
Web Scraping IMDB สำหรับภาพยนตร์และรายการที่ดีที่สุด
เผยแพร่แล้ว: 2020-12-08คุณต้องการที่จะรู้ว่าอะไรคือภาพยนตร์ 250 อันดับแรกตลอดกาล? หรือรายการตลกที่ดีที่สุดที่เคยฉายในจอเล็ก? สำหรับคำตอบ บทวิจารณ์ การให้คะแนน และเรื่องไม่สำคัญทั้งหมดที่เกี่ยวข้องกับโลกของภาพยนตร์และรายการ ผู้คนทั่วโลกใช้ IMDB ซึ่งเป็นฐานข้อมูลออนไลน์ของข้อมูลดังกล่าว ในขณะที่ข้อมูลได้รับการอัพเดตโดยแฟน ๆ ฐานข้อมูลนั้นเป็นเจ้าของและดำเนินการโดย บริษัท ย่อยของ Amazon เริ่มแรกสร้างเป็นฐานข้อมูลในปี 1990 และย้ายไปยังเว็บในปี 1993 แม้ว่าทุกคนจะสามารถเข้าถึงข้อมูลบนเว็บไซต์ได้ แต่การลงทะเบียนเป็นสิ่งจำเป็นในกรณีที่คุณต้องการแก้ไขข้อเท็จจริงหรือเพิ่มบทวิจารณ์ ในบล็อกนี้ เราจะมาดูวิธีการดึงข้อมูล IMDB ของเว็บโดยใช้ Python
นอกเหนือจากจุดข้อมูลต่างๆ ที่ได้รับการอัปเดตสำหรับทั้งภาพยนตร์และรายการบนหน้าจอขนาดเล็กแล้ว IMDB ยังอนุญาตให้ผู้ใช้เพิ่มการให้คะแนน และการให้คะแนนเหล่านี้ได้สร้างพื้นฐานของหลายรายการที่ใช้โดยผู้ชื่นชอบภาพยนตร์และอื่นๆ เพื่อสร้างรายการเฝ้าดูของพวกเขา แม้ว่า IMDB จะไม่มี API ในการสืบค้นข้อมูล แต่ก็อนุญาตให้คุณดาวน์โหลดข้อมูลในรูปแบบข้อความได้ คุณยังสามารถขูดข้อมูลโดยใช้รหัส DIY
การขูดเว็บของข้อมูล IMDB ทำอย่างไร?
เราจะทำการดึงข้อมูล 2 ชุดจาก IMDB
ก) ภาพยนตร์ 250 อันดับแรกของ IMDB
ข) IMDB รายการโทรทัศน์ 250 อันดับแรก
เราจะทำการขูดจุดข้อมูลบางอย่างสำหรับภาพยนตร์หรือรายการแต่ละรายการในรายการเหล่านี้ คุณอาจไม่ต้องการขูดข้อมูลทั้งหมดในคราวเดียว และด้วยเหตุนี้เราจึงมีตัวเลือกในการเปลี่ยนค่าของพารามิเตอร์ เพื่อดึงเฉพาะผลลัพธ์ n อันดับแรกเท่านั้น
คุณจะต้องใช้ Python3.7 หรือสูงกว่าพร้อมกับการพึ่งพา BeautifulSoup และโปรแกรมแก้ไขข้อความก่อนที่เราจะเริ่ม จากนั้นคุณสามารถเรียกใช้โค้ดที่ระบุด้านล่างโดยใช้คำสั่ง python ผู้ใช้ไม่จำเป็นต้องป้อนข้อมูลใดๆ เนื่องจากเราได้ทำฮาร์ดโค้ดลิงก์ของสองรายการที่เรากล่าวถึงก่อนหน้านี้ในโค้ดแล้ว
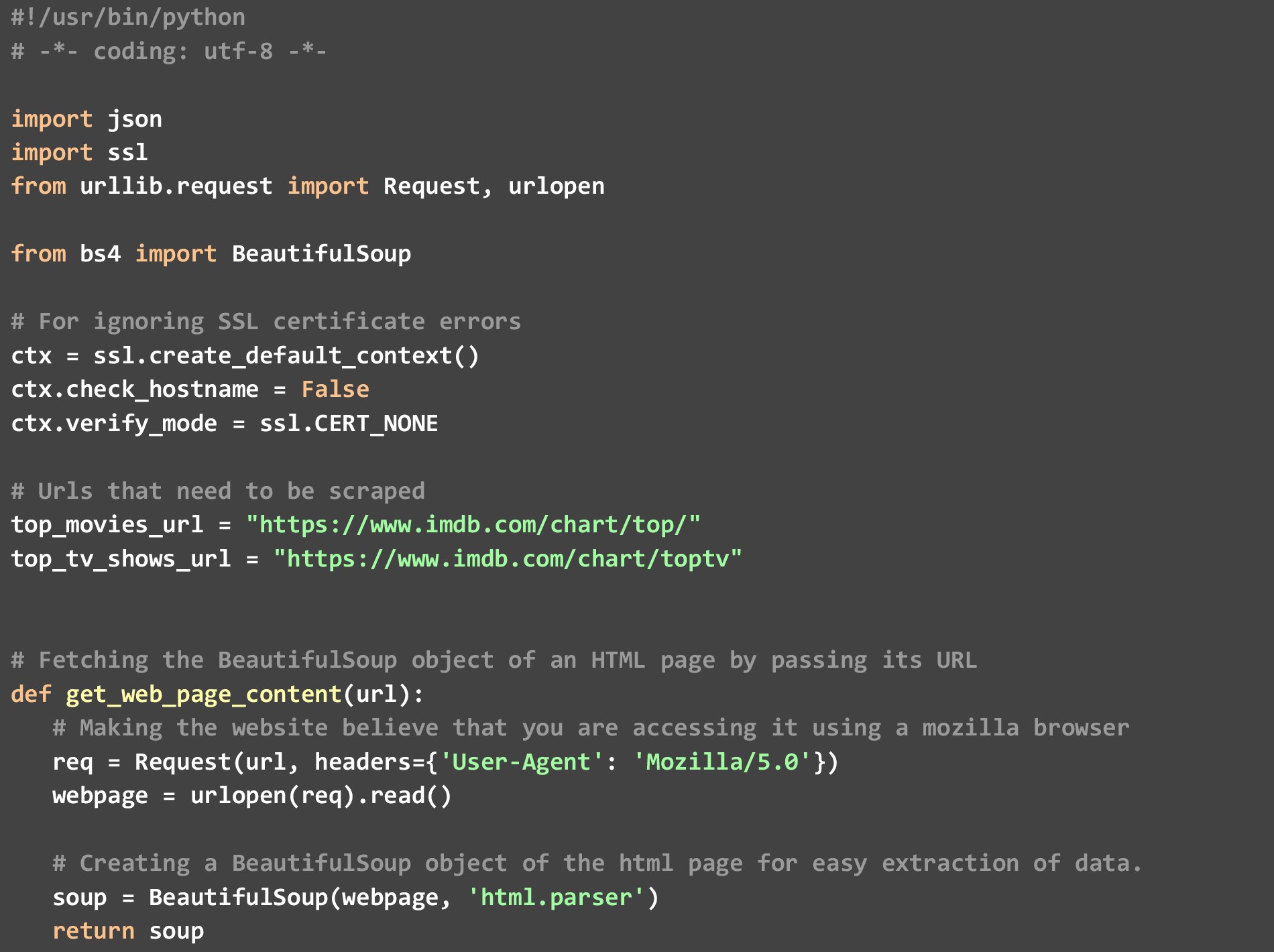
ในโค้ดนี้ เรามีฟังก์ชันเฉพาะอยู่ 3 ฟังก์ชัน
ก) get_top_rated_imdb_hits- นี่คือจุดเริ่มต้นของการดำเนินการ ในการป้อนฟังก์ชันนี้ เราส่ง URL ของรายการที่เกี่ยวข้อง อาจเป็น URL ของรายการภาพยนตร์หรือ URL รายการทีวีก็ได้ นอกจากนี้เรายังส่งชื่อไฟล์ที่เราต้องการผลลัพธ์ JSON และจำนวนผลลัพธ์อันดับต้น ๆ ที่เราต้องการ เราดึงข้อมูลจุดข้อมูลบางอย่าง เช่น ชื่อภาพยนตร์และการจัดเรตที่มีอยู่ในหน้าเว็บ จากนั้นเรียกใช้ฟังก์ชัน get_extra_details โดยข้าม URL เฉพาะของภาพยนตร์/รายการเพื่อดึงข้อมูลจุดข้อมูลเพิ่มเติม
ข) get_web_page_content- ฟังก์ชันนี้ใช้เพื่อดึงเนื้อหา HTML ของ URL ที่ส่งผ่านเข้าไป และแปลงเป็นวัตถุ BeautifulSoup ที่สามารถแยกวิเคราะห์ได้ง่าย วัตถุนี้คือสิ่งที่ฟังก์ชันนี้ส่งคืน
ค). get_extra_details- ฟังก์ชันนี้ใช้ URL เฉพาะของภาพยนตร์หรือรายการที่แสดงโดยฟังก์ชัน get_top_rated_imdb_hits เพื่อดึงรายละเอียดเพิ่มเติม เช่น สรุป ชื่อของดาราชั้นนำ และข้อมูลผู้กำกับที่ไม่มีในหน้าเว็บที่มีการจัดอันดับ
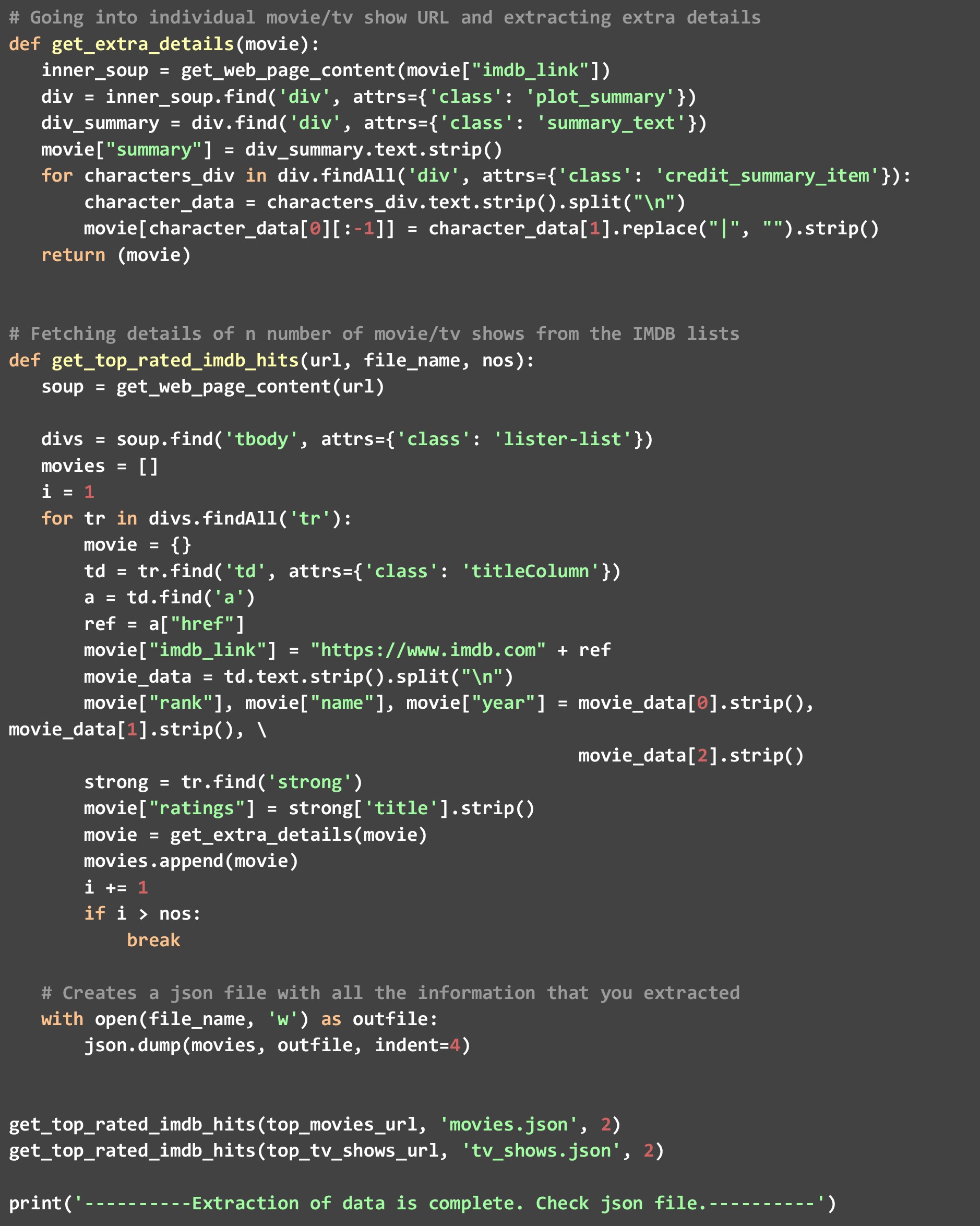

อย่างที่คุณเห็น เราได้เรียกใช้ฟังก์ชัน get_top_rated_imdb_hits สองครั้ง ครั้งเดียวกับ URL ภาพยนตร์ และอีกครั้งกับ URL รายการทีวี เรายังผ่านการนับเป็น 2 เนื่องจากเราต้องการข้อมูลเฉพาะสำหรับผู้สมัครสองอันดับแรกในทั้งสองรายการ เมื่อโค้ดนี้ทำงาน คุณจะเห็นไฟล์สองไฟล์ที่สร้างขึ้นในไดเร็กทอรีของคุณ - “movies.json” และ “tv_shows.json”
จุดข้อมูลที่เราแยกออกมา
สำหรับภาพยนตร์หรือรายการทีวีแต่ละรายการ เราแยกจุดข้อมูลเหล่านี้
ก) ลิงก์ IMDB สำหรับรายการ/ภาพยนตร์ที่เฉพาะเจาะจง
ข) อันดับ
ค). ชื่อ
ง) ปี
จ) คะแนน
ฉ) สรุป
กรัม) ผู้อำนวยการ
ชม). นักเขียน
ผม). ดาว
สิ่งหนึ่งที่ควรทราบคือจุดข้อมูลบางจุดอาจไม่มีให้สำหรับภาพยนตร์หรือรายการแต่ละเรื่อง แต่ส่วนใดที่มีอยู่จะถูกทิ้ง JSON ด้านล่างแสดงภาพยนตร์ 2 อันดับแรกในรายการภาพยนตร์ 250 อันดับแรกใน IMDB ที่เราได้รับจากการเรียกใช้โค้ดด้านบน
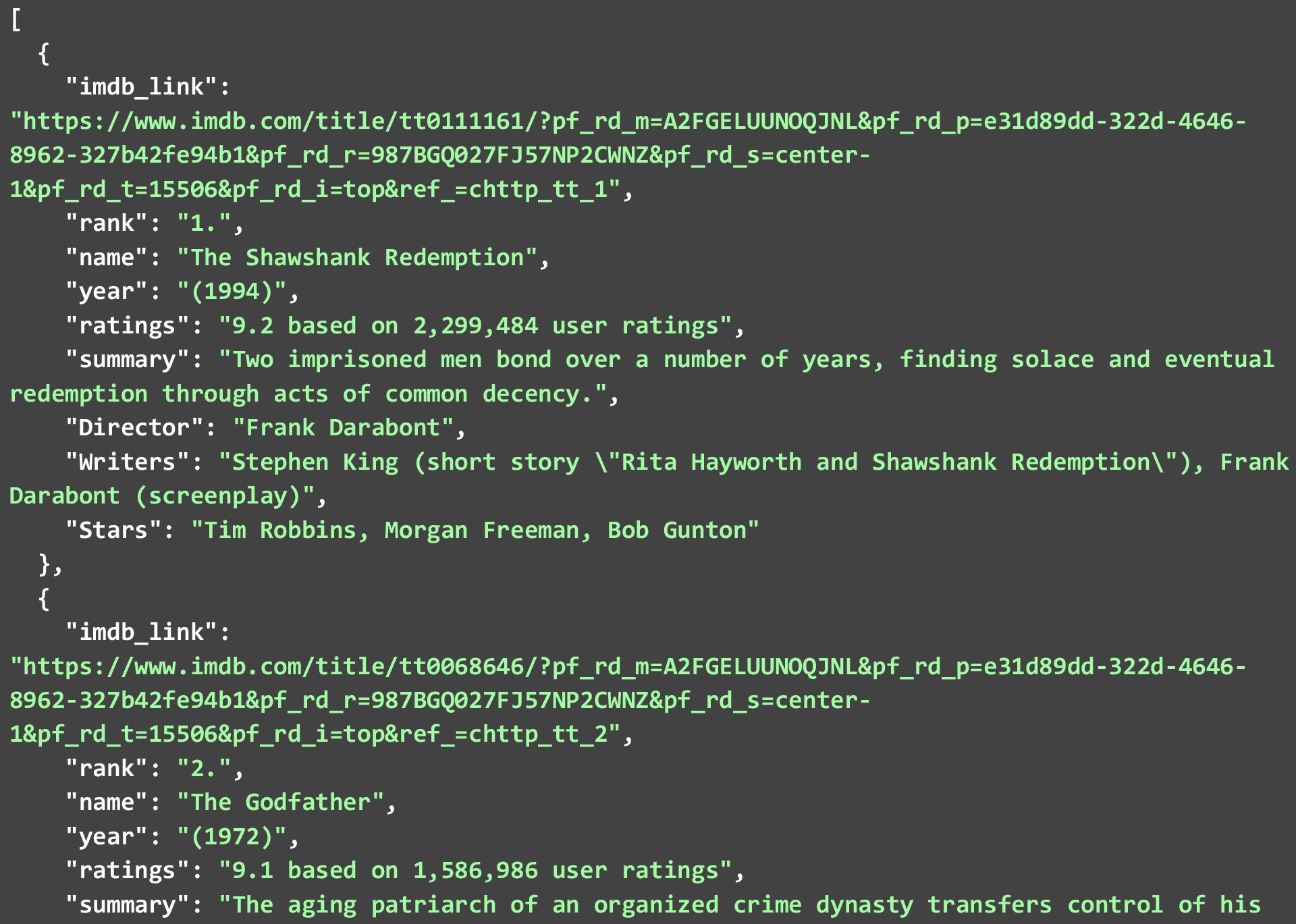

ในขณะที่เราได้คัดลอกข้อมูลตามที่เป็นอยู่และทำการเปลี่ยนแปลงเพียงเล็กน้อยกับข้อมูลนั้นเอง คุณสามารถล้างข้อมูลเพิ่มเติมเพื่อให้จุดข้อมูลใช้งานได้มากขึ้น ตัวอย่างบางส่วนจะเป็น
ก) การถอดวงเล็บปี
ข) แบ่งการให้คะแนนออกเป็น 2 จุดข้อมูลแยกกัน การให้คะแนนและจำนวนผู้ที่ส่งการให้คะแนน
JSON ด้านล่างแสดงรายการทีวี 2 อันดับแรกที่เราดึงมาจากหน้าเว็บที่สอง เนื่องจากมีเครื่องขูดเว็บดังกล่าวจำนวนมาก ให้เรามาดูกันว่าเราสามารถ ขูดข้อมูล IMDB จากเว็บไซต์ของพวกเขาสำหรับรายการทีวี ต่างๆ ได้อย่างไร รหัสด้านล่างเป็นคำอธิบายโดยละเอียดเกี่ยวกับวิธีการทำ
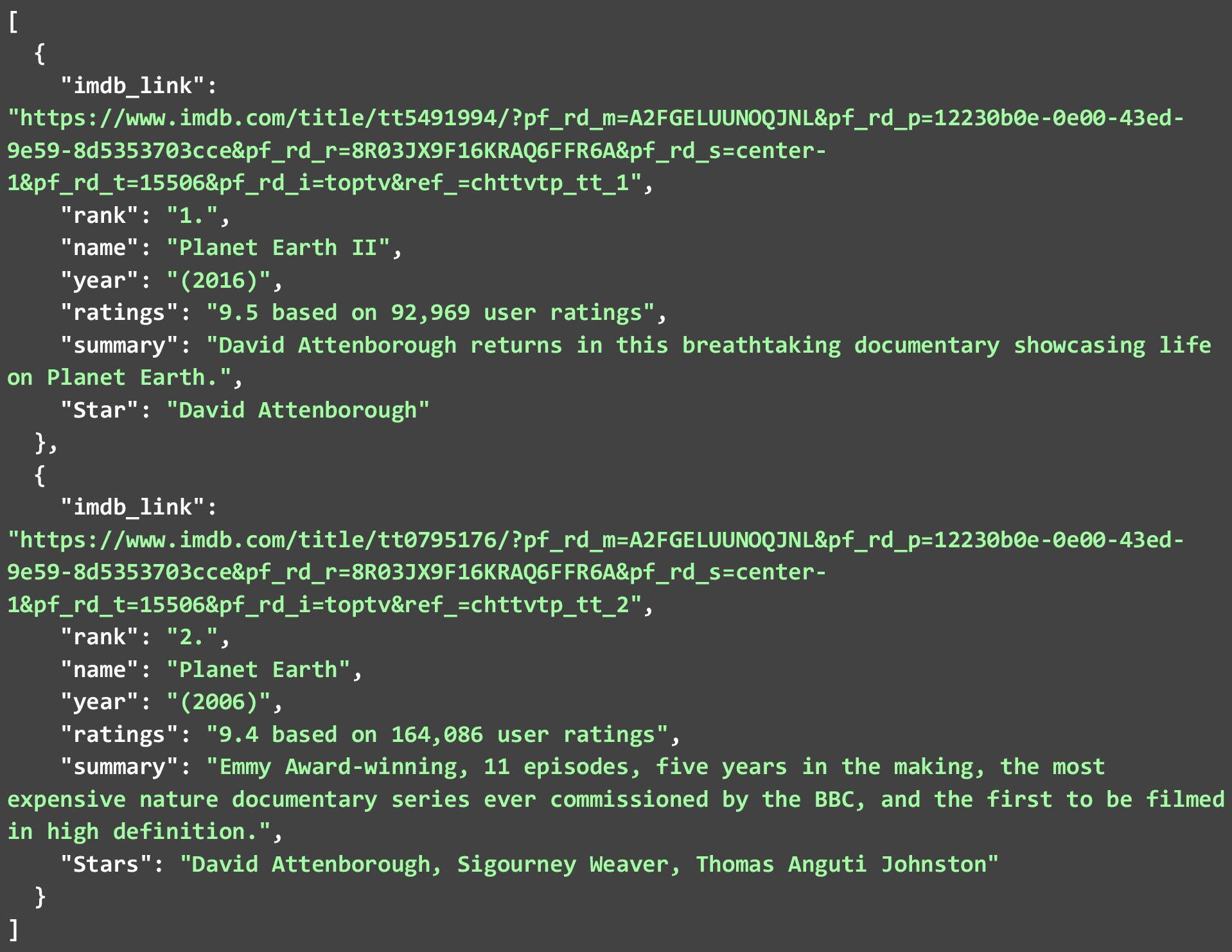
ในขณะที่เราได้แยกเพียง 2 รายการจากแต่ละรายการ คุณสามารถอนุญาตให้โค้ดรันสำหรับรายการหรือภาพยนตร์ทั้งหมด 250 เรื่อง และสร้างไฟล์ JSON ขนาดใหญ่ได้ คุณยังสามารถจัดเก็บข้อมูลที่คุณดึงข้อมูลในฐานข้อมูลได้ แต่สำหรับการรันโค้ดบนลิงค์มากมาย คุณจะต้องปฏิบัติตามแนวทางปฏิบัติที่ดีที่สุดและคำนึงถึงข้อจำกัดบางประการในขณะที่เว็บกำลังดึงข้อมูล IMDB
ข้อจำกัดและแนวทางปฏิบัติที่ดีที่สุด
ในกรณีที่คุณรันโค้ดนี้และเปลี่ยนค่าของ "nos" เป็น 250 และรันโค้ดในภาพยนตร์และรายการทีวีทั้งหมด 250 เรื่อง มีโอกาสสูงที่เว็บไซต์จะตรวจจับการเข้าชมอัตโนมัติจาก IP ของคุณและคุณจะถูกบล็อก คุณจะต้องใช้เครื่องมือเช่นการหมุน IP คุณยังสามารถสร้างเวลารอสองสามวินาทีระหว่างการคัดลอกเนื้อหา HTML ของแต่ละ URL
ส่วนข้อมูลที่คุณขูด แม้ว่าเนื้อหาส่วนใหญ่จะสร้างโดยอาสาสมัครก็ตาม อาจมีข้อจำกัดบางประการเกี่ยวกับการใช้ข้อมูลในเชิงพาณิชย์ คุณต้องปฏิบัติตามข้อบังคับทุกที่ที่คุณใช้ข้อมูลที่คัดลอกมาจากหน้าเว็บต่างๆ นี่คือวิธีที่เว็บดึงข้อมูล IMDB โดยใช้ Python
อย่างไรก็ตาม หากคุณต้องการประสบการณ์การขูดเว็บที่ไม่ยุ่งยากซึ่งมีผู้ดูแลข้อมูลและคุณสามารถมุ่งเน้นไปที่รูปแบบธุรกิจหลักของคุณ ทีมงานของเราที่ PromptCloud พร้อมให้บริการคุณ เราภูมิใจในโซลูชัน DaaS ที่เราดูแลทุกอย่าง ตั้งแต่การขูดไปจนถึงการเข้าถึงข้อมูลที่คัดลอกมา
หากคุณชอบเนื้อหาข้างต้น เรามั่นใจว่าคุณต้องการอ่าน สิ่งนี้ เช่นกัน โปรดฝากความคิดเห็นอันมีค่าของคุณไว้ในส่วนความคิดเห็นด้านล่าง