
Web Scraping IMDB per i migliori film e spettacoli
Pubblicato: 2020-12-08Vuoi sapere quali sono i 250 migliori film di tutti i tempi? O i migliori spettacoli comici che siano mai arrivati sui piccoli schermi? Per tutte queste risposte, recensioni, valutazioni e curiosità relative al mondo dei film e degli spettacoli, le persone di tutto il mondo utilizzano IMDB, che è un database online di tali informazioni. Sebbene le informazioni vengano aggiornate dai fan, il database stesso è di proprietà e gestito da una sussidiaria di Amazon. È stato inizialmente creato come database nel 1990 e spostato sul Web nel 1993. Sebbene chiunque possa accedere alle informazioni sul sito Web, la registrazione è d'obbligo nel caso in cui si desideri apportare modifiche ai fatti o aggiungere recensioni. In questo blog, diamo un'occhiata a come viene eseguito lo scraping web dei dati IMDB utilizzando Python.
Oltre a vari punti dati che vengono aggiornati sia per i film che per i programmi su piccolo schermo, IMDB consente anche ai suoi utenti di aggiungere valutazioni e queste valutazioni hanno costituito la base di più elenchi che vengono utilizzati dagli appassionati di cinema e altri per creare le proprie liste di controllo. Sebbene IMDB non fornisca un'API per interrogare i suoi dati, ti consente di scaricare i dati in formato testuale. Puoi anche raschiare i dati usando un codice fai-da-te.
Come viene eseguito il web scraping dei dati IMDB?
Raschieremo 2 set di dati da IMDB
un). I 250 migliori film di IMDB
b). I 250 migliori programmi televisivi di IMDB
Raschieremo alcuni punti dati per ogni film o programma in questi elenchi. Potresti non voler raschiare tutti i dati in una volta, e quindi abbiamo fornito l'opzione per cambiare il valore di un parametro, per estrarre solo i primi n risultati.
Avrai bisogno di Python3.7 o superiore insieme alla dipendenza BeautifulSoup e un editor di testo prima di iniziare. Quindi puoi eseguire il codice indicato di seguito usando il comando python stesso. Non è richiesto alcun input da parte dell'utente poiché abbiamo codificato i collegamenti dei due elenchi che abbiamo menzionato in precedenza nel codice.
Nel codice abbiamo 3 funzioni specifiche
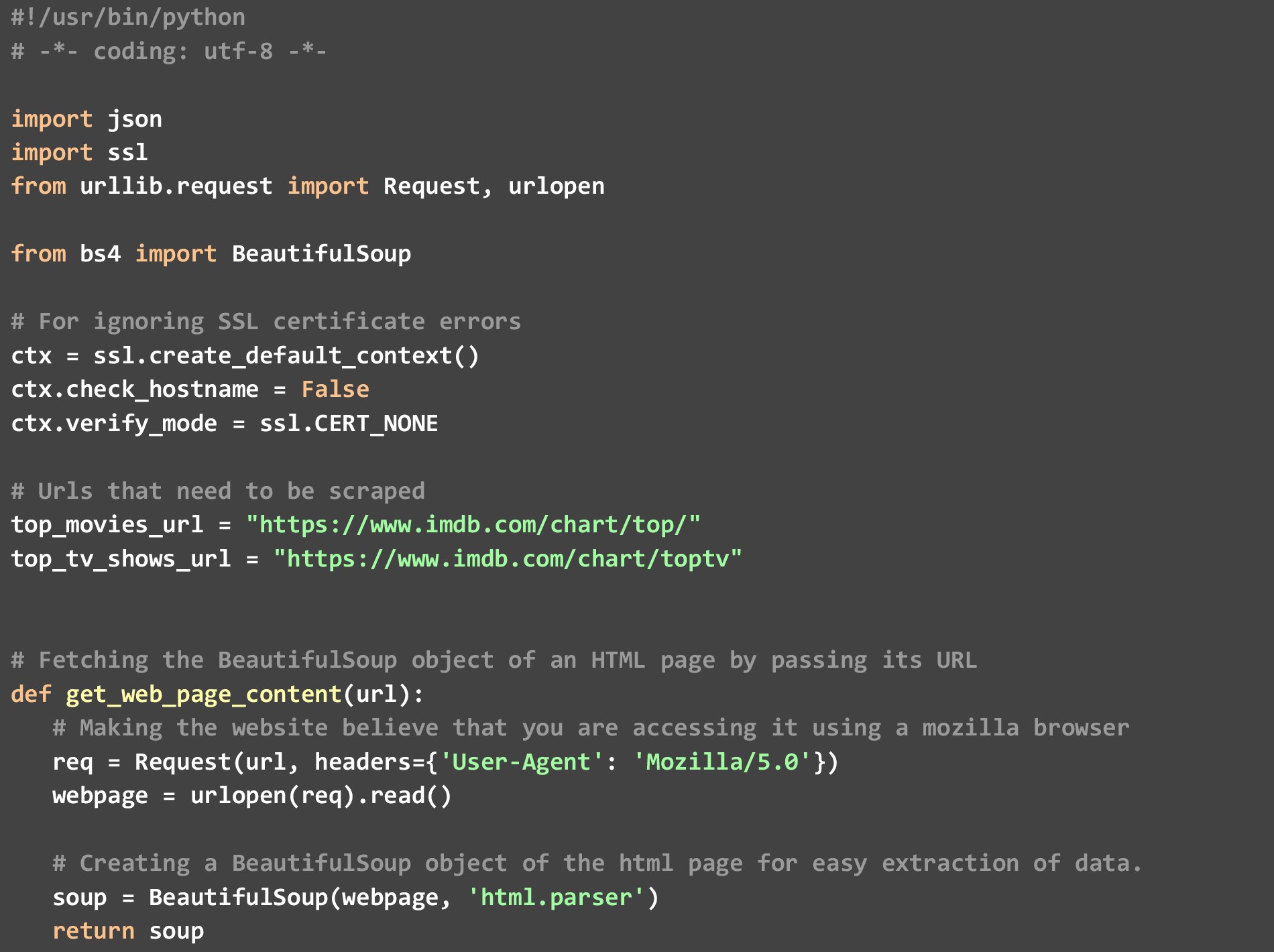
un). get_top_rated_imdb_hits- Qui è dove inizia l'esecuzione. Come input per questa funzione, passiamo l'URL dell'elenco in questione. Può essere l'URL dell'elenco dei film o l'URL dell'elenco dei programmi TV. Passiamo anche il nome del file in cui vogliamo il risultato JSON e il numero di risultati migliori che vogliamo. Recuperiamo determinati punti dati come il nome del film e le valutazioni disponibili sulla pagina Web stessa, quindi chiamiamo la funzione get_extra_details bypassando l'URL specifico del film/programma per recuperare punti dati aggiuntivi.
b). get_web_page_content- Questa funzione utilizzata per recuperare il contenuto HTML dell'URL passato in esso e convertirlo in un oggetto BeautifulSoup che può essere facilmente analizzato. Questo oggetto è ciò che questa funzione restituisce.
c). get_extra_details- Questa funzione utilizza l'URL specifico del film o dello spettacolo passato in esso dalla funzione get_top_rated_imdb_hits per recuperare ulteriori dettagli come il riepilogo, il nome delle migliori star e le informazioni sul regista non disponibili nella pagina Web dell'elenco classificato.
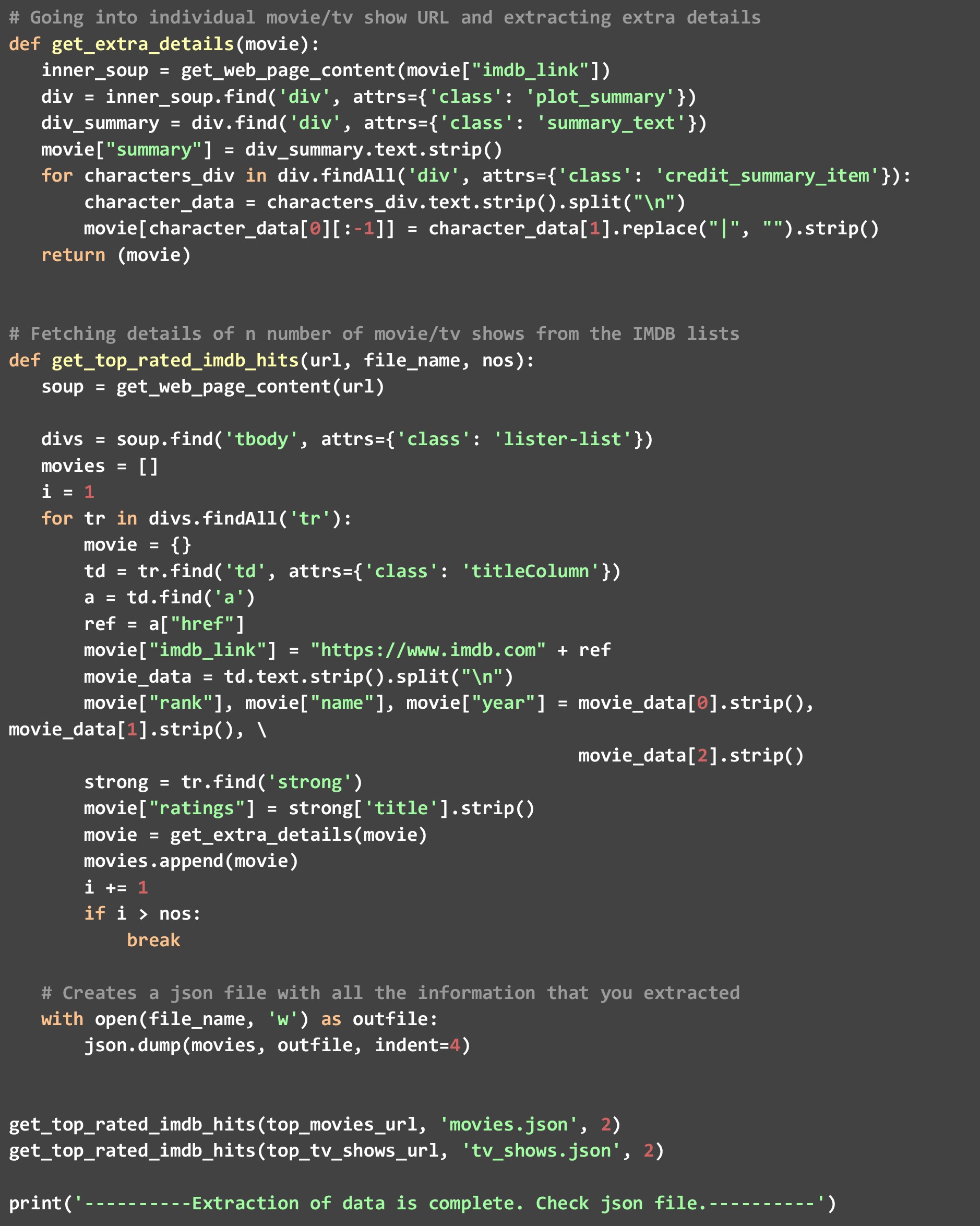

Come puoi vedere, abbiamo chiamato la funzione get_top_rated_imdb_hits due volte, una volta con l'URL dei film e una volta con l'URL dei programmi TV. Abbiamo anche superato il conteggio come 2 poiché desideriamo i dati solo per i primi due candidati in entrambe le liste. Una volta eseguito questo codice, vedrai due file creati nella tua directory: "movies.json" e "tv_shows.json".
I punti dati che abbiamo estratto
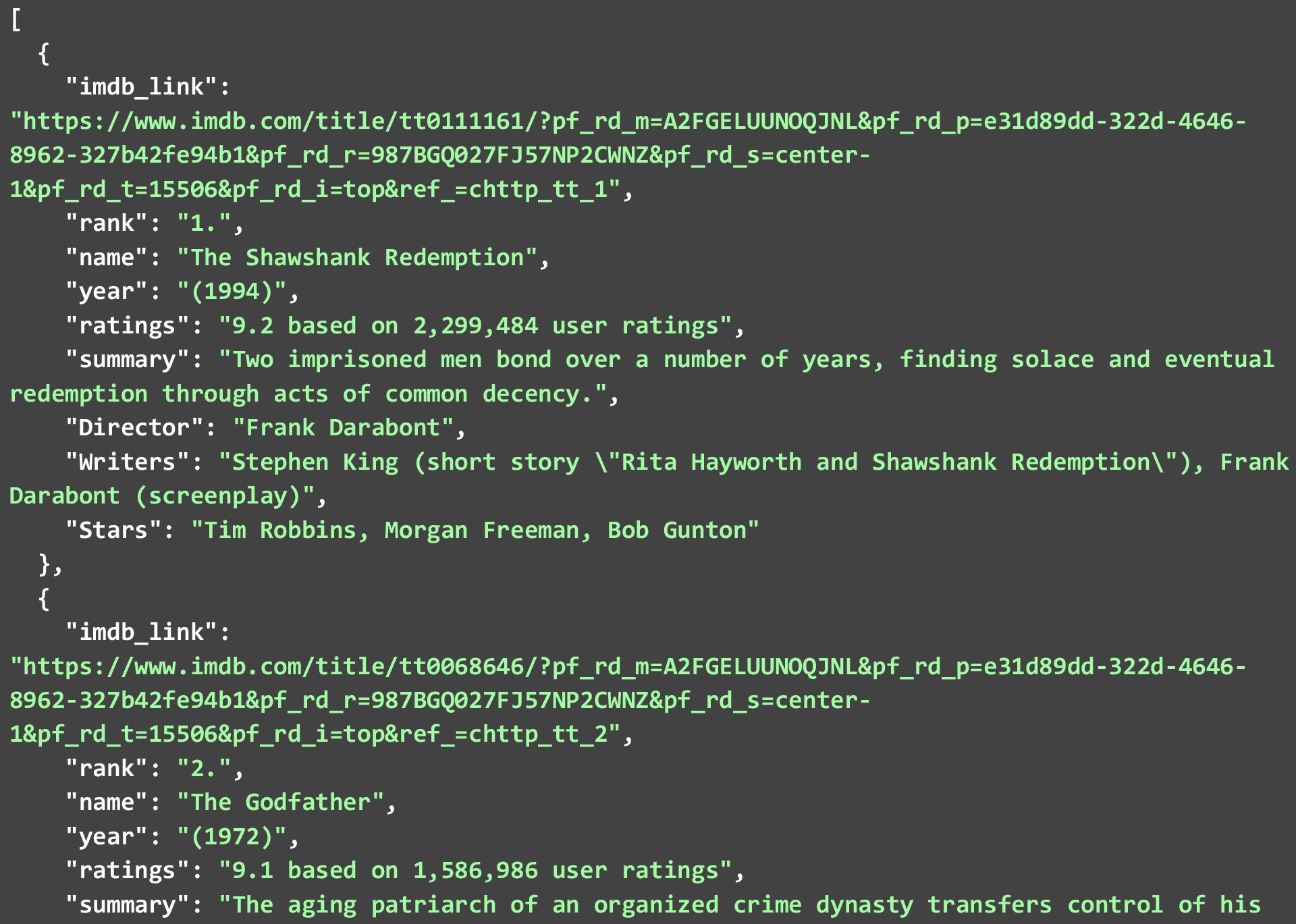
Per ogni film o programma TV, abbiamo estratto questi punti dati.
un). Collegamento IMDB per lo spettacolo/film specifico
b). Rango
c). Nome
d). Anno
e). Giudizi
f). Riepilogo
g). Direttore
h). Scrittori
io). Stelle
Una cosa da notare è che non tutti i punti dati potrebbero essere disponibili per ogni film o programma, ma quello disponibile verrà scartato. Il JSON di seguito mostra i primi 2 film nell'elenco dei primi 250 film in IMDB che abbiamo ottenuto eseguendo il codice sopra.

Mentre abbiamo raschiato i dati come erano e apportato modifiche minime ai dati stessi. È possibile pulire ulteriormente i dati per rendere i punti dati più utilizzabili. Alcuni esempi sarebbero
un). Rimozione delle parentesi sull'anno.
b). Suddividere le valutazioni in 2 punti dati separati, le valutazioni e il numero di persone che hanno inviato le loro valutazioni.
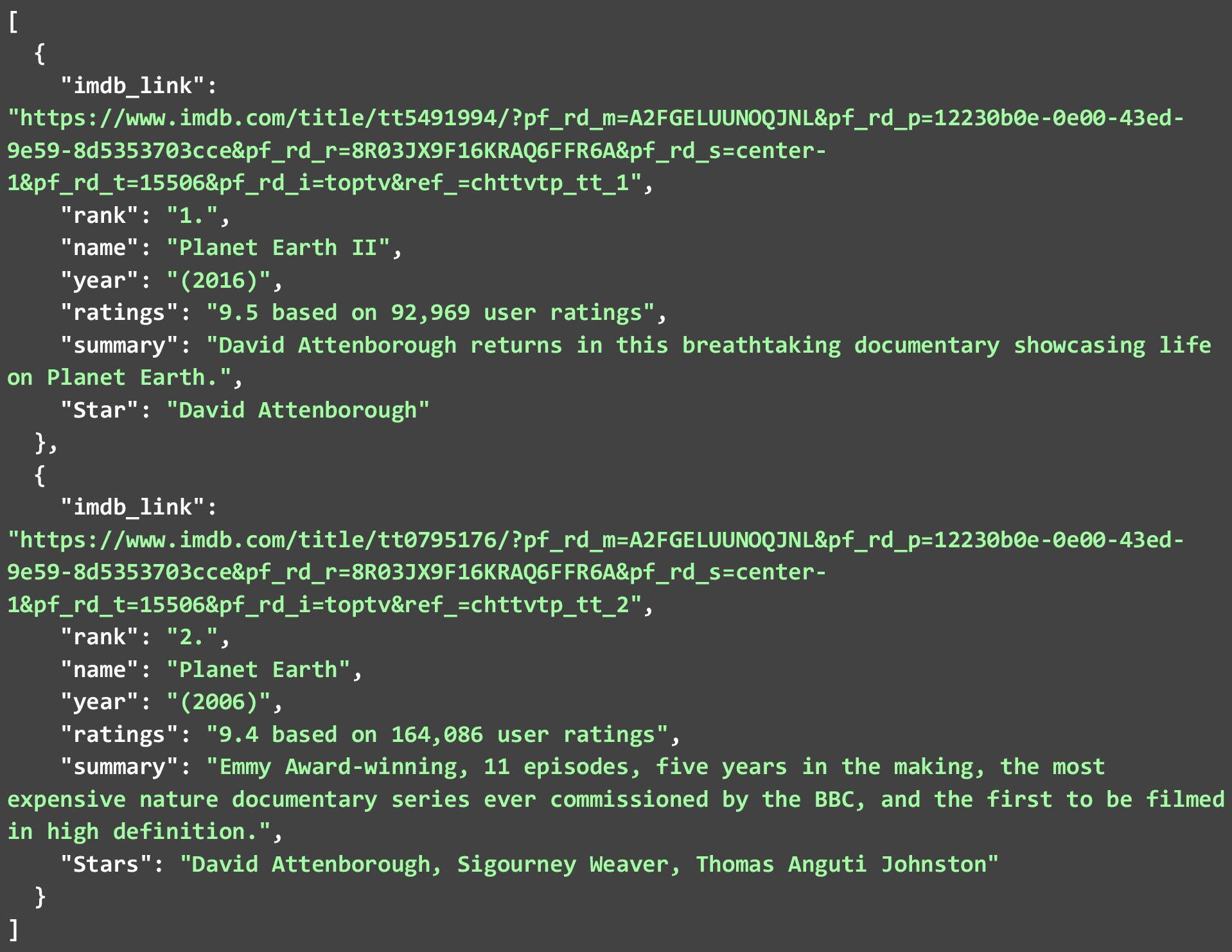
Il JSON di seguito mostra i primi 2 programmi TV che abbiamo estratto dalla seconda pagina web. Dal momento che molti di questi web scraper sono disponibili là fuori. Diamo un'occhiata a come possiamo estrarre i dati IMDB dal loro sito Web per diversi programmi TV . Il codice seguente è una spiegazione dettagliata di come può essere fatto.
Mentre abbiamo estratto solo 2 da ciascuna lista. Puoi consentire al codice di essere eseguito per tutti i 250 spettacoli o film e creare un enorme file JSON. Puoi persino archiviare i dati che estrai in un database. Ma per eseguire il codice su così tanti collegamenti. Dovrai seguire alcune best practice e tenere a mente alcuni vincoli durante lo scraping web dei dati IMDB.
Vincoli e buone pratiche
Nel caso in cui tu abbia eseguito questo codice e modificato il valore di "nos" per dire 250 e eseguito il codice su tutti i 250 film e programmi TV. C'è un'alta probabilità che il sito Web rilevi il traffico automatizzato dal tuo IP e finirai per essere bloccato. Dovrai utilizzare strumenti come la rotazione IP. Puoi anche creare un tempo di attesa di alcuni secondi tra lo scraping del contenuto HTML di ciascun URL.
Per quanto riguarda i dati che raschia, anche se la maggior parte dei suoi contenuti è stata creata da volontari. Potrebbero esserci alcune restrizioni sull'uso commerciale dei dati. È necessario seguire le normative ovunque si utilizzino dati acquisiti da diverse pagine Web. Ecco come web scraping i dati IMDB usando Python.
Tuttavia, se desideri un'esperienza di scraping web senza problemi in cui qualcuno si prende cura dei dati e puoi concentrarti sul tuo modello di business principale, il nostro team di PromptCloud è al tuo servizio. Siamo orgogliosi della nostra soluzione DaaS in cui ci occupiamo di tutto. Dallo scraping all'accesso ai dati raschiati.
Se ti è piaciuto il contenuto di cui sopra, siamo sicuri che ti piacerebbe leggere anche questo . Per favore lasciaci il tuo prezioso feedback nella sezione commenti qui sotto.