
最高の映画とショーのための Web スクレイピング IMDB
公開: 2020-12-08歴代のトップ 250 の映画を知りたいですか? それとも、これまでに小さなスクリーンでヒットした最高のコメディー番組ですか? 映画やショーの世界に関連するこのようなすべての回答、レビュー、評価、トリビアについて、世界中の人々がそのような情報のオンライン データベースである IMDB を使用しています。 情報はファンによって更新されますが、データベース自体は Amazon の子会社が所有および運営しています。 1990 年にデータベースとして作成され、1993 年に Web に移行しました。Web サイトの情報は誰でもアクセスできますが、事実の編集やレビューの追加を行う場合は、登録が必要です。 このブログでは、Python を使用して Web スクレイピング IMDB データがどのように行われるかを見ていきます。
映画と小さなスクリーン ショーの両方で更新されるさまざまなデータ ポイントに加えて、IMDB では、ユーザーが評価を追加することもできます。これらの評価は、映画ファンやその他の人がウォッチ リストを作成するために使用する複数のリストの基礎を形成しています。 IMDB はデータをクエリするための API を提供していませんが、データをテキスト形式でダウンロードできます。 DIY コードを使用してデータをスクレイピングすることもできます。
IMDB データの Web スクレイピングはどのように行われますか?
IMDBから2セットのデータをスクレイピングします
a)。 IMDB のトップ 250 の映画
b)。 IMDB のトップ 250 テレビ番組
これらのリストにある各映画または番組の特定のデータ ポイントをスクレイピングします。 一度にすべてのデータをスクレイピングしたくない場合があるため、上位 n 個の結果のみを抽出するために、パラメーターの値を変更するオプションを提供しています。
開始する前に、BeautifulSoup 依存関係とテキスト エディターと共に Python3.7 以降が必要です。 次に、python コマンド自体を使用して、以下のコードを実行できます。 コードで前述した 2 つのリストのリンクをハードコーディングしているため、ユーザー入力は必要ありません。
コードには、3 つの特定の関数があります。
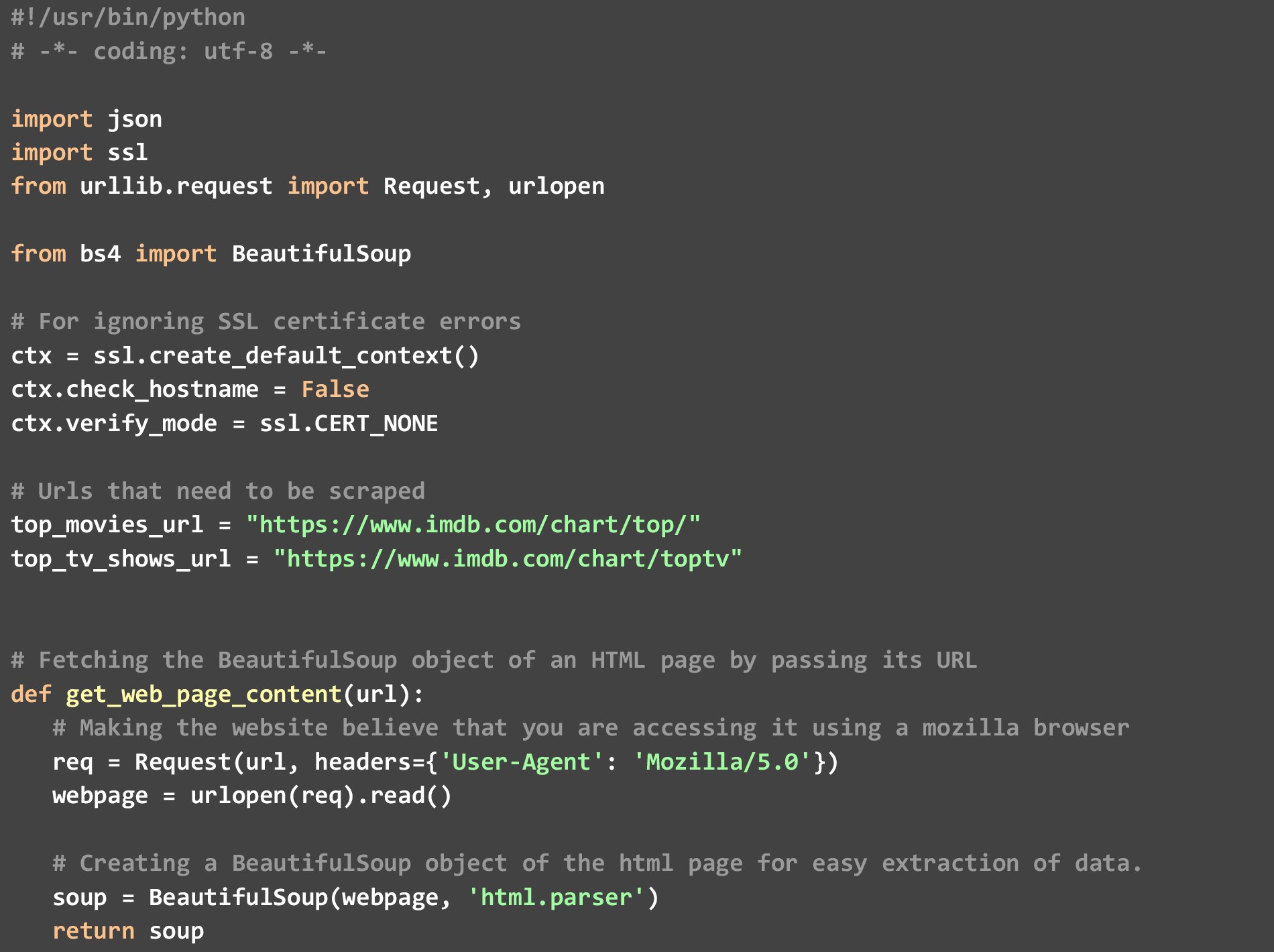
a)。 get_top_rated_imdb_hits - ここで実行が開始されます。 この関数への入力として、関係するリストの URL を渡します。 映画のリストの URL またはテレビ番組のリストの URL を指定できます。 結果の JSON が必要なファイルの名前と、必要な上位の結果の数も渡します。 Web ページ自体で利用可能な映画名や評価などの特定のデータ ポイントをフェッチし、映画/番組固有の URL をバイパスして get_extra_details 関数を呼び出して、追加のデータ ポイントをフェッチします。
b)。 get_web_page_content - この関数は、渡された URL の HTML コンテンツをフェッチし、簡単に解析できる BeautifulSoup オブジェクトに変換するために使用されます。 このオブジェクトは、この関数が返すものです。
c)。 get_extra_details - この関数は、get_top_rated_imdb_hits 関数によって渡された映画または番組固有の URL を使用して、概要、トップスターの名前、ランク付けリストの Web ページでは利用できない監督情報などの詳細を取得します。
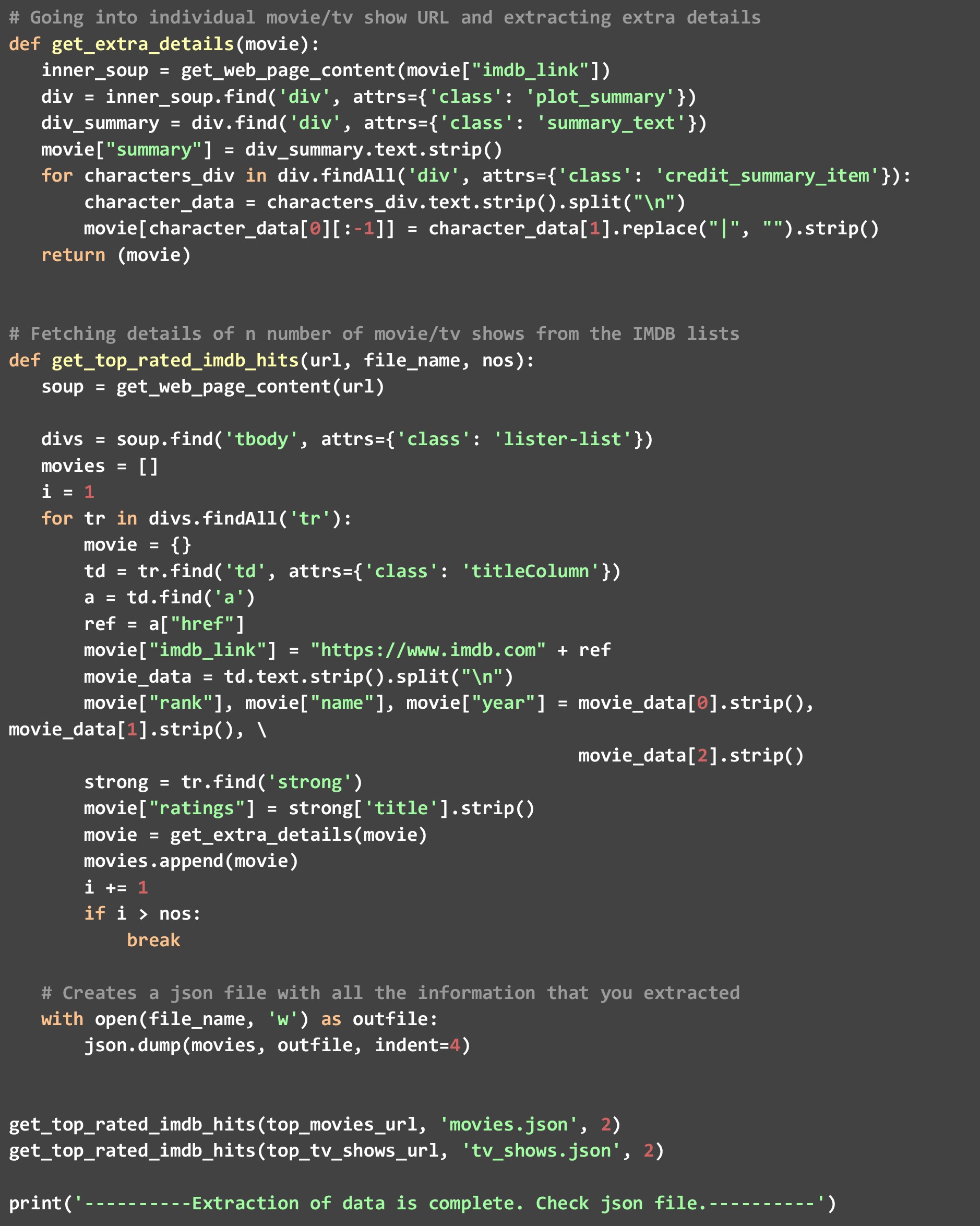
ご覧のとおり、関数 get_top_rated_imdb_hits を 2 回呼び出しました。1 回は映画の URL で、もう 1 回はテレビ番組の URL です。 また、両方のリストの上位 2 つの候補のデータのみが必要なため、カウントを 2 として渡しました。 このコードを実行すると、ディレクトリに「movies.json」と「tv_shows.json」という 2 つのファイルが作成されます。

抽出したデータ ポイント
映画やテレビ番組ごとに、これらのデータポイントを抽出しました。
a)。 特定の番組/映画の IMDB リンク
b)。 ランク
c)。 名前
d)。 年
e)。 評価
f)。 概要
g)。 監督
h)。 ライター
私)。 出演者
注意すべきことの 1 つは、各映画や番組ですべてのデータ ポイントが利用できるわけではありませんが、利用可能なものは破棄されるということです。 以下の JSON は、上記のコードを実行して取得した IMDB の上位 250 の映画リストの上位 2 つの映画を示しています。
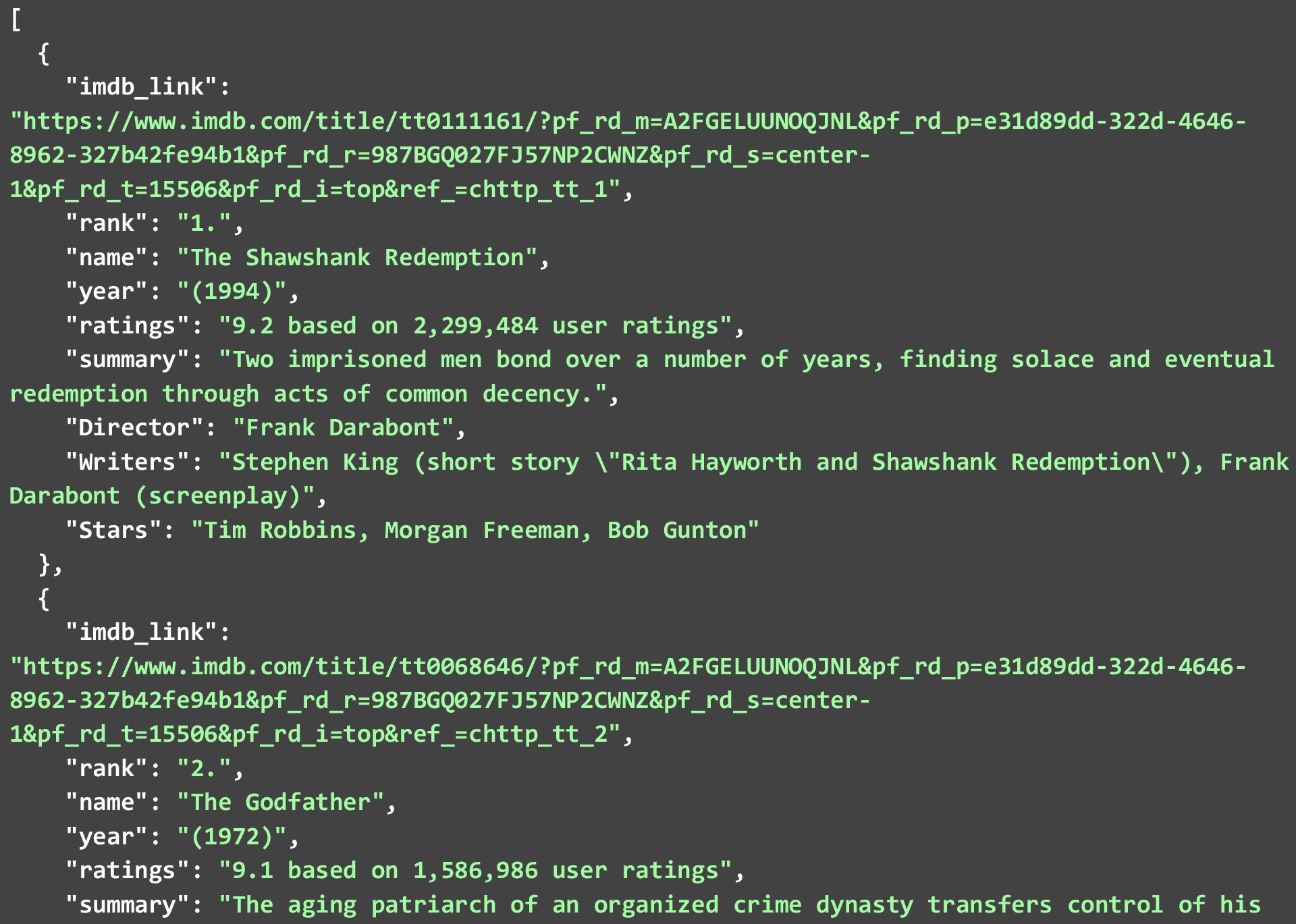

データをそのままスクレイピングし、データ自体に最小限の変更を加えました。 データをさらにクリーンアップして、データ ポイントをより使いやすくすることができます。 いくつかの例は
a)。 年号の括弧を外します。
b)。 評価を、評価と評価を送信した人の数という 2 つの個別のデータポイントに分割します。
以下の JSON は、2 番目の Web ページから抽出した上位 2 つのテレビ番組を示しています。 多くのそのようなWebスクレーパーが利用可能であるため. さまざまなテレビ番組の Web サイトから IMDB データをスクレイピングする方法を見てみましょう。 以下のコードは、それを行う方法の詳細な説明です。
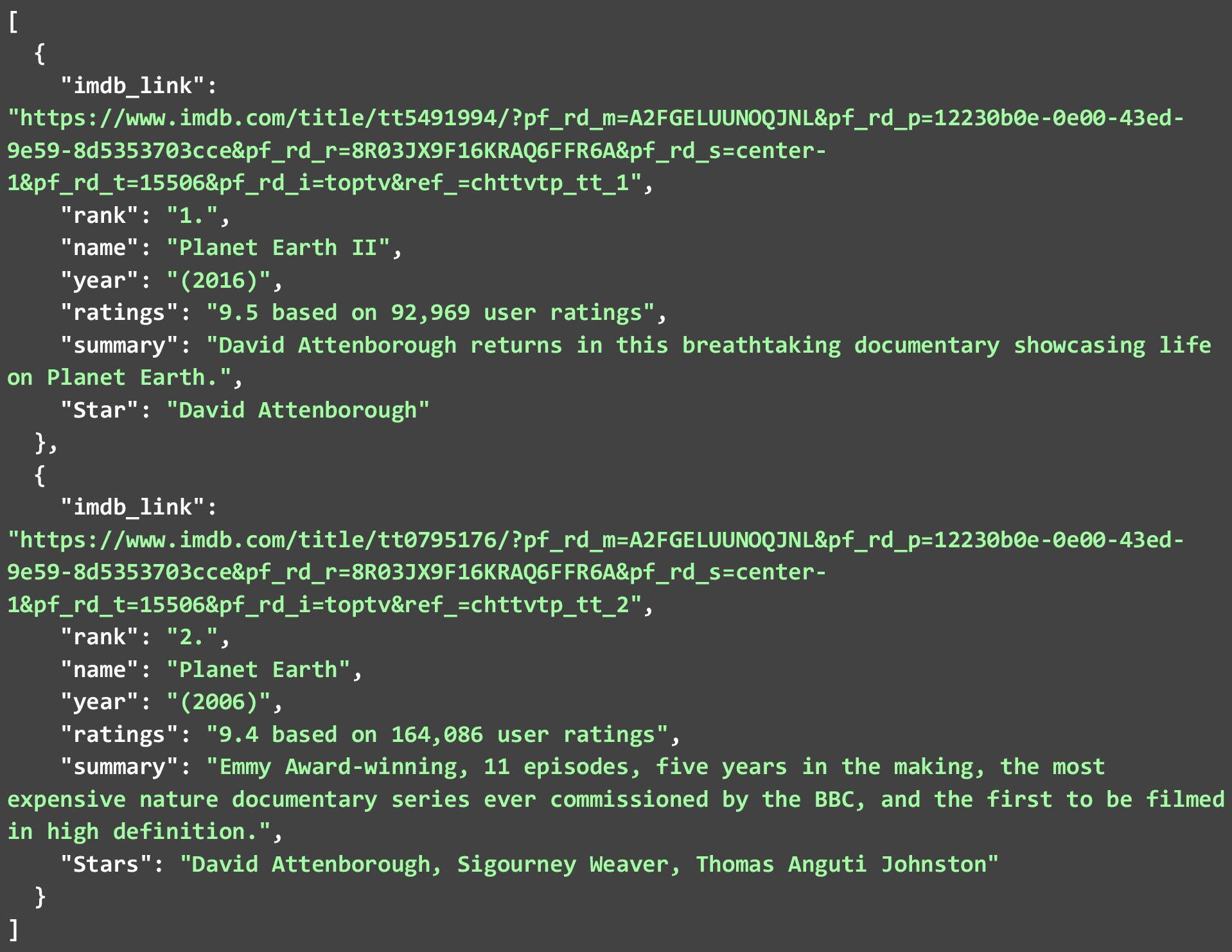
各リストから 2 つだけ抽出しましたが。 250 の番組または映画すべてに対してコードを実行できるようにし、大規模な JSON ファイルを作成できます。 抽出したデータをデータベースに保存することもできます。 しかし、非常に多くのリンクでコードを実行するためです。 Web で IMDB データをスクレイピングする際には、いくつかのベスト プラクティスに従い、いくつかの制約に留意する必要があります。
制約とベスト プラクティス
このコードを実行して、「nos」の値を 250 に変更し、250 の映画とテレビ番組すべてでコードを実行したとします。 Web サイトが IP からの自動トラフィックを検出し、ブロックされる可能性が高くなります。 IP ローテーションなどのツールを使用する必要があります。 各 URL の HTML コンテンツをスクレイピングする間に数秒の待機時間を作成することもできます。
スクレイピングするデータに関しては、そのコンテンツのほとんどがボランティアによって作成されたにもかかわらず. データの商用利用には特定の制限が適用される場合があります。 さまざまな Web ページからスクレイピングしたデータを使用する場合は、規制に従う必要があります。 これは、Python を使用して IMDB データを Web スクレイピングする方法です。
ただし、誰かがデータを処理し、コア ビジネス モデルに集中できる手間のかからない Web スクレイピング エクスペリエンスが必要な場合は、 PromptCloudのチームがお手伝いします。 私たちは、すべてを処理する DaaS ソリューションに誇りを持っています。 スクレイピングからスクレイピングされたデータへのアクセスまで。
上記の内容が気に入った場合は、こちらもお読みください。 以下のコメントセクションに貴重なフィードバックを残してください。