
최고의 영화 및 쇼를 위한 웹 스크래핑 IMDB
게시 됨: 2020-12-08역대 최고의 영화 250편이 무엇인지 알고 싶습니까? 아니면 지금까지 작은 스크린을 강타한 최고의 코미디 쇼? 영화와 쇼의 세계와 관련된 이러한 모든 답변, 리뷰, 평가 및 퀴즈에 대해 전 세계 사람들은 이러한 정보의 온라인 데이터베이스인 IMDB를 사용합니다. 정보는 팬에 의해 업데이트되지만 데이터베이스 자체는 Amazon의 자회사가 소유하고 운영합니다. 1990년에 데이터베이스로 처음 만들어졌고 1993년에 웹으로 옮겨졌습니다. 웹사이트의 정보는 누구나 액세스할 수 있지만 사실을 수정하거나 리뷰를 추가하려면 등록이 필수입니다. 이 블로그에서는 Python을 사용하여 IMDB 데이터를 웹 스크래핑하는 방법을 살펴봅니다.
영화와 작은 스크린 쇼 모두에 대해 업데이트되는 다양한 데이터 포인트 외에도 IMDB는 사용자가 등급을 추가할 수 있도록 허용하며 이러한 등급은 영화 애호가 및 기타 사람들이 시청 목록을 만드는 데 사용하는 여러 목록의 기초를 형성했습니다. IMDB는 데이터를 쿼리하는 API를 제공하지 않지만 텍스트 형식으로 데이터를 다운로드할 수 있습니다. DIY 코드를 사용하여 데이터를 스크랩할 수도 있습니다.
IMDB 데이터의 웹 스크래핑은 어떻게 이루어집니까?
IMDB에서 2세트의 데이터를 스크랩할 것입니다.
ㅏ). IMDB 상위 250개 영화
비). IMDB 상위 250개 TV 프로그램
우리는 이 목록에 있는 각 영화 또는 프로그램에 대한 특정 데이터 포인트를 스크랩할 것입니다. 한 번에 모든 데이터를 스크랩하고 싶지 않을 수 있으므로 상위 n개 결과만 추출하도록 매개변수 값을 변경하는 옵션을 제공했습니다.
시작하기 전에 BeautifulSoup 종속성과 텍스트 편집기와 함께 Python3.7 이상이 필요합니다. 그런 다음 python 명령 자체를 사용하여 아래에 제공된 코드를 실행할 수 있습니다. 앞서 코드에서 언급한 두 목록의 링크를 하드코딩했기 때문에 사용자 입력이 필요하지 않습니다.
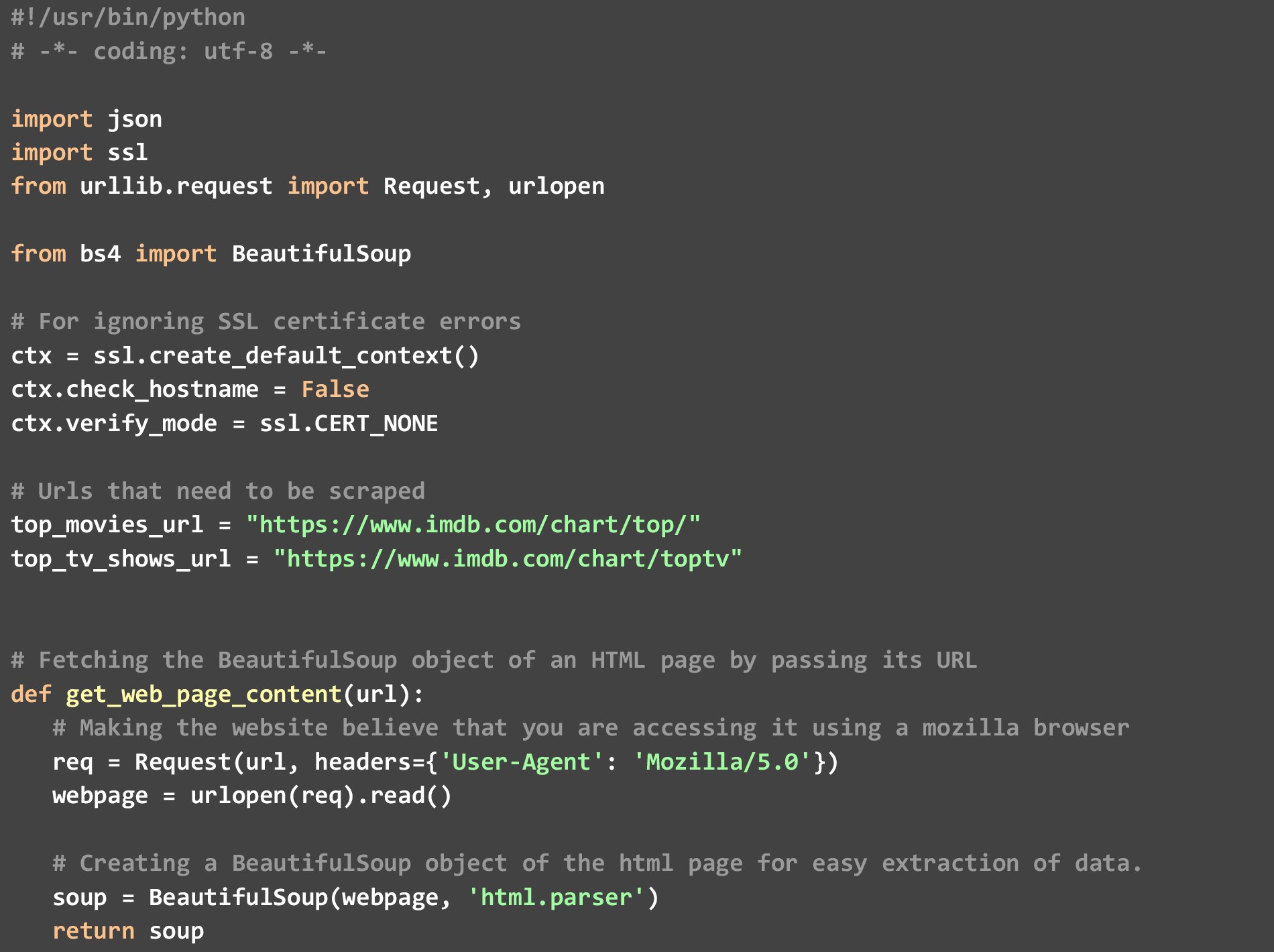
코드에는 3가지 특정 기능이 있습니다.
ㅏ). get_top_rated_imdb_hits- 실행이 시작되는 곳입니다. 이 함수에 대한 입력으로 관련 목록의 URL을 전달합니다. 영화 목록 URL 또는 TV 프로그램 목록 URL일 수 있습니다. 또한 결과 JSON을 원하는 파일의 이름과 원하는 상위 결과의 수를 전달합니다. 웹 페이지 자체에서 사용할 수 있는 영화 이름 및 등급과 같은 특정 데이터 요소를 가져온 다음 추가 데이터 요소를 가져오기 위해 영화/쇼 특정 URL을 우회하는 get_extra_details 함수를 호출합니다.
비). get_web_page_content- 이 함수는 전달된 URL의 HTML 콘텐츠를 가져와 쉽게 구문 분석할 수 있는 BeautifulSoup 개체로 변환하는 데 사용됩니다. 이 객체는 이 함수가 반환하는 것입니다.
씨). get_extra_details- 이 함수는 get_top_rated_imdb_hits 함수에 의해 전달된 영화 또는 쇼 특정 URL을 사용하여 랭킹 목록 웹페이지에서 볼 수 없는 요약, 최고 스타의 이름 및 감독 정보와 같은 자세한 정보를 가져옵니다.
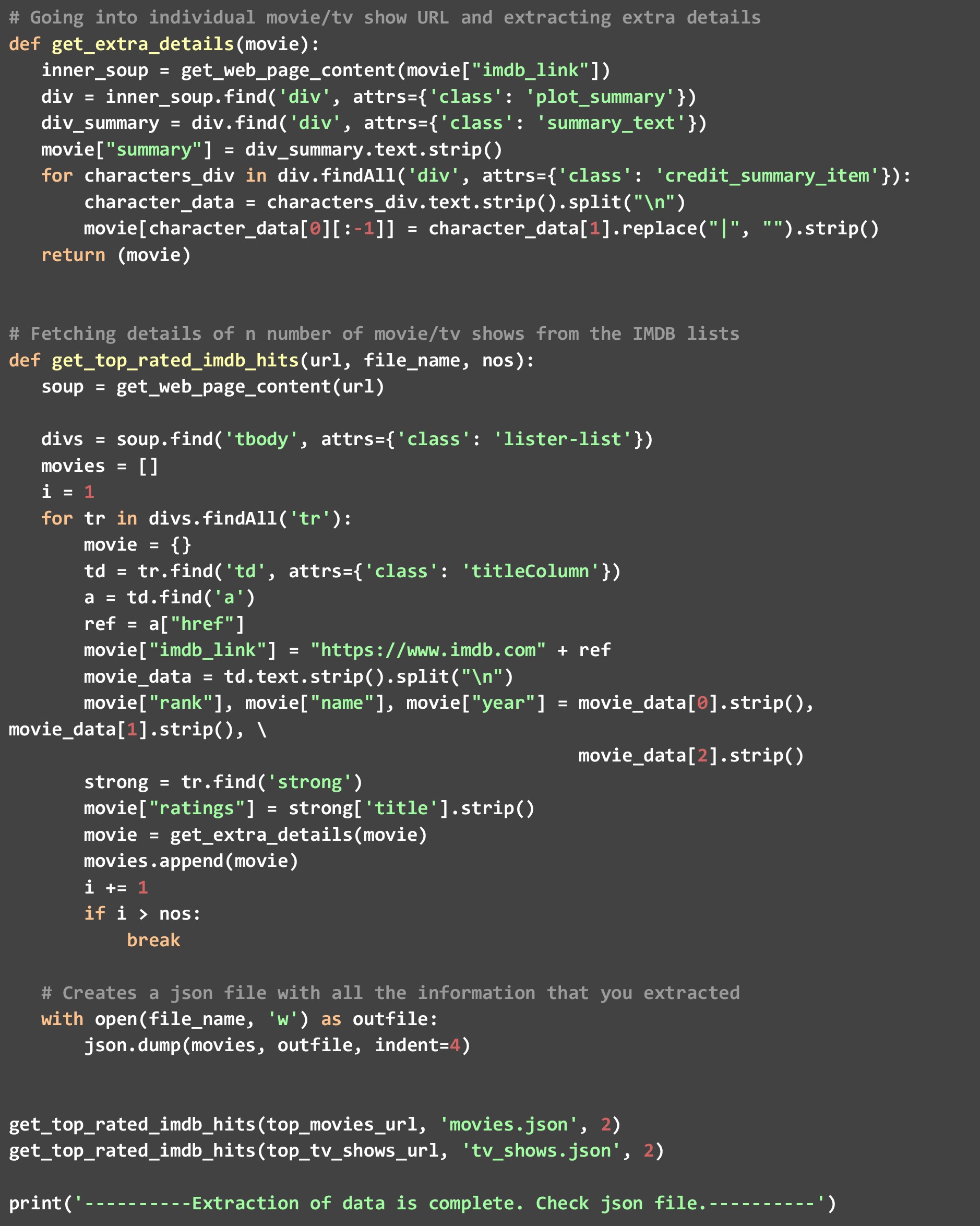
보시다시피 get_top_rated_imdb_hits 함수를 두 번 호출했습니다. 한 번은 영화 URL로, 한 번은 TV 프로그램 URL로 호출했습니다. 또한 두 목록의 상위 두 후보에 대한 데이터만 원하기 때문에 개수를 2로 전달했습니다. 이 코드가 실행되면 디렉토리에 "movies.json" 및 "tv_shows.json"이라는 두 개의 파일이 생성된 것을 볼 수 있습니다.

우리가 추출한 데이터 포인트
각 영화 또는 TV 프로그램에 대해 이러한 데이터 포인트를 추출했습니다.
ㅏ). 특정 쇼/영화에 대한 IMDB 링크
비). 계급
씨). 이름
디). 년도
이자형). 등급
에프). 요약
g). 감독
시간). 작가
나). 별
한 가지 유의할 점은 각 영화 또는 프로그램에 대해 모든 데이터 포인트를 사용할 수 있는 것은 아니지만 사용 가능한 데이터 포인트는 스크랩된다는 것입니다. 아래 JSON은 위의 코드를 실행하여 얻은 IMDB의 상위 250개 영화 목록에서 상위 2개 영화를 보여줍니다.
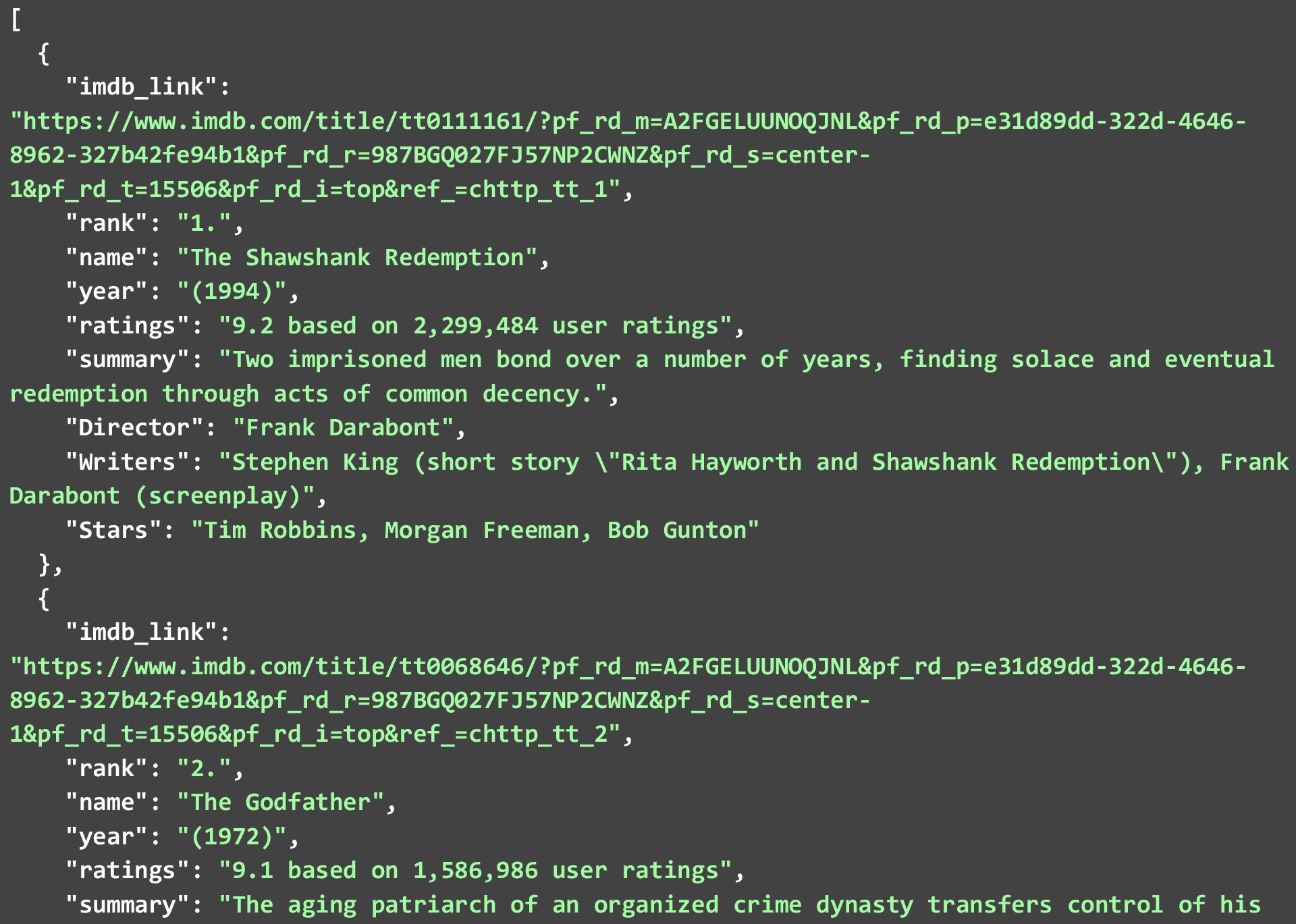

데이터를 있는 그대로 스크랩하고 데이터 자체를 최소한으로 변경했습니다. 데이터 포인트를 더 유용하게 만들기 위해 데이터를 더 정리할 수 있습니다. 몇 가지 예는 다음과 같습니다.
ㅏ). 연도에 브래킷을 제거합니다.
비). 등급을 2개의 개별 데이터 포인트, 등급 및 등급을 제출한 사람 수로 나눕니다.
아래 JSON은 두 번째 웹 페이지에서 추출한 상위 2개의 TV 쇼를 보여줍니다. 그러한 웹 스크레이퍼가 많이 있기 때문입니다. 다른 TV 프로그램에 대해 웹사이트에서 IMDB 데이터를 스크랩 하는 방법을 살펴보겠습니다. 아래 코드는 수행 방법에 대한 자세한 설명입니다.
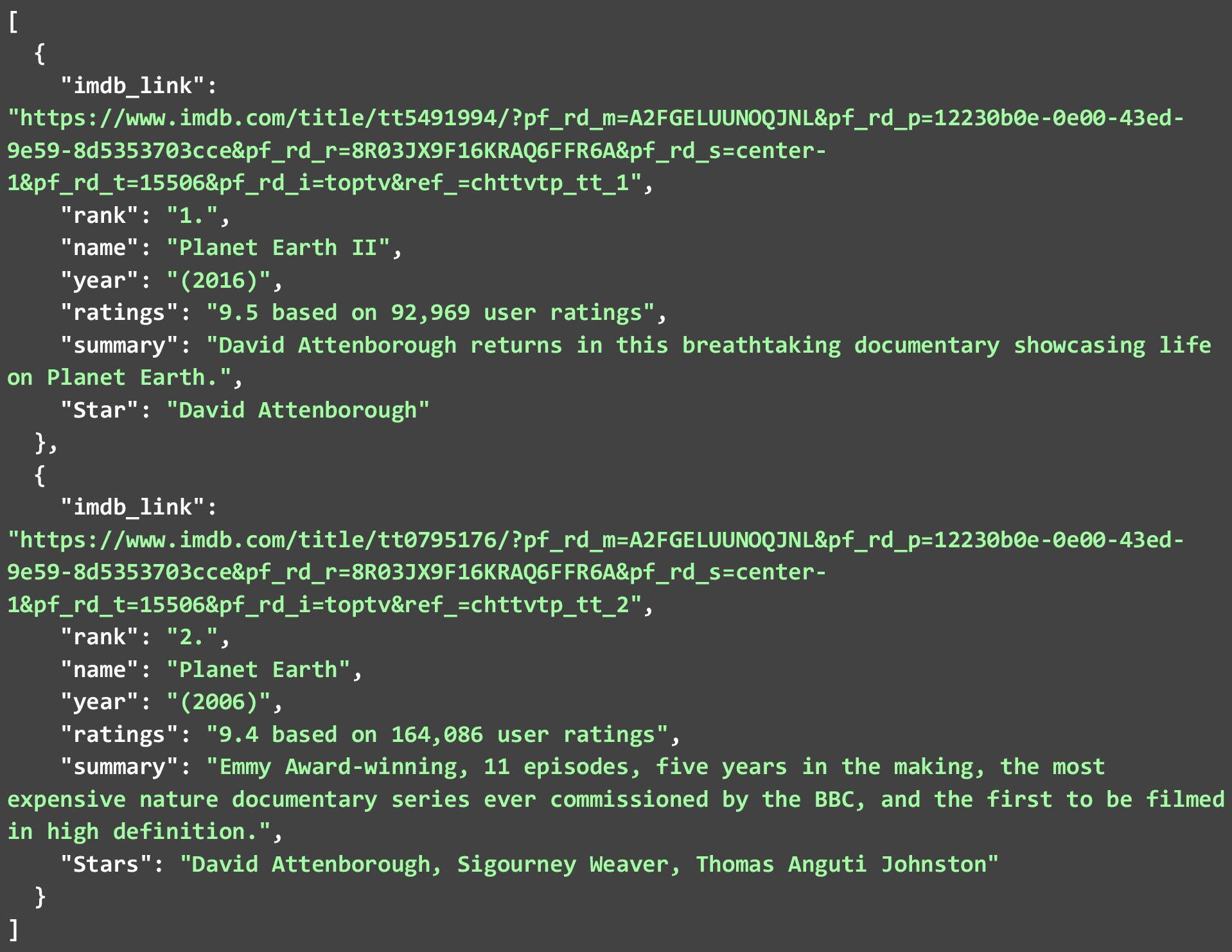
각 목록에서 2개만 추출했습니다. 250개의 모든 쇼 또는 영화에 대해 코드를 실행하고 방대한 JSON 파일을 생성할 수 있습니다. 추출한 데이터를 데이터베이스에 저장할 수도 있습니다. 그러나 너무 많은 링크에서 코드를 실행하기 위해. IMDB 데이터를 웹 스크래핑하는 동안 몇 가지 모범 사례를 따르고 몇 가지 제약 조건을 염두에 두어야 합니다.
제약 조건 및 모범 사례
이 코드를 실행하고 "nos" 값을 250으로 변경하고 250개의 모든 영화 및 TV 프로그램에서 코드를 실행한 경우. 웹 사이트가 귀하의 IP에서 자동 트래픽을 감지하여 결국 차단될 가능성이 높습니다. IP 순환과 같은 도구를 사용해야 합니다. 각 URL의 HTML 콘텐츠를 스크랩하는 사이에 몇 초의 대기 시간을 만들 수도 있습니다.
당신이 긁는 데이터에 관해서는, 그 콘텐츠의 대부분이 자원 봉사자에 의해 만들어 졌음에도 불구하고. 데이터의 상업적 사용에 특정 제한이 있을 수 있습니다. 다른 웹 페이지에서 스크랩한 데이터를 사용하는 곳마다 규정을 따라야 합니다. 이것이 Python을 사용하여 IMDB 데이터를 웹 스크래핑하는 방법입니다.
그러나 누군가가 데이터를 관리하고 핵심 비즈니스 모델에 집중할 수 있는 번거롭지 않은 웹 스크래핑 경험을 원한다면 PromptCloud 팀이 도와 드립니다. 우리는 모든 것을 처리하는 DaaS 솔루션에 자부심을 느낍니다. 스크랩부터 스크랩한 데이터 액세스까지.
위의 내용이 마음에 드셨다면 이 내용도 꼭 읽어보시기 바랍니다 . 아래 댓글 섹션에 소중한 피드백을 남겨주세요.