
揭開搜索引擎優化的秘密:谷歌搜索的全部語義
已發表: 2017-10-17Knowledge Graph、Hummingbird 和 RankBrain 等里程碑幫助 Google 離成為完美搜索引擎更近了一步。 統計、語義理論和結構以及機器學習都發揮著重要作用。 在最新一期的《揭開 SEO 的秘密》中,客座作者 Olaf Kopp 研究了 Google 搜索中語義和機器學習的各個方面。

在《揭開 SEO 的秘密》的最後一部分中,我概述了我對 Google 如何解釋搜索查詢及其背後的用戶意圖的看法。 現在是時候看看 Google如何在提高搜索準確性方面做得如此出色。
語義搜索還是統計信息檢索?
我與 SEO Jens Fauldrath 就 Google 是否真的是一個語義搜索引擎進行了許多激烈的爭論(文明辯論?)。
谷歌向用戶展示的結果無疑讓這家搜索引擎巨頭看起來對搜索查詢和文檔具有高度發達的語義理解。 然而,導致這種外觀的大部分原因是基於統計方法,而不是任何真正的語義理解。 但是由於語義結構,結合統計和機器學習,谷歌現在能夠接近語義理解。
“例如,我們發現有用的語義關係可以從搜索查詢的統計數據和相應的結果中自動學習,或者從基於 Web 的文本模式和格式化表格的累積證據中自動學習,在這兩種情況下都不需要任何手動註釋數據。 ” 資料來源:數據的不合理有效性,IEEE 計算機協會,2009
Word2Vec 的工作原理
為了更清楚地說明這一點,我將簡要介紹統計文本分析的工作。 谷歌使用向量空間分析來評估相關性和識別關係。 向量空間由可以通過向量空間中的向量鏈接的各個數據點組成。 向量之間的角度告訴我們數據點之間的相似性和/或關係。 角度越大,相似度越低。 角度越小,相似度越大。 例如,對於主要成分的分析,在向量空間中從搜索查詢和所有可用的相關文檔中創建一個向量。 對於這個所謂的“詞嵌入”過程,谷歌使用了 Word2vec。
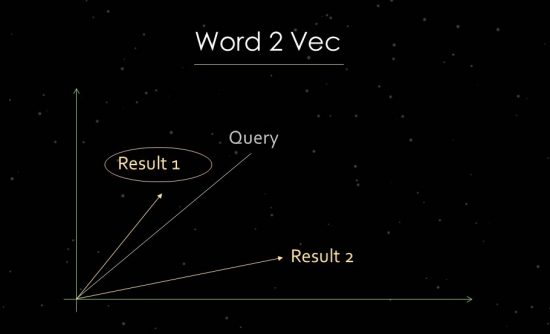
使用數據點彼此之間的接近性可以顯示它們之間的語義關係。 通常,向量是為搜索查詢和文檔創建的,它們可以相互關聯。 另一種用法是從文檔和其中的術語創建向量,以識別其概念或主題。 也可以從人、品牌、公司或主題等實體形成向量。
為了利用向量空間分析,文檔首先需要被索引並映射到概念或主題領域,然後構成相關的主題語料庫。 執行此步驟的過程是潛在語義索引 (LSI),它可以創建在精度和召回率方面提供最佳結果的向量空間。 使用這種方法,還可以對與主題相關的術語進行語義分類或聚類。

如何自動分類搜索查詢
過去,主要問題是缺乏可擴展性,因為搜索查詢必須手動分類。 以下是 Google 前副總裁 Marissa Mayer 在 2009 年的一次採訪中關於這個主題的話:
“當人們談論語義搜索和語義網絡時,他們通常指的是非常手動的東西,帶有單詞和類似事物之間各種關聯的地圖。 我們認為您可以通過模式匹配數據獲得更好的理解,構建大規模系統。 大腦就是這樣工作的。 這就是為什麼你有所有這些模糊的聯繫,因為大腦一直在不斷地處理大量的數據……問題是語言會發生變化。 網頁發生變化。 人們表達自己的方式發生了變化。 就語義搜索的應用程度而言,所有這些事情都很重要。 這就是為什麼最好有一種基於機器學習的方法,它會改變、迭代和響應數據。 這是一種更強大的方法。 這並不是說語義搜索與搜索無關。 只是對我們來說,我們真的更喜歡專注於可以擴展的東西。 如果我們能想出一個可以擴展的語義搜索解決方案,我們會非常興奮。 目前,我們看到的是,我們的許多方法都近似於語義搜索的智能,但通過其他方式來實現。” 來源:http://www.pcworld.com/article/181874/article.html
當我們談論谷歌識別搜索查詢或文檔的含義時,我們稱之為語義理解的大部分內容都是建立在向量空間分析等統計方法或 TF-IDF 等統計文本分析方法之上的。 因此,嚴格來說,這不是基於真正的語義。 但結果確實非常接近語義理解。 機器學習應用的增加——以及由此實現的更詳細的分析——使得搜索查詢和文檔的語義解釋變得更加容易。
語義理解是谷歌的目標之一
Google 最重要的目標之一是實現對搜索詞和索引文檔的語義理解,以便顯示更相關的搜索結果。 當(搜索)查詢和其中包含的術語可以被明確理解時,就存在語義理解。 包括具有多種含義的術語、系統未知的術語、不明確的措辭、個人理解等在內的查詢通常會使明確的解釋變得困難。
為了幫助理解,對所使用的詞、它們的順序以及它們的主題、時間和位置的上下文進行分析。 機器學習和/或 RankBrain 使 Google 能夠使用聚類分析來自動創建新類並將搜索查詢分配給它們。 這不僅建立了高級別的細節,而且還創造了可擴展性並提高了性能。 也可以為向量空間分析創建新的向量空間。
通過這種方式,統計數據與機器學習相結合,提供了越來越接近對搜索查詢和文檔的語義理解的語義解釋。 谷歌希望能夠借助統計方法和機器學習重新創建真正的語義搜索。 此外,現代谷歌搜索引擎的核心元素知識圖譜也是基於語義結構的。
在 Google 語義和機器學習系列文章的第三部分中,Olaf Kopp 將探討語義學的基礎:圖、實體和本體。