
Web Scraping IMDB untuk Film dan Acara Terbaik
Diterbitkan: 2020-12-08Apakah Anda ingin tahu apa saja 250 film teratas sepanjang masa? Atau acara komedi terbaik yang pernah tayang di layar kaca? Untuk semua jawaban, ulasan, peringkat, dan hal-hal sepele yang terkait dengan dunia film dan pertunjukan, orang-orang di seluruh dunia menggunakan IMDB, yang merupakan basis data online dari informasi tersebut. Sementara informasi diperbarui oleh penggemar, database itu sendiri dimiliki dan dioperasikan oleh anak perusahaan Amazon. Awalnya dibuat sebagai database pada tahun 1990 dan dipindahkan ke web pada tahun 1993. Meskipun siapa pun dapat mengakses informasi di situs web, pendaftaran adalah suatu keharusan jika Anda ingin mengedit fakta atau menambahkan ulasan. Di blog ini, kita melihat bagaimana web scraping data IMDB dilakukan dengan menggunakan Python.
Di atas berbagai titik data yang diperbarui untuk film dan pertunjukan layar kecil, IMDB juga memungkinkan penggunanya untuk menambahkan peringkat dan peringkat ini telah membentuk dasar dari beberapa daftar yang digunakan oleh penggemar film dan orang lain untuk membuat daftar tontonan mereka. Meskipun IMDB tidak menyediakan API untuk menanyakan datanya, IMDB memungkinkan Anda mengunduh data dalam format tekstual. Anda juga dapat mengikis data menggunakan kode DIY.
Bagaimana Pengikisan Web Data IMDB Dilakukan?
Kami akan menggores 2 set data dari IMDB
sebuah). 250 film teratas IMDB
b). 250 acara televisi teratas IMDB
Kami akan menggores titik data tertentu untuk setiap film atau acara di daftar ini. Anda mungkin tidak ingin mengikis semua data sekaligus, dan karenanya kami telah menyediakan opsi untuk mengubah nilai parameter, untuk mengekstrak hanya hasil n teratas.
Anda akan membutuhkan Python3.7 atau lebih tinggi bersama dengan ketergantungan BeautifulSoup dan editor teks sebelum kita mulai. Kemudian Anda dapat menjalankan kode yang diberikan di bawah ini menggunakan perintah python itu sendiri. Tidak ada input pengguna yang diperlukan karena kami telah membuat hardcode tautan dari dua daftar yang kami sebutkan sebelumnya dalam kode.
Dalam kode, kami memiliki 3 fungsi khusus
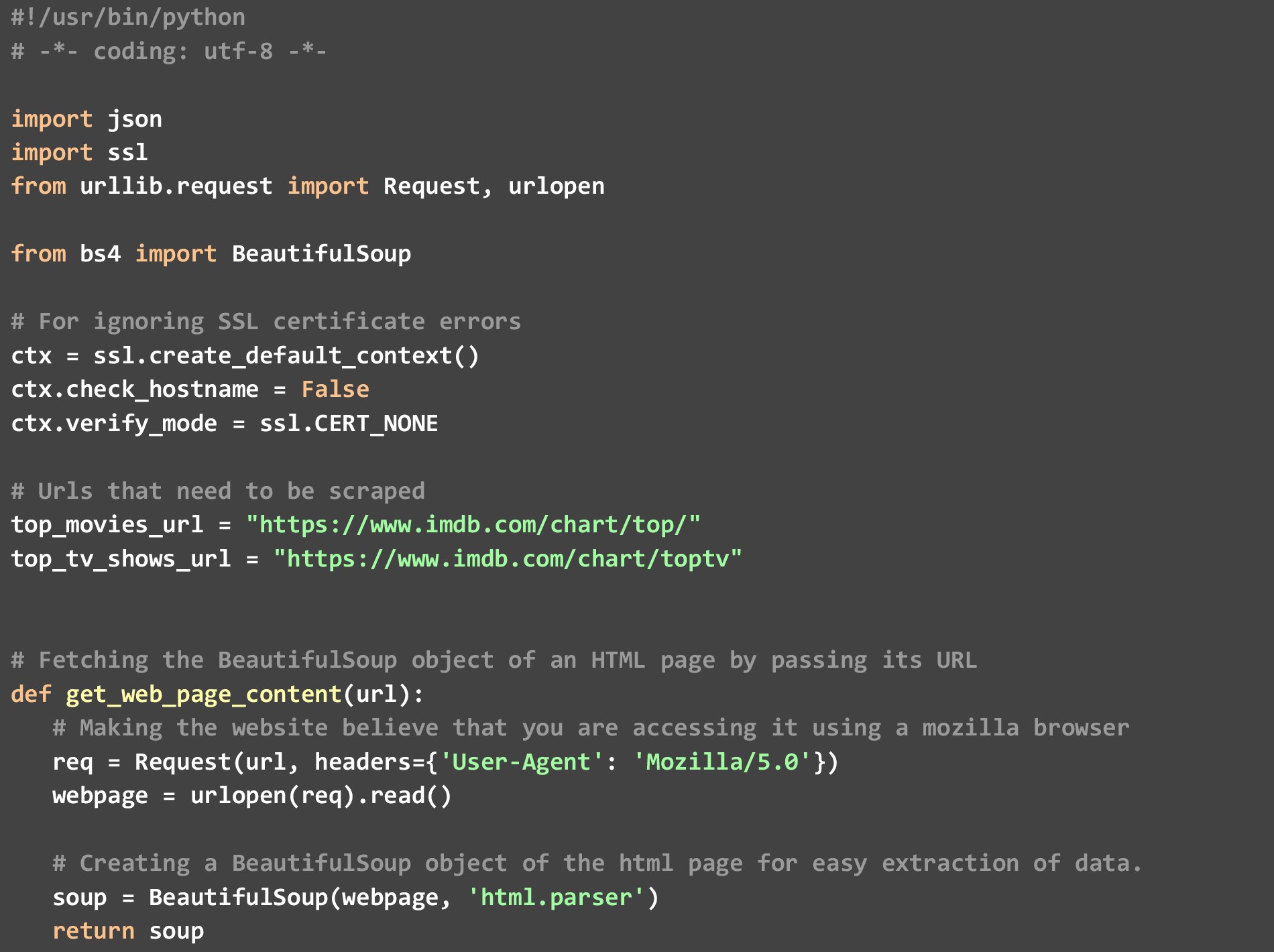
sebuah). get_top_rated_imdb_hits- Di sinilah eksekusi dimulai. Sebagai masukan ke fungsi ini, kami meneruskan URL dari daftar yang bersangkutan. Ini bisa berupa URL daftar film atau URL daftar acara tv. Kami juga memberikan nama file yang kami inginkan hasil JSON dan jumlah hasil teratas yang kami inginkan. Kami mengambil titik data tertentu seperti nama film dan peringkat yang tersedia di halaman web itu sendiri, dan kemudian memanggil fungsi get_extra_details melewati URL khusus film/tampilkan untuk mengambil titik data tambahan.
b). get_web_page_content- Fungsi ini digunakan untuk mengambil konten HTML dari URL yang dikirimkan ke dalamnya, dan mengubahnya menjadi objek BeautifulSoup yang dapat dengan mudah diuraikan. Objek inilah yang dikembalikan oleh fungsi ini.
c). get_extra_details- Fungsi ini menggunakan film atau URL khusus acara yang diteruskan ke dalamnya oleh fungsi get_top_rated_imdb_hits untuk mengambil lebih banyak detail seperti ringkasan, nama bintang teratas, dan informasi sutradara- tidak tersedia di halaman web daftar peringkat.
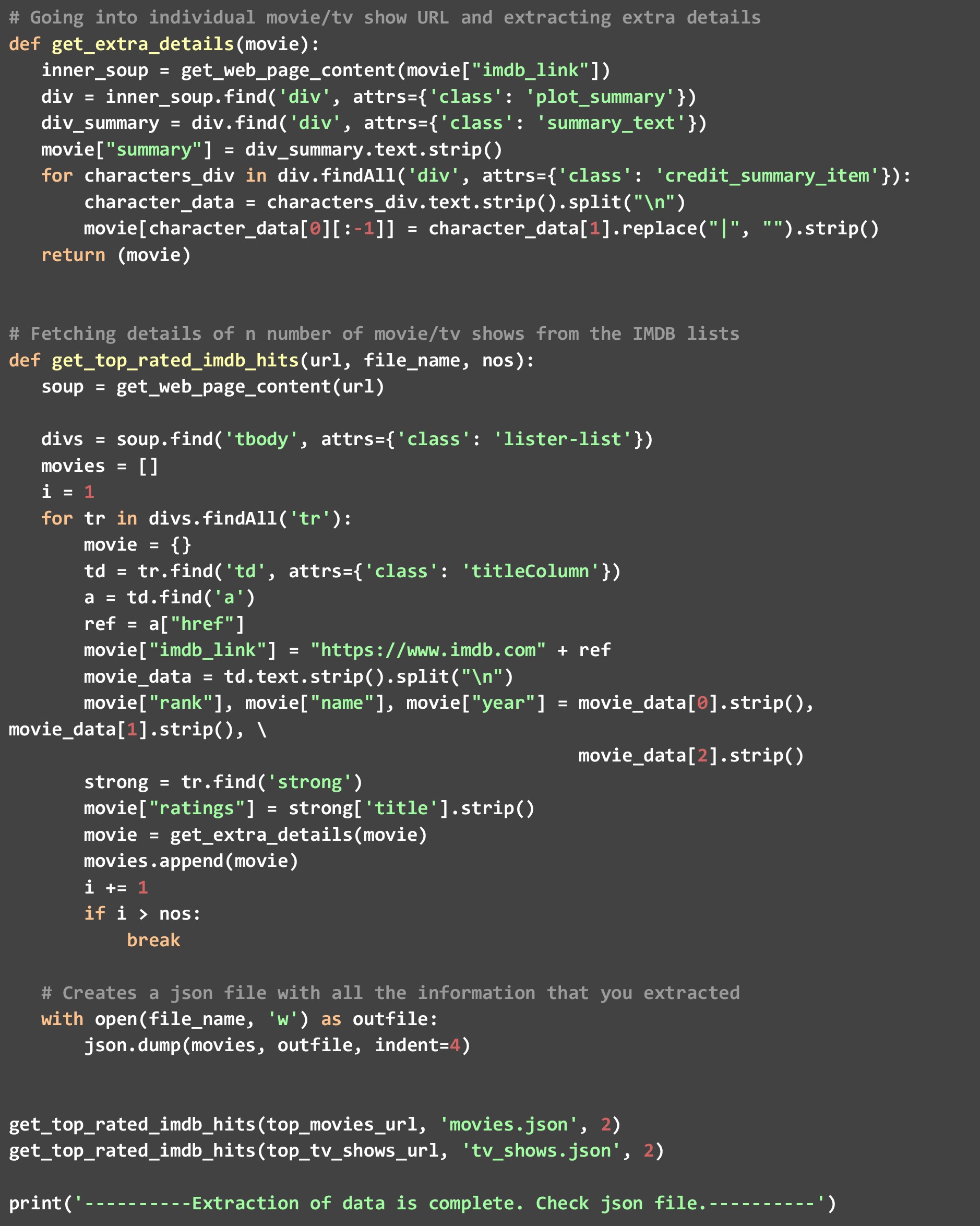

Seperti yang Anda lihat, kami telah memanggil fungsi get_top_rated_imdb_hits dua kali, sekali dengan URL film dan sekali dengan URL acara tv. Kami juga telah melewati hitungan sebagai 2 karena kami ingin data hanya untuk dua kandidat teratas di kedua daftar. Setelah kode ini berjalan, Anda akan melihat dua file yang dibuat di direktori Anda- “movies.json” dan “tv_shows.json”.
Poin Data Yang Kami Ekstrak
Untuk setiap film atau acara TV, kami mengekstrak titik data ini.
sebuah). Tautan IMDB untuk acara/film tertentu
b). Pangkat
c). Nama
d). Tahun
e). Peringkat
f). Ringkasan
g). Direktur
h). Penulis
saya). bintang
Satu hal yang perlu diperhatikan adalah bahwa tidak semua titik data mungkin tersedia untuk setiap film atau acara, tetapi mana pun yang tersedia akan dihapus. JSON di bawah ini menunjukkan 2 film teratas dalam daftar 250 film teratas di IMDB yang kami peroleh dengan menjalankan kode di atas.
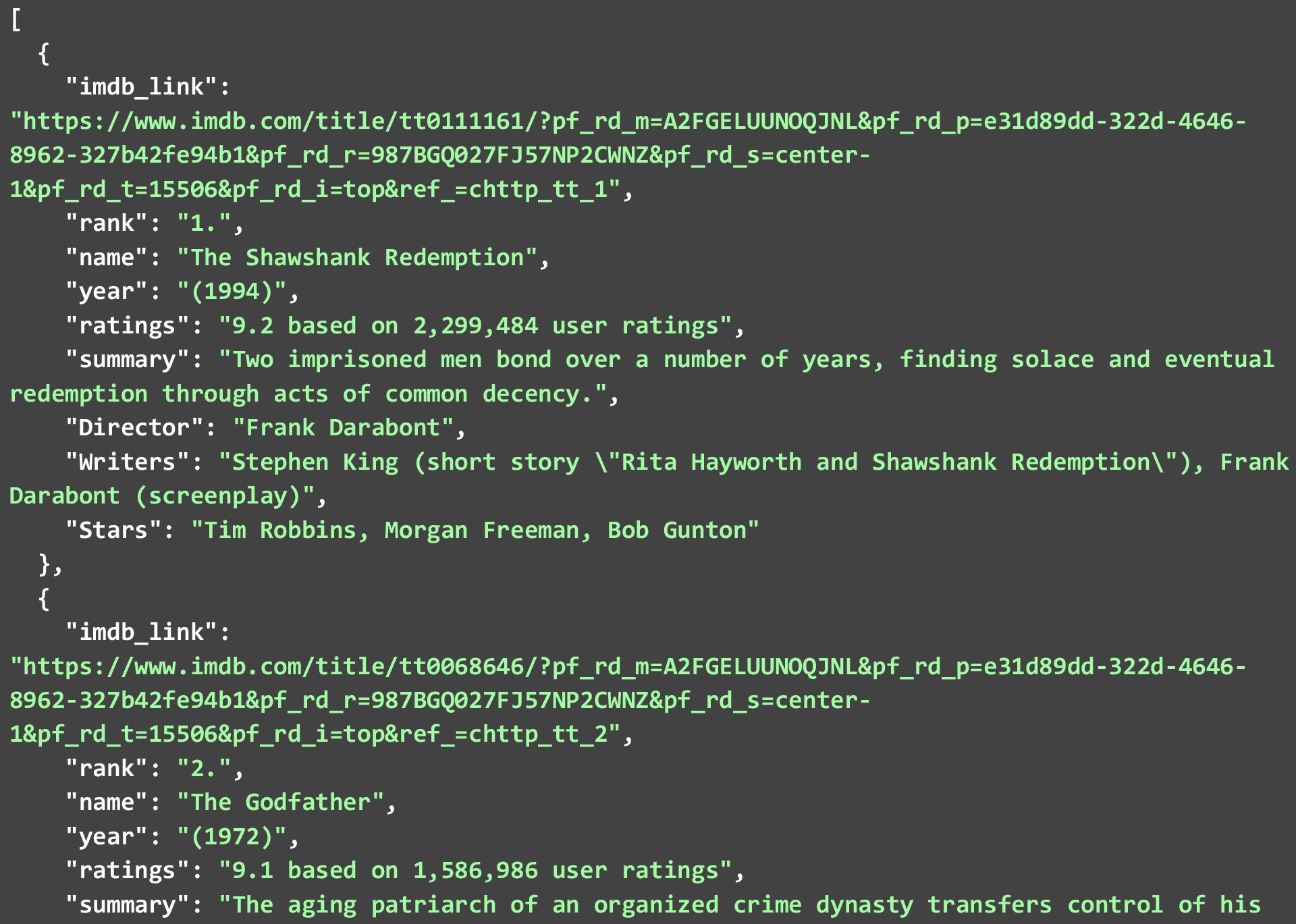

Sementara kami telah mengikis data apa adanya dan membuat sedikit perubahan pada data itu sendiri. Anda dapat membersihkan data lebih lanjut untuk membuat titik data lebih bermanfaat. Beberapa contoh adalah
sebuah). Menghapus tanda kurung pada tahun.
b). Memecah Peringkat menjadi 2 titik data terpisah, peringkat dan jumlah orang yang mengirimkan peringkat mereka.
JSON di bawah ini menunjukkan 2 acara tv teratas yang kami ekstrak dari halaman web kedua. Karena banyak pencakar web semacam itu tersedia di luar sana. Mari kita lihat bagaimana kita dapat mengikis data IMDB dari situs web mereka untuk Acara TV yang berbeda . Kode di bawah ini adalah penjelasan rinci tentang bagaimana hal itu dapat dilakukan.
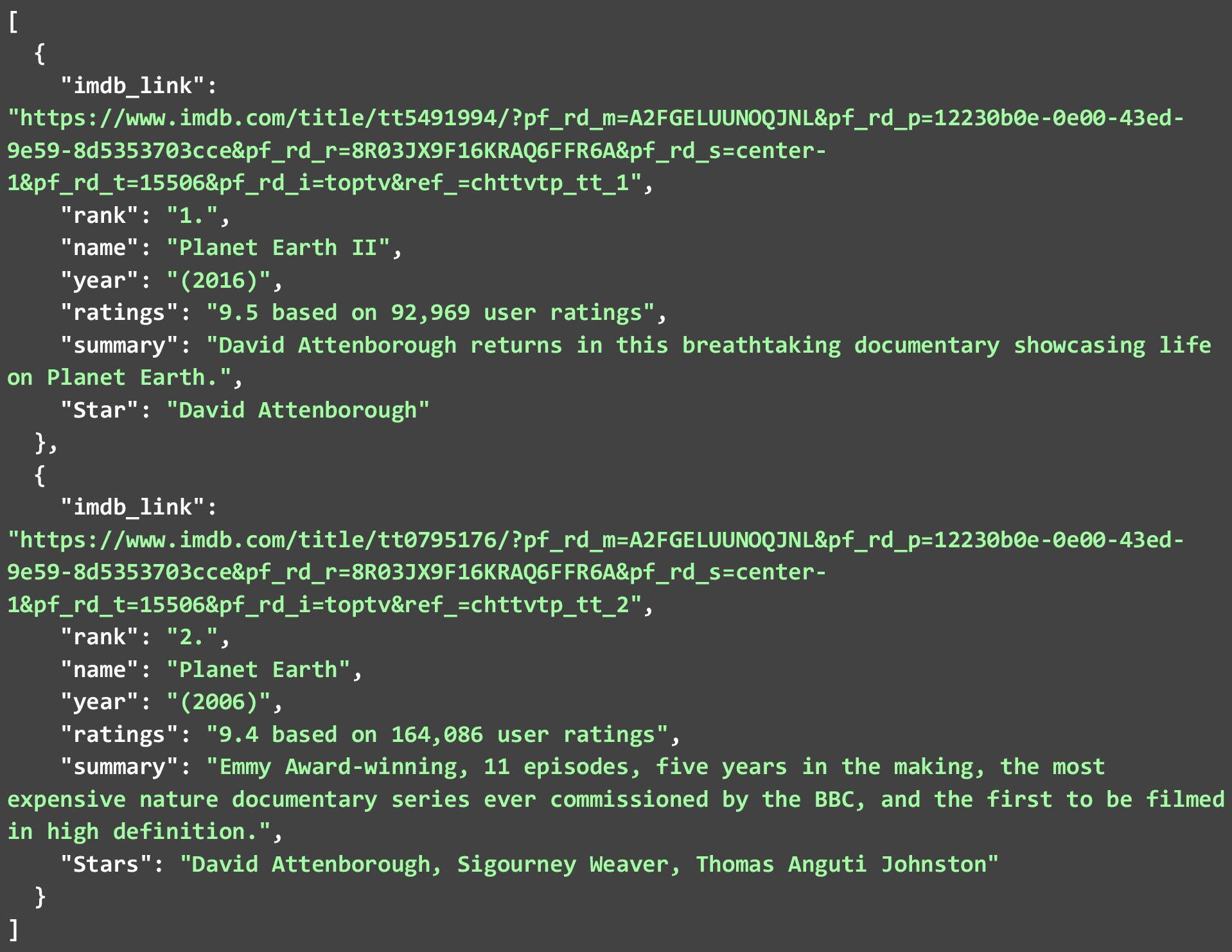
Sementara kami hanya mengekstrak 2 dari setiap daftar. Anda dapat mengizinkan kode berjalan untuk semua 250 acara atau film dan membuat file JSON yang besar. Anda bahkan dapat menyimpan data yang Anda ekstrak dalam database. Tetapi untuk menjalankan kode pada begitu banyak tautan. Anda harus mengikuti beberapa praktik terbaik dan mengingat beberapa kendala saat web menggores data IMDB.
Kendala dan Praktik Terbaik
Jika Anda menjalankan kode ini dan mengubah nilai "tidak" menjadi 250 dan menjalankan kode di semua 250 film dan acara tv. Ada kemungkinan besar bahwa situs web akan mendeteksi lalu lintas otomatis dari IP Anda dan Anda akhirnya akan diblokir. Anda perlu menggunakan alat seperti rotasi IP. Anda juga dapat membuat waktu tunggu beberapa detik antara menggores konten HTML dari setiap URL.
Adapun data yang Anda kikis, meski sebagian besar isinya dibuat oleh relawan. Mungkin ada batasan tertentu pada penggunaan komersial data. Anda harus mengikuti peraturan di mana pun Anda menggunakan data yang diambil dari halaman web yang berbeda. Beginilah cara web scraping data IMDB menggunakan Python.
Namun, jika Anda menginginkan pengalaman pengikisan web tanpa kerumitan di mana seseorang menangani data dan Anda dapat fokus pada model bisnis inti Anda, tim kami di PromptCloud siap melayani Anda. Kami bangga dengan solusi DaaS kami di mana kami menangani semuanya. Mulai dari menggores hingga mengakses data yang tergores.
Jika Anda menyukai konten di atas, kami yakin Anda juga ingin membaca ini . Silakan tinggalkan kami umpan balik Anda yang berharga di bagian komentar di bawah.