
Web Scraping IMDB dla najlepszych filmów i programów
Opublikowany: 2020-12-08Czy chciałbyś wiedzieć, jakie są 250 najlepszych filmów wszechczasów? A może najlepsze programy komediowe, jakie kiedykolwiek trafiły na małe ekrany? W przypadku wszystkich takich odpowiedzi, recenzji, ocen i ciekawostek związanych ze światem filmów i programów ludzie na całym świecie korzystają z IMDB, który jest internetową bazą takich informacji. Podczas gdy informacje są aktualizowane przez fanów, sama baza danych jest własnością i jest obsługiwana przez spółkę zależną Amazona. Została początkowo utworzona jako baza danych w 1990 roku i przeniesiona do sieci w 1993 roku. Chociaż każdy może uzyskać dostęp do informacji na stronie, rejestracja jest koniecznością, jeśli chcesz wprowadzać zmiany w faktach lub dodawać recenzje. W tym blogu przyjrzymy się, jak za pomocą Pythona wykonuje się web scraping danych IMDB.
Oprócz różnych punktów danych, które są aktualizowane zarówno dla filmów, jak i programów na małym ekranie, IMDB pozwala również użytkownikom dodawać oceny, a oceny te stanowią podstawę wielu list, które są używane przez miłośników filmów i innych do tworzenia ich list obserwacyjnych. Chociaż IMDB nie zapewnia interfejsu API do wysyłania zapytań do swoich danych, umożliwia pobieranie danych w formacie tekstowym. Możesz także zeskrobać dane za pomocą kodu DIY.
Jak odbywa się pozyskiwanie danych IMDB z Internetu?
Będziemy skrobać 2 zestawy danych z IMDB
a). 250 najlepszych filmów IMDB
b). 250 najlepszych programów telewizyjnych IMDB
Będziemy zbierać określone punkty danych dla każdego filmu lub programu z tych list. Możesz nie chcieć zeskrobać wszystkich danych naraz, dlatego udostępniliśmy opcję zmiany wartości parametru, aby wyodrębnić tylko n pierwszych wyników.
Zanim zaczniemy, będziesz potrzebować Python 3.7 lub nowszego wraz z zależnością BeautifulSoup i edytorem tekstu. Następnie możesz uruchomić poniższy kod za pomocą samego polecenia Pythona. Żadne dane wejściowe nie są wymagane, ponieważ zakodowaliśmy linki do dwóch list, o których wspomnieliśmy wcześniej w kodzie.
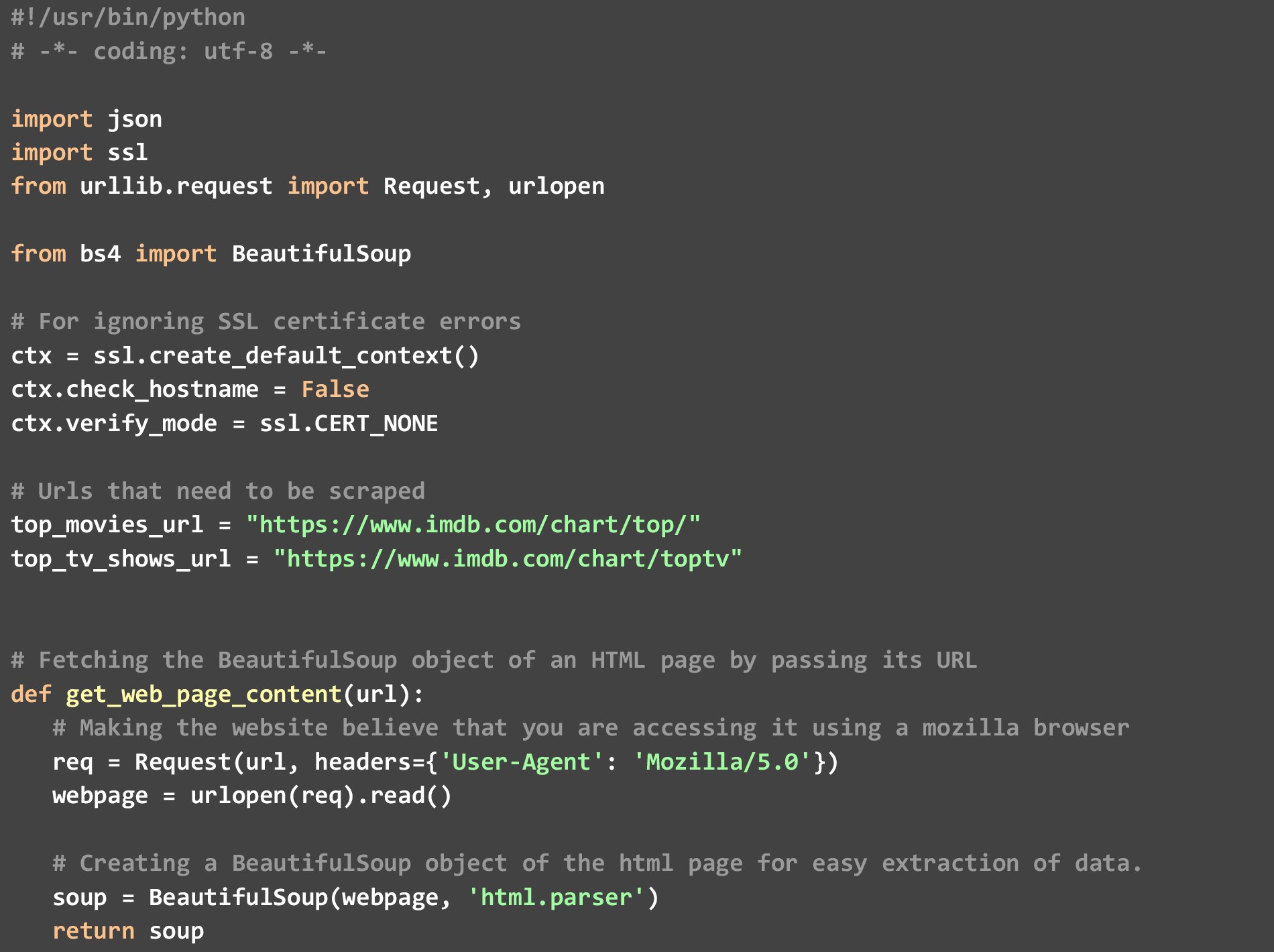
W kodzie mamy 3 specyficzne funkcje
a). get_top_rated_imdb_hits — W tym miejscu rozpoczyna się wykonanie. Jako dane wejściowe do tej funkcji przekazujemy adres URL odpowiedniej listy. Może to być adres URL listy filmów lub adres URL listy programów telewizyjnych. Przekazujemy również nazwę pliku, w którym chcemy uzyskać wynikowy JSON oraz liczbę najlepszych wyników, które chcemy. Pobieramy pewne punkty danych, takie jak nazwa filmu i oceny, które są dostępne na samej stronie internetowej, a następnie wywołujemy funkcję get_extra_details z pominięciem określonego adresu URL filmu/przedstawienia w celu pobrania dodatkowych punktów danych.
b). get_web_page_content — ta funkcja służy do pobierania zawartości HTML z przekazanego adresu URL i konwertowania jej na obiekt BeautifulSoup, który można łatwo przeanalizować. Ten obiekt jest tym, co zwraca ta funkcja.
c). get_extra_details — ta funkcja korzysta z adresu URL określonego filmu lub programu przekazanego do niej przez funkcję get_top_rated_imdb_hits, aby pobrać więcej szczegółów, takich jak podsumowanie, nazwa największych gwiazd i informacje o reżyserze niedostępne na stronie z listą rankingową.
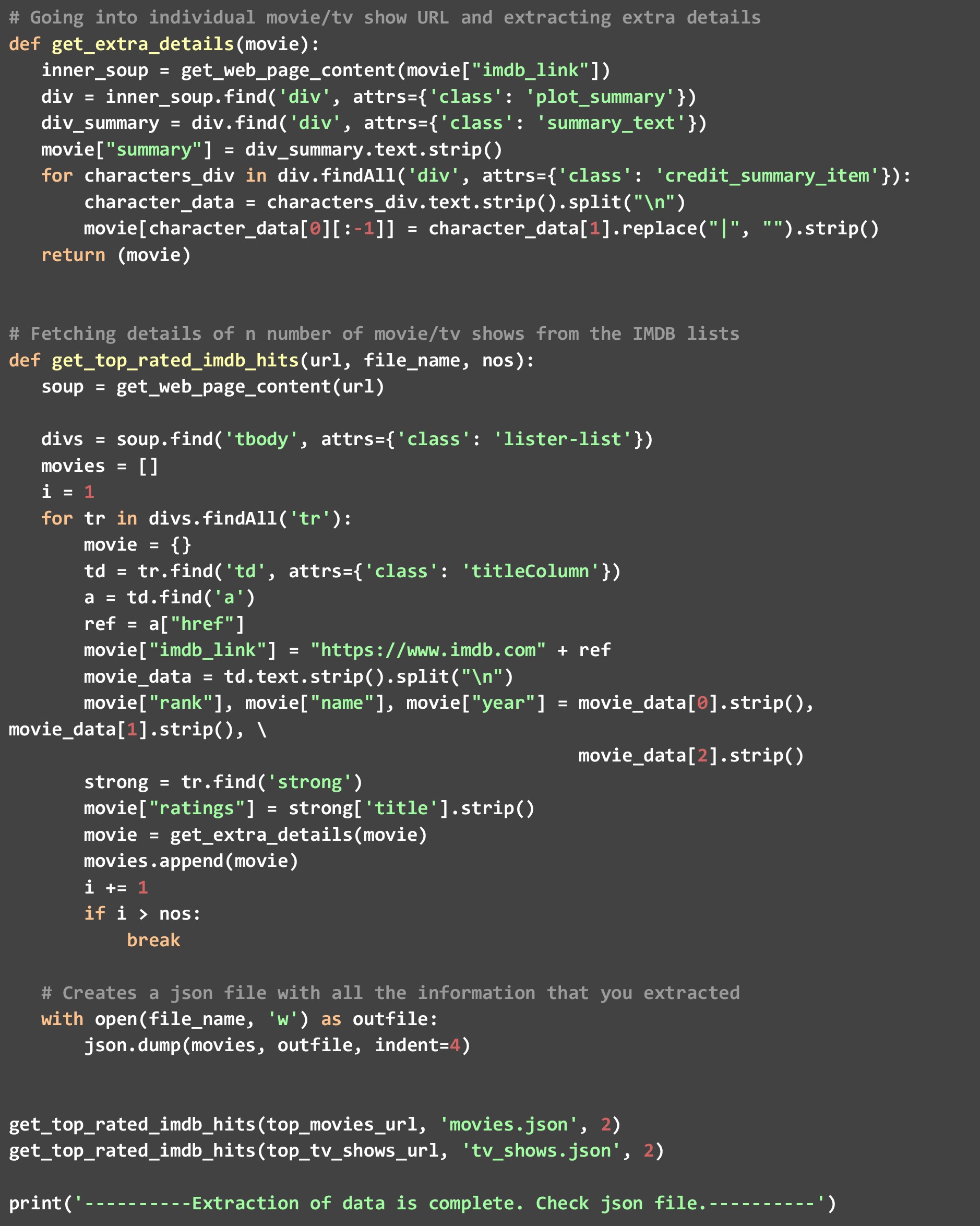

Jak widać, dwukrotnie wywołaliśmy funkcję get_top_rated_imdb_hits, raz z adresem URL filmów i raz z adresem URL programów telewizyjnych. Przekazaliśmy również liczbę jako 2, ponieważ chcemy, aby dane dotyczyły tylko dwóch najlepszych kandydatów z obu list. Po uruchomieniu tego kodu zobaczysz dwa pliki utworzone w twoim katalogu - "movies.json" i "tv_shows.json".
Punkty danych, które wyodrębniliśmy
Dla każdego filmu lub programu telewizyjnego wyodrębniliśmy te punkty danych.
a). Link IMDB do konkretnego programu/filmu
b). Ranga
c). Nazwa
d). Rok
mi). Oceny
f). Streszczenie
g). Dyrektor
h). Pisarze
i). Gwiazdy
Należy zauważyć, że nie wszystkie punkty danych mogą być dostępne dla każdego filmu lub programu, ale to, co jest dostępne, zostanie usunięte. Poniższy JSON pokazuje 2 najlepsze filmy na liście 250 najlepszych filmów w IMDB, które uzyskaliśmy po uruchomieniu powyższego kodu.
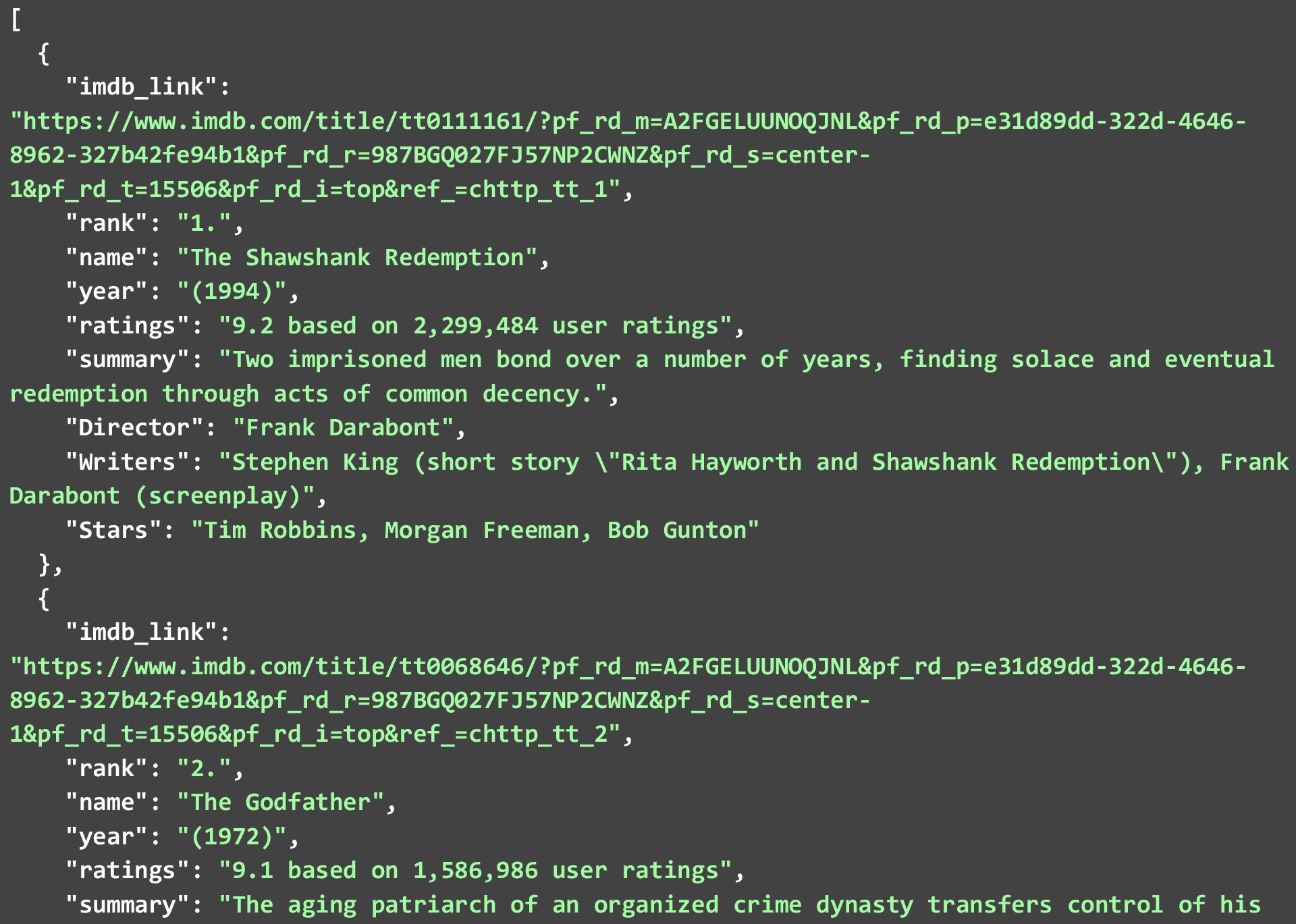

Chociaż zeskrobaliśmy dane tak, jak były i wprowadziliśmy minimalne zmiany w samych danych. Możesz dalej czyścić dane, aby punkty danych były bardziej użyteczne. Kilka przykładów to
a). Zdejmowanie wsporników na rok.
b). Podział ocen na 2 oddzielne punkty danych, oceny i liczbę osób, które przesłały swoje oceny.
Poniższy JSON pokazuje 2 najlepsze programy telewizyjne, które wyodrębniliśmy z drugiej strony internetowej. Ponieważ dostępnych jest wiele takich skrobaków internetowych. Przyjrzyjmy się, w jaki sposób możemy pobrać dane IMDB z ich witryny internetowej dla różnych programów telewizyjnych . Poniższy kod jest szczegółowym wyjaśnieniem, jak można to zrobić.
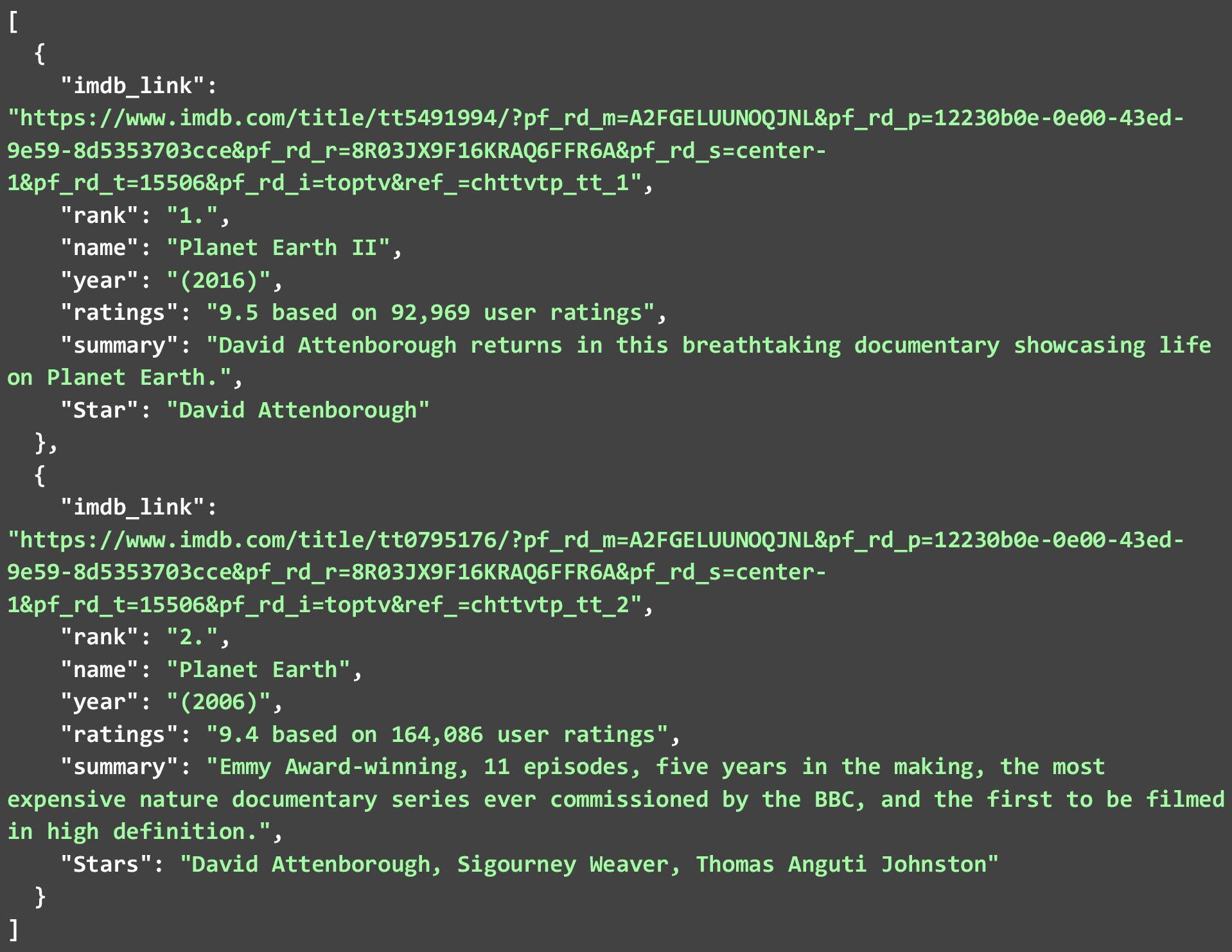
Chociaż wyodrębniliśmy tylko 2 z każdej listy. Możesz zezwolić na uruchomienie kodu dla wszystkich 250 programów lub filmów i utworzyć ogromny plik JSON. Możesz nawet przechowywać dane, które wyodrębnisz w bazie danych. Ale za uruchamianie kodu na tak wielu linkach. Będziesz musiał postępować zgodnie z najlepszymi praktykami i pamiętać o pewnych ograniczeniach podczas pobierania danych IMDB z sieci.
Ograniczenia i najlepsze praktyki
W przypadku, gdy uruchomiłeś ten kod i zmieniłeś wartość „nos” na 250 i uruchomiłeś kod we wszystkich 250 filmach i programach telewizyjnych. Istnieje duża szansa, że witryna wykryje zautomatyzowany ruch z Twojego adresu IP i zostaniesz zablokowany. Będziesz musiał użyć narzędzi takich jak rotacja adresów IP. Możesz także utworzyć kilkusekundowy czas oczekiwania między zeskrobaniem zawartości HTML każdego adresu URL.
Jeśli chodzi o dane, które zbierasz, mimo że większość ich treści jest tworzona przez wolontariuszy. Mogą istnieć pewne ograniczenia komercyjnego wykorzystania danych. Musisz przestrzegać przepisów wszędzie tam, gdzie korzystasz z danych pobranych z różnych stron internetowych. W ten sposób web scraping danych IMDB za pomocą Pythona.
Jeśli jednak chcesz bezproblemowego korzystania z web scrapingu, w którym ktoś zajmie się danymi, a Ty możesz skupić się na swoim podstawowym modelu biznesowym, nasz zespół w PromptCloud jest do Twojej dyspozycji. Jesteśmy dumni z naszego rozwiązania DaaS, w którym dbamy o wszystko. Od skrobania po dostęp do zeskrobanych danych.
Jeśli podobała Ci się powyższa treść, jesteśmy pewni, że również zechcesz ją przeczytać . Zostaw nam swoją cenną opinię w sekcji komentarzy poniżej.