
網絡抓取 IMDB 以獲得最佳電影和節目
已發表: 2020-12-08您想知道有史以來排名前 250 的電影是什麼嗎? 還是小屏幕上最好的喜劇節目? 對於與電影和節目世界相關的所有此類答案、評論、評級和瑣事,世界各地的人們都使用 IMDB,這是此類信息的在線數據庫。 雖然信息由粉絲更新,但數據庫本身由亞馬遜的子公司擁有和運營。 它最初於 1990 年作為數據庫創建,並於 1993 年移至網絡。雖然任何人都可以訪問網站上的信息,但如果您想對事實進行編輯或添加評論,則必須進行註冊。 在這篇博客中,我們將了解如何使用 Python 完成網絡抓取 IMDB 數據。
除了為電影和小屏幕節目更新的各種數據點之外,IMDB 還允許其用戶添加評級,這些評級構成了多個列表的基礎,電影愛好者和其他人使用這些列表來創建他們的觀看列表。 雖然 IMDB 不提供 API 來查詢其數據,但它允許您以文本格式下載數據。 您還可以使用 DIY 代碼抓取數據。
IMDB 數據的 Web 抓取是如何完成的?
我們將從 IMDB 中抓取 2 組數據
一個)。 IMDB 前 250 部電影
乙)。 IMDB 前 250 名電視節目
我們將為這些列表中的每部電影或節目抓取某些數據點。 您可能不想一次抓取所有數據,因此我們提供了更改參數值的選項,以僅提取前 n 個結果。
在開始之前,您需要 Python3.7 或更高版本以及 BeautifulSoup 依賴項和文本編輯器。 然後,您可以使用 python 命令本身運行下面給出的代碼。 不需要用戶輸入,因為我們已經硬編碼了前面在代碼中提到的兩個列表的鏈接。
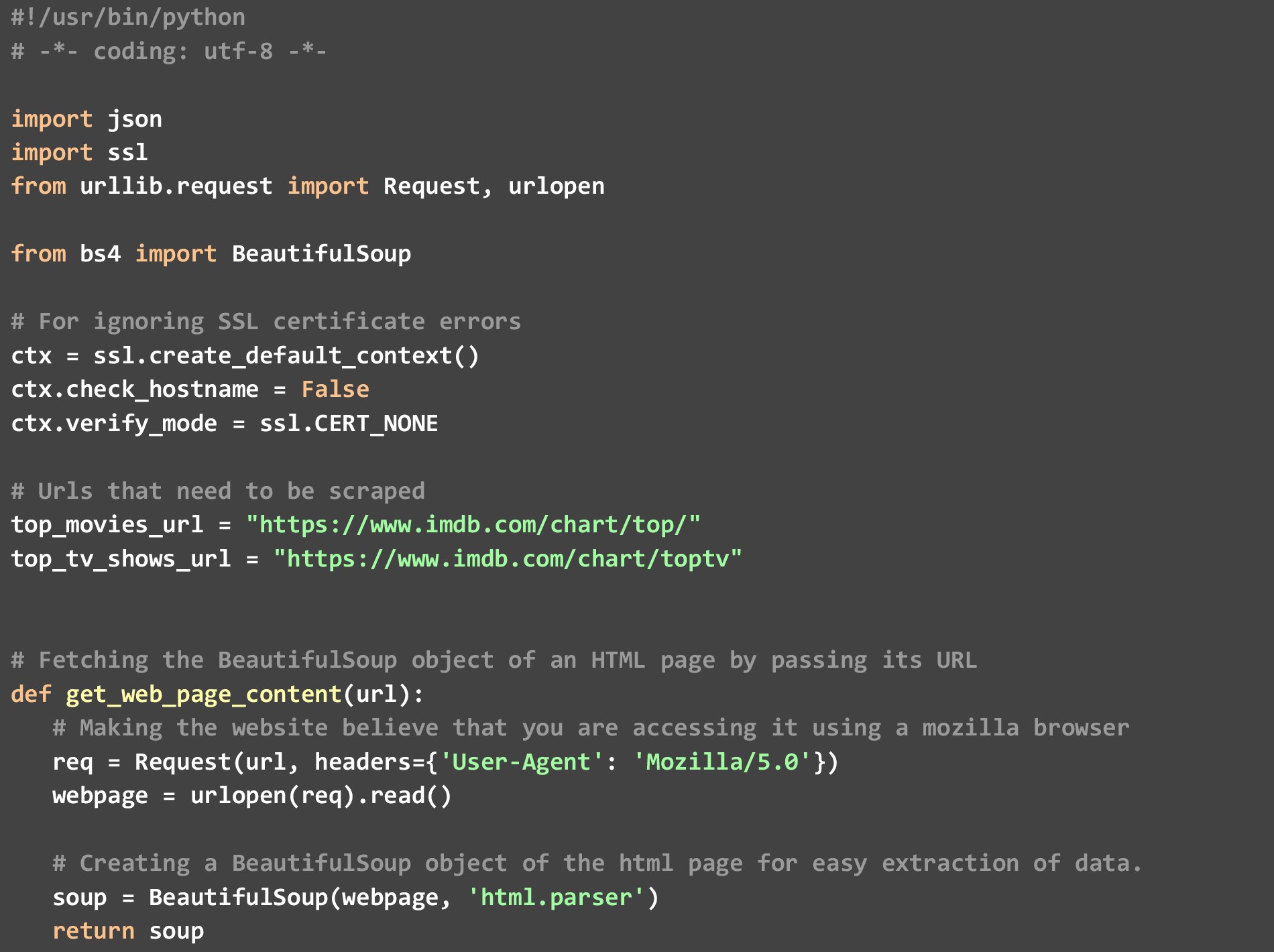
在代碼中,我們有 3 個具體的功能
一個)。 get_top_rated_imdb_hits - 這是執行開始的地方。 作為該函數的輸入,我們傳遞相關列表的 URL。 它可以是電影列表 URL 或電視節目列表 URL。 我們還傳遞了我們想要結果 JSON 的文件的名稱和我們想要的頂級結果的數量。 我們獲取某些數據點,例如網頁本身可用的電影名稱和評分,然後繞過電影/節目特定 URL 調用 get_extra_details 函數來獲取額外數據點。
乙)。 get_web_page_content- 該函數用於獲取傳入其中的 URL 的 HTML 內容,並將其轉換為易於解析的 BeautifulSoup 對象。 這個對象就是這個函數返回的。
C)。 get_extra_details - 此函數使用由 get_top_rated_imdb_hits 函數傳遞給它的電影或節目特定 URL 來獲取更多詳細信息,例如摘要、頂級明星的姓名以及排名列表網頁中不可用的導演信息。
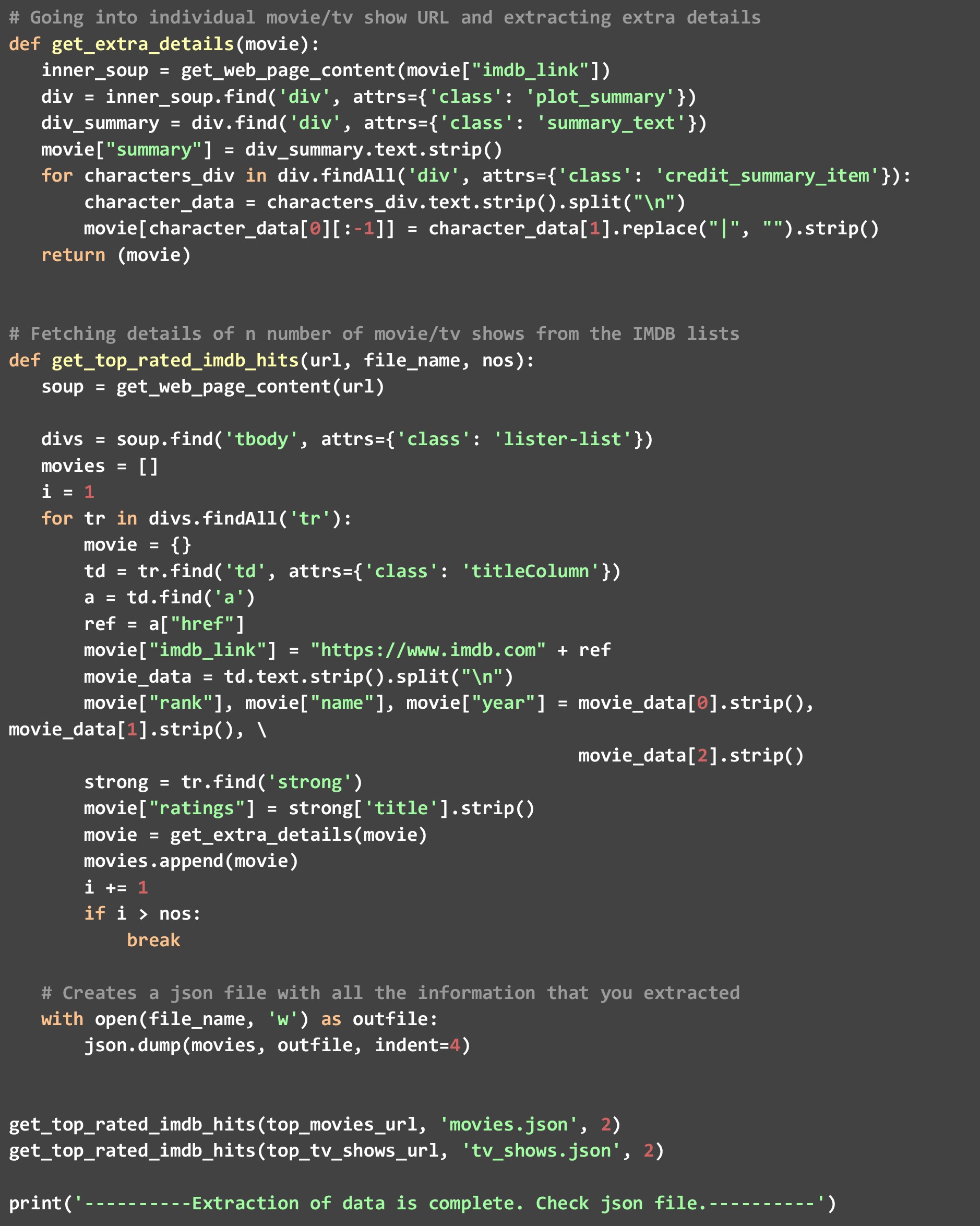

如您所見,我們調用了函數 get_top_rated_imdb_hits 兩次,一次使用電影 URL,一次使用電視節目 URL。 我們也將計數傳遞為 2,因為我們只想要兩個列表中前兩個候選人的數據。 運行此代碼後,您將看到在您的目錄中創建了兩個文件 - “movies.json”和“tv_shows.json”。
我們提取的數據點
對於每部電影或電視節目,我們提取了這些數據點。
一個)。 特定節目/電影的 IMDB 鏈接
乙)。 秩
C)。 姓名
d)。 年
e)。 收視率
F)。 概括
G)。 導向器
H)。 作家
一世)。 星星
需要注意的一點是,並非每部電影或節目的所有數據點都可用,但任何可用的數據點都將被廢棄。 下面的 JSON 顯示了我們在運行上面的代碼時獲得的 IMDB 中前 250 部電影列表中的前 2 部電影。
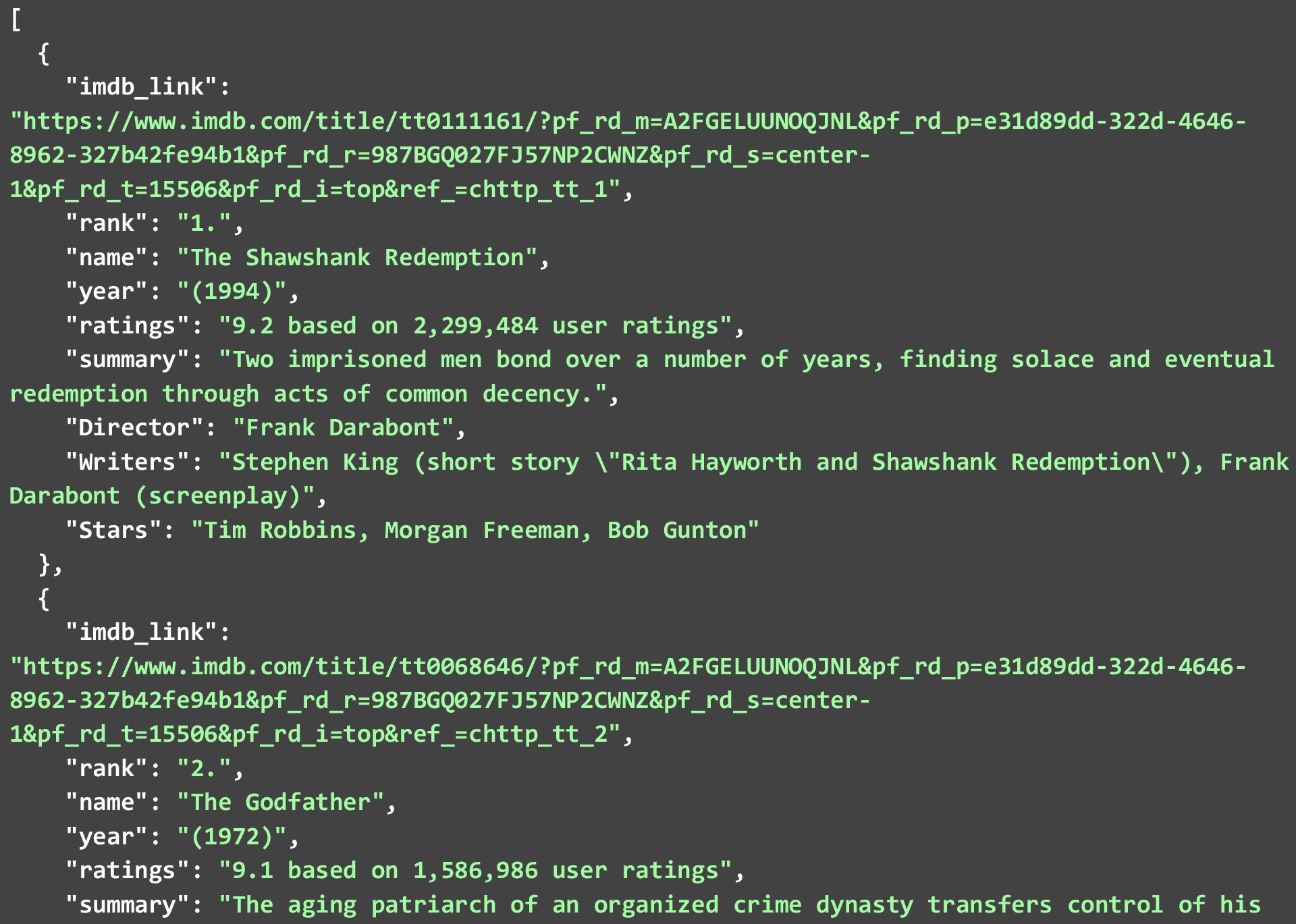

雖然我們已經按原樣抓取數據並對數據本身進行了最小的更改。 您可以進一步清理數據以使數據點更可用。 幾個例子是
一個)。 去掉年份的括號。
乙)。 將評分分為 2 個單獨的數據點,評分和提交評分的人數。
下面的 JSON 顯示了我們從第二個網頁中提取的前 2 個電視節目。 由於那裡有許多這樣的網絡抓取工具。 讓我們看看如何從他們的網站上為不同的電視節目抓取 IMDB 數據。 下面的代碼是如何完成的詳細說明。
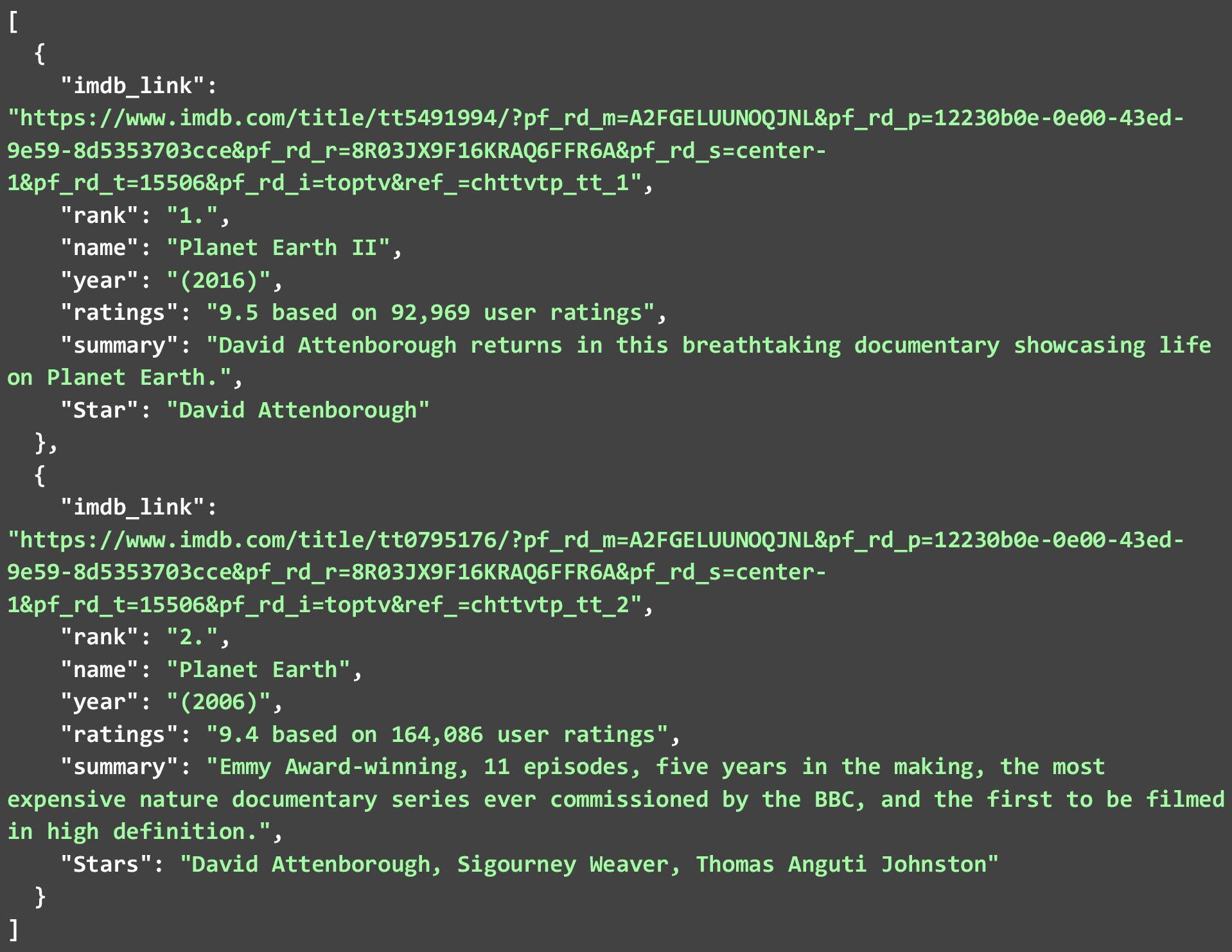
雖然我們從每個列表中只提取了 2 個。 您可以允許代碼為所有 250 個節目或電影運行,並創建一個巨大的 JSON 文件。 您甚至可以將提取的數據存儲在數據庫中。 但是為了在這麼多鏈接上運行代碼。 在網絡抓取 IMDB 數據時,您需要遵循一些最佳實踐並牢記一些限制。
約束和最佳實踐
如果您運行此代碼並將“nos”的值更改為 250,並在所有 250 部電影和電視節目中運行該代碼。 該網站很有可能會檢測到來自您 IP 的自動流量,而您最終會被阻止。 您將需要使用 IP 輪換等工具。 您還可以在抓取每個 URL 的 HTML 內容之間創建幾秒鐘的等待時間。
至於你抓取的數據,即使它的大部分內容都是由志願者創建的。 數據的商業用途可能存在某些限制。 無論您使用從不同網頁抓取的數據,都需要遵守規定。 這就是使用 Python 抓取 IMDB 數據的方式。
但是,如果您想要一個無憂無慮的網絡抓取體驗,有人負責處理數據並且您可以專注於您的核心業務模型,我們PromptCloud的團隊將為您服務。 我們為自己處理一切事務的 DaaS 解決方案感到自豪。 從抓取到訪問抓取的數據。
如果您喜歡上面的內容,我們相信您也想閱讀此內容。 請在下面的評論部分留下您的寶貴意見。