
Web Scraping IMDB para os melhores filmes e programas
Publicados: 2020-12-08Gostaria de saber quais são os 250 melhores filmes de todos os tempos? Ou os melhores programas de comédia que já chegaram às telas pequenas? Para todas essas respostas, resenhas, classificações e curiosidades relacionadas ao mundo dos filmes e programas, pessoas de todo o mundo usam o IMDB, que é um banco de dados online dessas informações. Enquanto as informações são atualizadas pelos fãs, o próprio banco de dados pertence e é operado por uma subsidiária da Amazon. Ele foi criado inicialmente como um banco de dados em 1990 e movido para a web em 1993. Embora qualquer pessoa possa acessar as informações no site, o registro é obrigatório caso você queira editar os fatos ou adicionar comentários. Neste blog, veremos como a extração de dados IMDB da Web é feita usando Python.
Além de vários pontos de dados atualizados para filmes e programas de tela pequena, o IMDB também permite que seus usuários adicionem classificações e essas classificações formaram a base de várias listas usadas por cinéfilos e outros para criar suas listas de observação. Embora o IMDB não forneça uma API para consultar seus dados, ele permite que você baixe os dados em formato textual. Você também pode raspar os dados usando um código DIY.
Como é feito o Web Scraping de dados do IMDB?
Vamos extrair 2 conjuntos de dados do IMDB
uma). Os 250 melhores filmes do IMDB
b). Os 250 melhores programas de televisão do IMDB
Vamos extrair certos pontos de dados para cada filme ou programa nessas listas. Você pode não querer raspar todos os dados de uma vez e, portanto, fornecemos a opção de alterar o valor de um parâmetro para extrair apenas os n principais resultados.
Você precisará do Python3.7 ou superior junto com a dependência BeautifulSoup e um editor de texto antes de começarmos. Então você pode executar o código abaixo usando o próprio comando python. Nenhuma entrada do usuário é necessária, pois codificamos os links das duas listas que mencionamos anteriormente no código.
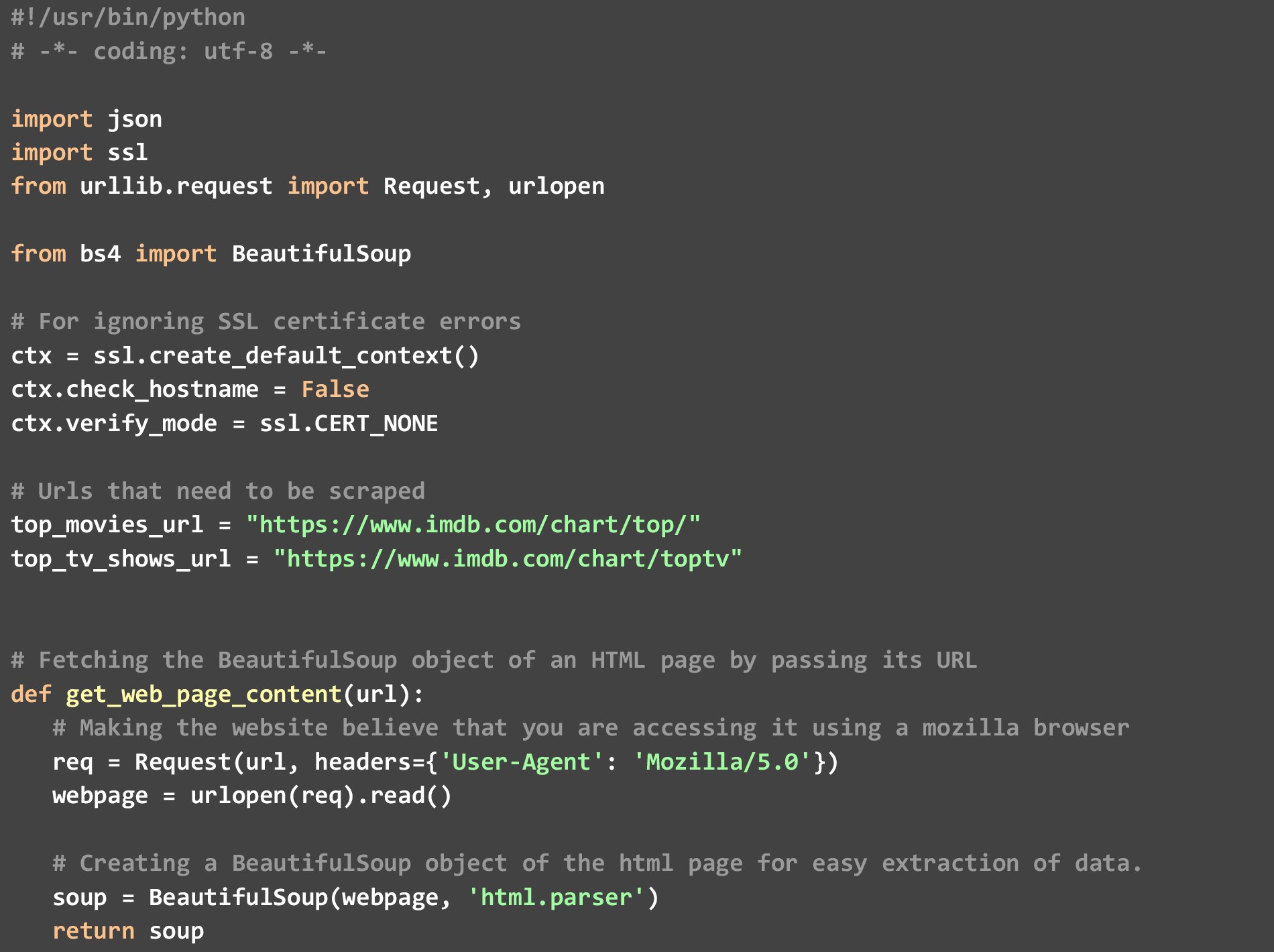
No código, temos 3 funções específicas
uma). get_top_rated_imdb_hits- Aqui é onde a execução começa. Como entrada para esta função, passamos a URL da lista em questão. Pode ser o URL da lista de filmes ou o URL da lista de programas de TV. Também passamos o nome do arquivo no qual queremos o resultado JSON e o número de principais resultados que queremos. Buscamos certos pontos de dados, como o nome do filme e as classificações que estão disponíveis na própria página da web, e então chamamos a função get_extra_details ignorando o URL específico do filme/show para buscar pontos de dados extras.
b). get_web_page_content- Esta função é usada para buscar o conteúdo HTML do URL passado para ele e convertê-lo em um objeto BeautifulSoup que pode ser facilmente analisado. Este objeto é o que esta função retorna.
c). get_extra_details- Essa função usa o URL específico do filme ou programa passado para ela pela função get_top_rated_imdb_hits para buscar mais detalhes, como o resumo, o nome das principais estrelas e as informações do diretor não disponíveis na página da lista de classificação.
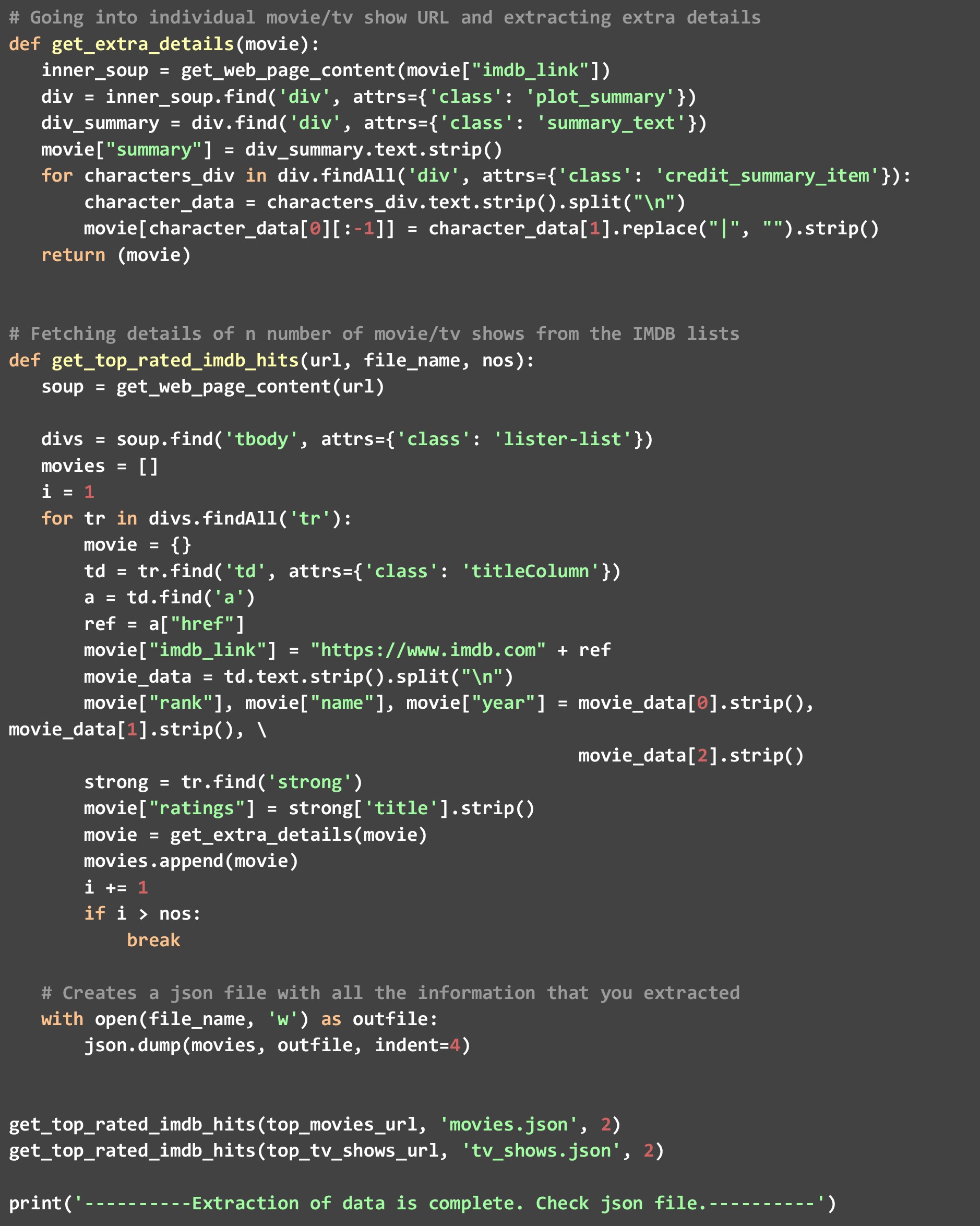
Como você pode ver, chamamos a função get_top_rated_imdb_hits duas vezes, uma com a URL dos filmes e outra com a URL dos programas de TV. Também passamos a contagem como 2, pois queremos os dados apenas para os dois principais candidatos em ambas as listas. Assim que este código for executado, você verá dois arquivos criados em seu diretório - “movies.json” e “tv_shows.json”.

Os pontos de dados que extraímos
Para cada filme ou programa de TV, extraímos esses pontos de dados.
uma). Link do IMDB para o programa/filme específico
b). Classificação
c). Nome
d). Ano
e). Classificações
f). Resumo
g). Diretor
h). Escritoras
eu). Estrelas
Uma coisa a notar é que nem todos os pontos de dados podem estar disponíveis para cada filme ou programa, mas o que estiver disponível será descartado. O JSON abaixo mostra os 2 principais filmes na lista dos 250 principais filmes no IMDB que obtivemos ao executar o código acima.
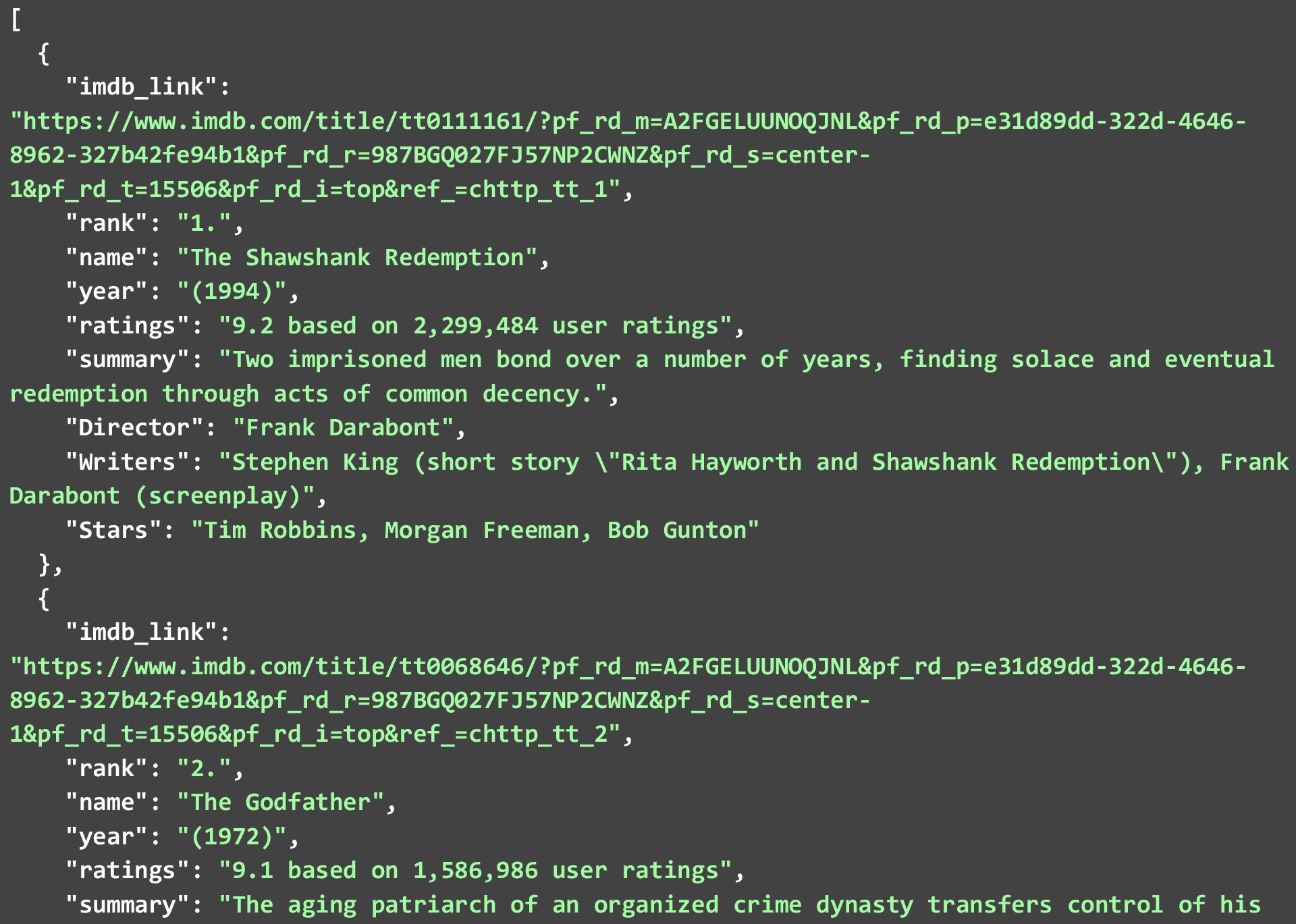

Embora tenhamos raspado os dados como estavam e feito alterações mínimas nos próprios dados. Você pode limpar ainda mais os dados para tornar os pontos de dados mais utilizáveis. Alguns exemplos seriam
uma). Removendo os colchetes no ano.
b). Dividindo as classificações em 2 pontos de dados separados, as classificações e o número de pessoas que enviaram suas classificações.
O JSON abaixo mostra os 2 principais programas de TV que extraímos da segunda página da web. Uma vez que muitos desses raspadores da web estão disponíveis por aí. Vamos dar uma olhada em como podemos extrair dados do IMDB de seu site para diferentes programas de TV . O código abaixo é uma explicação detalhada de como isso pode ser feito.
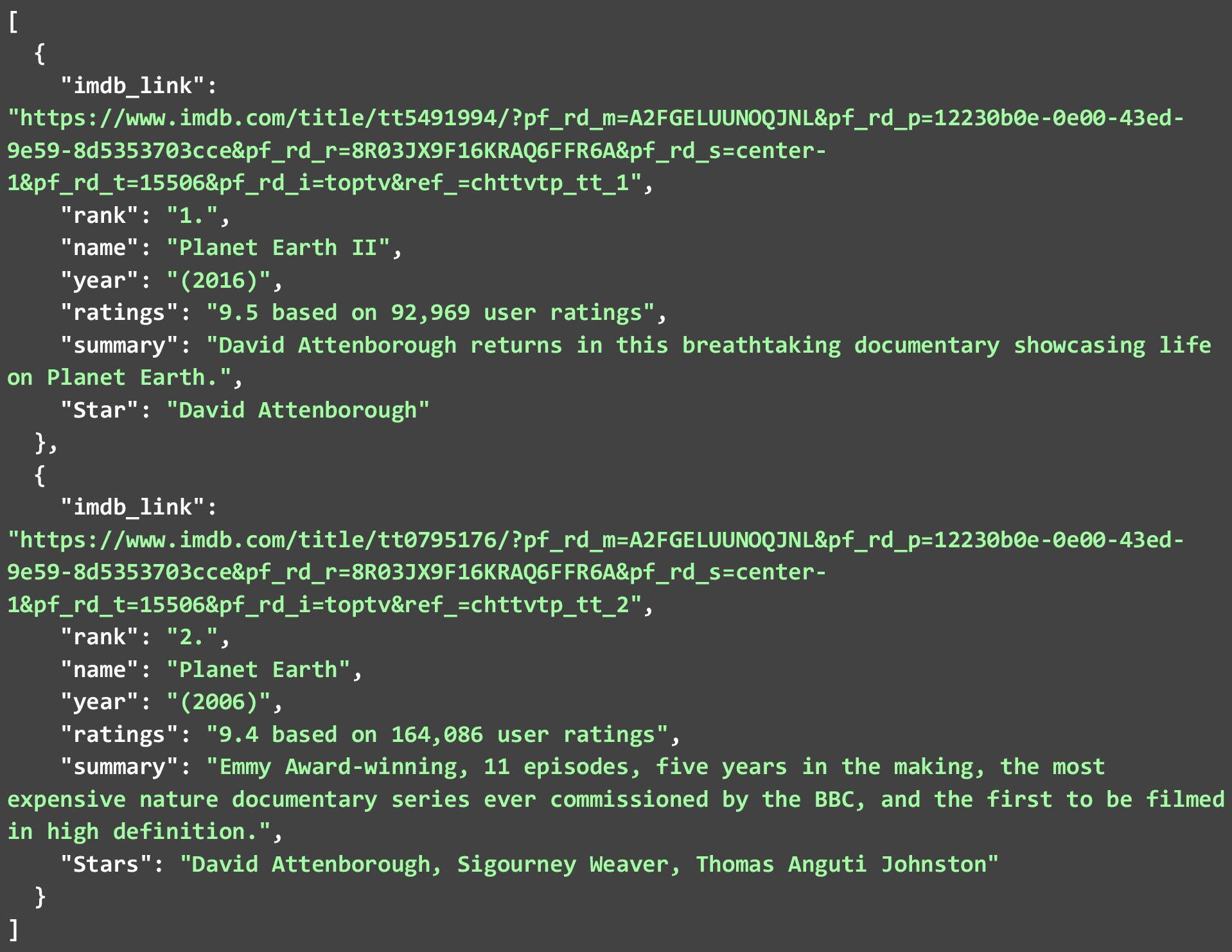
Enquanto extraímos apenas 2 de cada lista. Você pode permitir que o código seja executado para todos os 250 programas ou filmes e criar um arquivo JSON enorme. Você pode até armazenar os dados que você extrai em um banco de dados. Mas para executar o código em tantos links. Você precisará seguir algumas práticas recomendadas e manter algumas restrições em mente ao extrair dados IMDB da Web.
Restrições e práticas recomendadas
Caso você executou este código e alterou o valor de “nos” para dizer 250 e executou o código em todos os 250 filmes e programas de TV. Há uma grande chance de que o site detecte tráfego automatizado do seu IP e você acabe sendo bloqueado. Você precisará usar ferramentas como rotação de IP. Você também pode criar um tempo de espera de alguns segundos entre a extração do conteúdo HTML de cada URL.
Quanto aos dados que você raspa, mesmo que a maior parte de seu conteúdo seja criada por voluntários. Pode haver certas restrições sobre o uso comercial dos dados. Você precisa seguir os regulamentos onde quer que esteja usando dados extraídos de diferentes páginas da web. É assim que os dados do IMDB são raspados na Web usando o Python.
No entanto, se você deseja uma experiência de web scraping sem complicações, onde alguém cuida dos dados e você pode se concentrar em seu modelo de negócios principal, nossa equipe da PromptCloud está à sua disposição. Orgulhamo-nos da nossa solução DaaS, onde cuidamos de tudo. Desde a raspagem até o acesso aos dados raspados.
Se você gostou do conteúdo acima, temos certeza que você gostaria de ler este também. Por favor, deixe-nos o seu feedback valioso na seção de comentários abaixo.