
كشف أسرار مُحسّنات محرّكات البحث: الأمر كله دلالي لبحث Google
نشرت: 2017-10-17ساعدت المعالم البارزة مثل Knowledge Graph و Hummingbird و RankBrain في تقريب Google بضع خطوات من أن تصبح محرك بحث مثاليًا. تلعب الإحصائيات والنظريات والتراكيب الدلالية والتعلم الآلي دورًا مهمًا. في أحدث إصدار بعنوان "فك أسرار تحسين محركات البحث" ، يفحص المؤلف الضيف أولاف كوب جوانب الدلالات والتعلم الآلي في بحث Google.

في الدفعة الأخيرة من Unwrapping the Secrets of SEO ، أوجزت وجهة نظري حول كيفية تفسير Google لاستعلامات البحث ونية المستخدم من وراءها. حان الوقت الآن لإلقاء نظرة على كيفية قيام Google بعمل جيد في تحسين دقة البحث.
البحث الدلالي أو استرجاع المعلومات الإحصائية؟
لقد خضت العديد من الجدل الساخن (نقاش متحضر؟) مع زملائي في تحسين محركات البحث Jens Fauldrath حول ما إذا كان محرك بحث Google حقًا محرك بحث دلالي.
من المؤكد أن النتائج التي تقدمها Google لمستخدميها تجعلها تبدو كما لو أن محرك البحث العملاق لديه فهم دلالي متطور للغاية فيما يتعلق باستعلامات البحث والمستندات. ومع ذلك ، فإن الكثير مما يؤدي إلى هذا المظهر يعتمد على الأساليب الإحصائية ، وليس على أي فهم دلالي حقيقي. ولكن نظرًا للهياكل الدلالية ، جنبًا إلى جنب مع الإحصائيات والتعلم الآلي ، أصبح بإمكان Google الآن الاقتراب من الفهم الدلالي.
"على سبيل المثال ، نجد أنه يمكن تعلم العلاقات الدلالية المفيدة تلقائيًا من إحصائيات استعلامات البحث والنتائج المقابلة ، أو من الأدلة المتراكمة لأنماط النص المستندة إلى الويب والجداول المنسقة ، في كلتا الحالتين دون الحاجة إلى أي بيانات مشروحة يدويًا. " المصدر: الفعالية غير المعقولة للبيانات ، جمعية الحاسبات IEEE ، 2009
كيف يعمل Word2Vec
لتوضيح ذلك بشكل أكثر وضوحًا ، سأدخل بإيجاز في عمل تحليل النص الإحصائي. تستخدم Google تحليلات فضاء المتجهات لتقييم مدى الصلة وتحديد العلاقات. تتكون مساحة المتجه من نقاط بيانات فردية يمكن ربطها عبر متجهات في مساحة المتجه. تخبرنا الزاوية بين المتجهات عن أوجه التشابه و / أو العلاقات بين نقاط البيانات. كلما كبرت الزاوية ، قل التشابه. كلما كانت الزاوية أصغر ، زاد التشابه. لتحليل المكونات الرئيسية ، على سبيل المثال ، يتم إنشاء متجه في مساحة المتجه من استعلام البحث وجميع المستندات ذات الصلة المتاحة. في ما يسمى بعملية "تضمين الكلمات" ، يستخدم Google Word2vec.
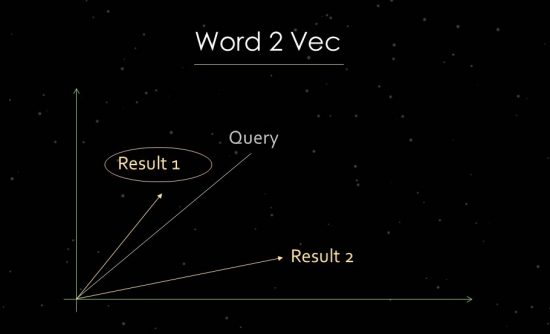
يتيح استخدام قرب نقاط البيانات من بعضها البعض إظهار العلاقات الدلالية بينها. عادة ، يتم إنشاء المتجهات لاستعلامات البحث والمستندات التي يمكن وضعها فيما يتعلق ببعضها البعض. استخدام آخر هو إنشاء متجهات من مستند والمصطلحات الموجودة فيه من أجل تحديد مفهومه أو موضوعه. سيكون من الممكن أيضًا تكوين ناقلات من كيانات مثل الأشخاص أو العلامات التجارية أو الشركات أو الموضوعات.
من أجل الاستفادة من تحليلات مساحة المتجه ، يجب أولاً فهرسة المستندات وتعيينها إلى المفاهيم أو مجالات الموضوعات التي تشكل بعد ذلك مجموعة الموضوعات ذات الصلة. عملية تنفيذ هذه الخطوة هي الفهرسة الدلالية الكامنة (LSI) ، والتي تجعل من الممكن إنشاء مسافات متجهة توفر أفضل النتائج من حيث الدقة والتذكر. باستخدام هذه الطريقة ، من الممكن أيضًا إجراء التصنيف الدلالي أو تجميع المصطلحات المتعلقة بموضوع ما.

كيف يمكن تصنيف استعلامات البحث تلقائيًا
في الماضي ، كانت المشكلة الرئيسية هي الافتقار إلى قابلية التوسع حيث كان لابد من تصنيف استعلامات البحث يدويًا. هذه كلمات نائب الرئيس السابق لشركة Google Marissa Mayer حول هذا الموضوع من مقابلة عام 2009:
عندما يتحدث الناس عن البحث الدلالي والويب الدلالي ، فإنهم عادة ما يقصدون شيئًا يدويًا للغاية ، مع خرائط للارتباطات المختلفة بين الكلمات وأشياء من هذا القبيل. نعتقد أنه يمكنك الوصول إلى مستوى أفضل من الفهم من خلال بيانات مطابقة الأنماط ، وبناء أنظمة واسعة النطاق. هذه هي الطريقة التي يعمل بها الدماغ. لهذا السبب لديك كل هذه الاتصالات الغامضة ، لأن الدماغ يعالج باستمرار الكثير والكثير من البيانات طوال الوقت ... المشكلة هي أن اللغة تتغير. صفحات الويب تتغير. كيف يعبر الناس عن أنفسهم يتغير. وكل هذه الأشياء مهمة من حيث مدى جودة تطبيق البحث الدلالي. هذا هو السبب في أنه من الأفضل أن يكون لديك نهج يعتمد على التعلم الآلي والذي يغير البيانات ويكررها ويستجيب لها. هذا نهج أكثر قوة. هذا لا يعني أن البحث الدلالي ليس له دور في البحث. إنه فقط بالنسبة لنا ، نحن نفضل حقًا التركيز على الأشياء التي يمكن توسيع نطاقها. إذا تمكنا من التوصل إلى حل بحث دلالي يمكنه التوسع ، سنكون متحمسين جدًا لذلك. في الوقت الحالي ، ما نراه هو أن الكثير من أساليبنا تقارب ذكاء البحث الدلالي ولكنها تفعل ذلك من خلال وسائل أخرى ". المصدر: http://www.pcworld.com/article/181874/article.html
إن الكثير مما نسميه الفهم الدلالي عندما نتحدث عن تحديد Google لمعنى استعلام البحث أو المستند مبني على طرق إحصائية مثل تحليلات الفضاء المتجه أو طرق تحليل النص الإحصائي مثل TF-IDF. بالمعنى الدقيق للكلمة ، فإن هذا لا يعتمد على دلالات حقيقية. لكن النتائج تقترب جدًا من الفهم الدلالي. التطبيق المتزايد للتعلم الآلي - والتحليلات الأكثر تفصيلاً التي يتيحها ذلك - تجعل التفسير الدلالي لاستعلامات البحث والمستندات أسهل بكثير.
الفهم الدلالي كأحد أهداف Google
أحد أهم أهداف Google هو تحقيق الفهم الدلالي فيما يتعلق بمصطلحات البحث والمستندات المفهرسة من أجل عرض نتائج بحث أكثر صلة. يوجد الفهم الدلالي عندما يمكن فهم استعلام (بحث) والمصطلحات الواردة فيه بشكل لا لبس فيه. غالبًا ما يكون التفسير غير المبهم صعبًا من خلال الاستعلامات التي تتضمن مصطلحات ذات معاني متعددة ، ومصطلحات غير معروفة من قبل النظام ، وصياغة غير واضحة ، وفهم فردي ، إلخ.
للمساعدة في الفهم ، يتم إجراء تحليل للكلمات المستخدمة وترتيبها وسياقات موضوعها ووقتها وموقعها. يمكّن التعلم الآلي و / أو RankBrain Google من استخدام التحليلات العنقودية لإنشاء فئات جديدة تلقائيًا وتعيين استعلامات بحث إليها. لا يؤدي هذا إلى إنشاء مستوى عالٍ من التفاصيل فحسب ، بل يؤدي أيضًا إلى إنشاء قابلية التوسع وزيادة الأداء. أصبح إنشاء مساحات متجهية جديدة لتحليلات الفضاء المتجه ممكنًا أيضًا.
بهذه الطريقة ، تتحد الإحصائيات مع التعلم الآلي لإعطاء تفسير دلالي متزايد يقترب جدًا من الفهم الدلالي لاستعلامات البحث والمستندات. تريد Google أن تكون قادرة على إعادة إنشاء بحث دلالي حقيقي بمساعدة الأساليب الإحصائية والتعلم الآلي. علاوة على ذلك ، فإن العنصر المركزي في محرك بحث Google الحديث ، الرسم البياني المعرفي ، يعتمد أيضًا على الهياكل الدلالية.
في الجزء الثالث من سلسلة المقالات هذه حول دلالات Google والتعلم الآلي ، سيلقي أولاف كوب نظرة على أسس علم المعاني: الرسوم البيانية والكيانات والأنظمة.