
Веб-скрейпинг IMDB для лучших фильмов и шоу
Опубликовано: 2020-12-08Хотите знать, какие фильмы вошли в топ-250 всех времен? Или лучшие комедийные шоу, которые когда-либо выходили на маленькие экраны? Для всех таких ответов, обзоров, рейтингов и мелочей, связанных с миром фильмов и шоу, люди во всем мире используют IMDB, который представляет собой онлайн-базу данных такой информации. Хотя информация обновляется фанатами, сама база данных принадлежит и управляется дочерней компанией Amazon. Первоначально он был создан как база данных в 1990 году и перемещен в Интернет в 1993 году. Хотя любой может получить доступ к информации на веб-сайте, регистрация является обязательной, если вы хотите внести изменения в факты или добавить обзоры. В этом блоге мы рассмотрим, как выполняется парсинг данных IMDB с помощью Python.
В дополнение к различным точкам данных, которые обновляются как для фильмов, так и для небольших экранов, IMDB также позволяет своим пользователям добавлять рейтинги, и эти рейтинги легли в основу нескольких списков, которые используются любителями кино и другими людьми для создания своих списков наблюдения. Хотя IMDB не предоставляет API для запроса своих данных, он позволяет загружать данные в текстовом формате. Вы также можете очистить данные, используя код DIY.
Как выполняется парсинг данных IMDB?
Мы будем собирать 2 набора данных с IMDB.
а). 250 лучших фильмов по версии IMDB
б). 250 лучших телешоу по версии IMDB
Мы будем очищать определенные точки данных для каждого фильма или шоу в этих списках. Возможно, вам не захочется очищать все данные сразу, поэтому мы предоставили возможность изменить значение параметра, чтобы извлечь только первые n результатов.
Прежде чем мы начнем, вам потребуется Python 3.7 или выше, а также зависимость BeautifulSoup и текстовый редактор. Затем вы можете запустить приведенный ниже код, используя саму команду python. Пользовательский ввод не требуется, так как мы жестко закодировали ссылки двух списков, которые мы упоминали ранее в коде.
В коде у нас есть 3 конкретные функции
а). get_top_rated_imdb_hits — здесь начинается выполнение. В качестве входных данных для этой функции мы передаем URL-адрес соответствующего списка. Это может быть URL-адрес списка фильмов или URL-адрес списка телешоу. Мы также передаем имя файла, в котором мы хотим получить результат JSON, и количество лучших результатов, которые мы хотим. Мы извлекаем определенные точки данных, такие как название фильма и рейтинги, которые доступны на самой веб-странице, а затем вызываем функцию get_extra_details, минуя конкретный URL-адрес фильма/шоу, для получения дополнительных точек данных.
б). get_web_page_content — эта функция используется для извлечения HTML-содержимого переданного ей URL-адреса и преобразования его в объект BeautifulSoup, который можно легко проанализировать. Этот объект и есть то, что возвращает эта функция.
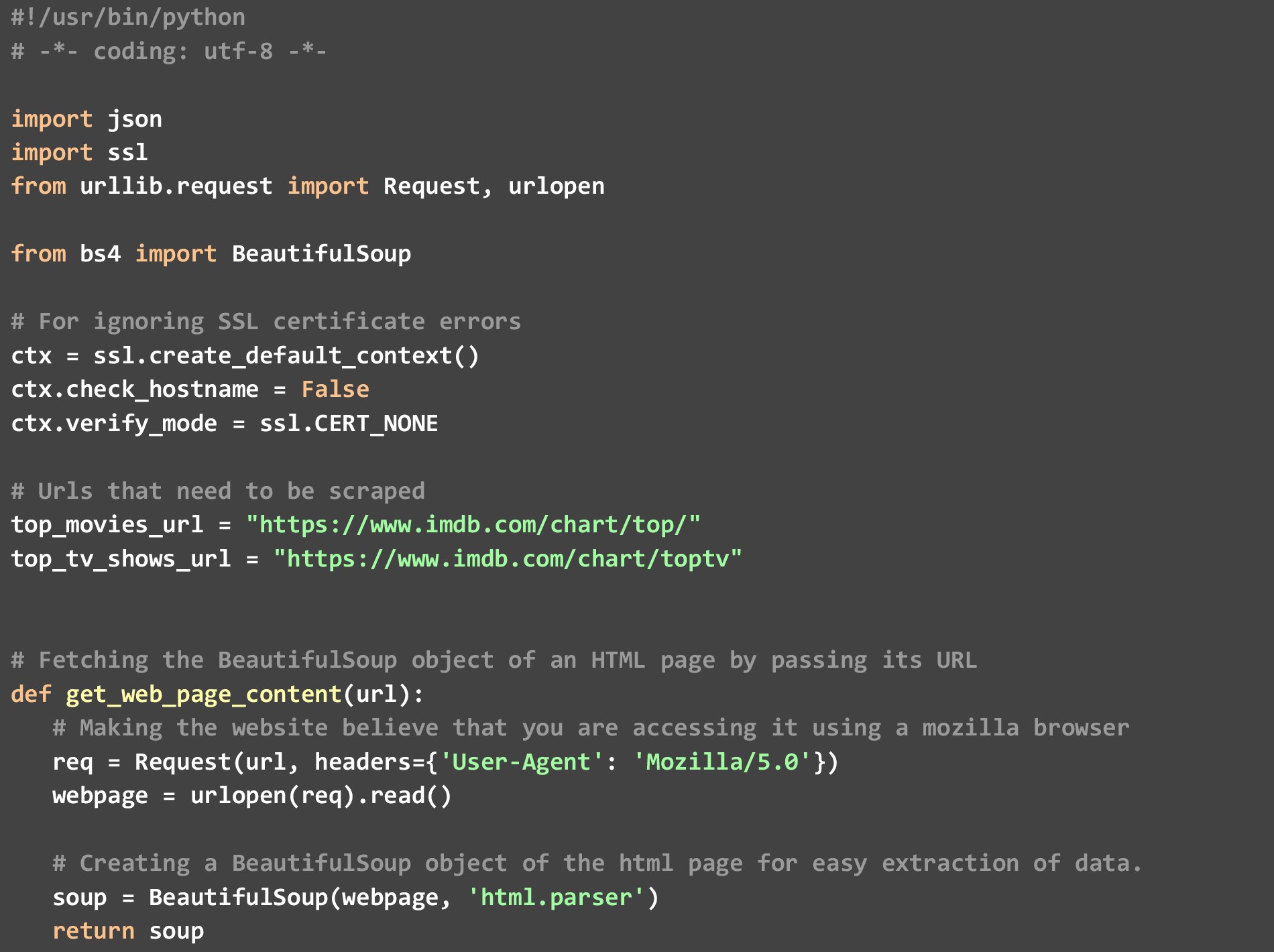
в). get_extra_details — эта функция использует URL-адрес фильма или шоу, переданный ей функцией get_top_rated_imdb_hits, для получения более подробной информации, такой как сводка, имя главных звезд и информация о режиссере, недоступная на веб-странице ранжированного списка.
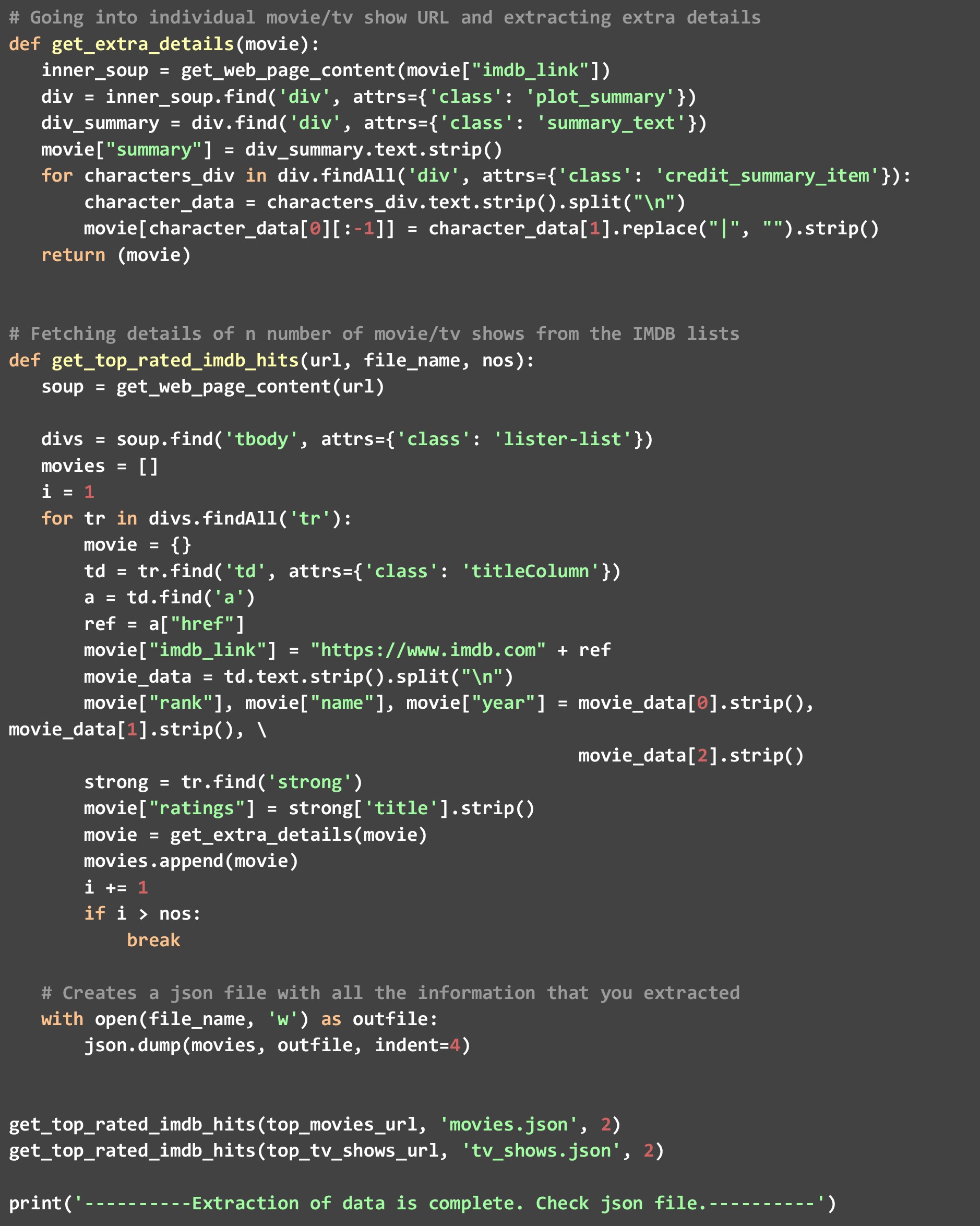

Как видите, мы дважды вызывали функцию get_top_rated_imdb_hits, один раз с URL-адресом фильма и один раз с URL-адресом телешоу. Мы также передали счетчик как 2, так как нам нужны данные только для двух лучших кандидатов в обоих списках. После запуска этого кода вы увидите два файла, созданных в вашем каталоге — «movies.json» и «tv_shows.json».
Точки данных, которые мы извлекли
Для каждого фильма или телешоу мы извлекли эти точки данных.
а). Ссылка на IMDB для конкретного шоу/фильма
б). Классифицировать
в). Имя
г). Год
д). Рейтинги
е). Резюме
грамм). Директор
час). Писатели
я). Звезды
Следует отметить, что не все точки данных могут быть доступны для каждого фильма или шоу, но те, которые доступны, будут удалены. В приведенном ниже JSON показаны 2 лучших фильма из списка 250 лучших фильмов на IMDB, который мы получили при выполнении приведенного выше кода.
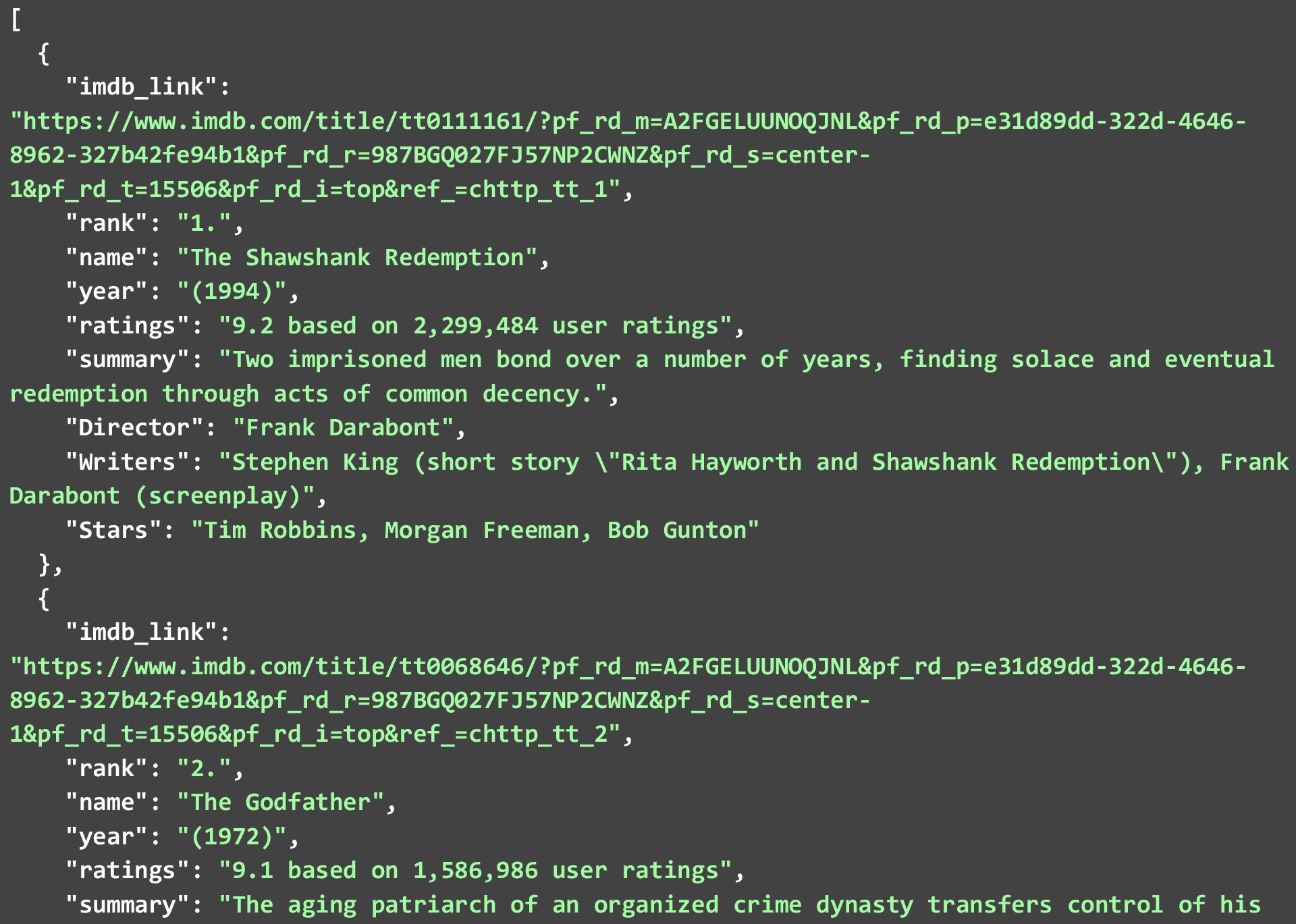

Пока мы парсили данные как были и вносили минимальные изменения в сами данные. Вы можете дополнительно очистить данные, чтобы сделать точки данных более удобными для использования. Несколько примеров будут
а). Снятие скобок с года.
б). Разделение рейтингов на 2 отдельные точки данных: рейтинги и количество людей, представивших свои рейтинги.
В приведенном ниже JSON показаны 2 лучших телешоу, которые мы извлекли со второй веб-страницы. Поскольку существует множество таких веб-скребков. Давайте посмотрим, как мы можем собрать данные IMDB с их веб-сайта для различных телешоу . Приведенный ниже код представляет собой подробное объяснение того, как это можно сделать.
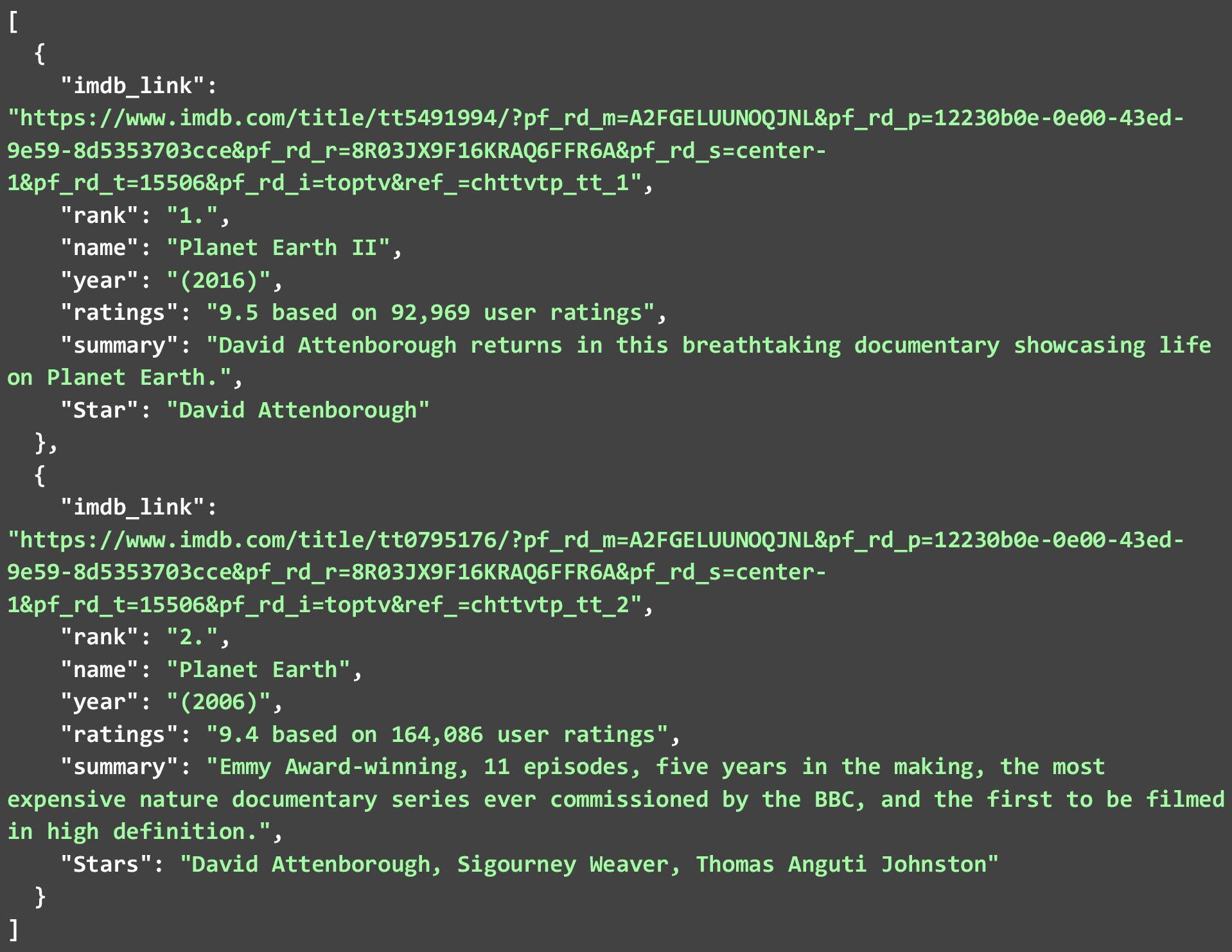
Пока мы извлекли только 2 из каждого списка. Вы можете разрешить запуск кода для всех 250 шоу или фильмов и создать массивный файл JSON. Вы даже можете хранить данные, которые вы извлекаете в базе данных. Но для запуска кода на таком количестве ссылок. Вам нужно будет следовать некоторым рекомендациям и помнить о некоторых ограничениях при очистке данных IMDB.
Ограничения и рекомендации
В случае, если вы запустили этот код и изменили значение «nos» на 250 и запустили код для всех 250 фильмов и телешоу. Существует высокая вероятность того, что веб-сайт обнаружит автоматический трафик с вашего IP-адреса, и в конечном итоге вы будете заблокированы. Вам нужно будет использовать такие инструменты, как ротация IP. Вы также можете установить время ожидания в несколько секунд между очисткой HTML-содержимого каждого URL-адреса.
Что касается данных, которые вы парсите, даже несмотря на то, что большая часть их контента создана добровольцами. Могут быть определенные ограничения на коммерческое использование данных. Вы должны соблюдать правила везде, где вы используете данные, полученные с разных веб-страниц. Вот как веб-скрапинг данных IMDB с помощью Python.
Однако, если вам нужен беспроблемный опыт парсинга веб-страниц, когда кто-то позаботится о данных, а вы можете сосредоточиться на своей основной бизнес-модели, наша команда PromptCloud к вашим услугам. Мы гордимся нашим решением DaaS, в котором мы позаботимся обо всем. Прямо от очистки до доступа к очищенным данным.
Если вам понравился контент выше, мы уверены, что вы хотели бы прочитать и это . Пожалуйста, оставьте нам свой ценный отзыв в разделе комментариев ниже.