
通过这种方式,统计数据与机器学习相结合,提供了越来越接近于对搜索查询和文档的语义理解的语义解释。 谷歌希望能够借助统计方法和机器学习重新创建真正的语义搜索。 此外,现代谷歌搜索引擎的核心元素知识图谱也是基于语义结构的。
在 Google 语义和机器学习系列文章的第三部分中,Olaf Kopp 将探讨语义学的基础:图、实体和本体。