
Web Scraping IMDB pentru cele mai bune filme și emisiuni
Publicat: 2020-12-08Ai vrea să știi care sunt cele mai bune 250 de filme din toate timpurile? Sau cele mai bune spectacole de comedie care au ajuns vreodată pe micile ecrane? Pentru toate astfel de răspunsuri, recenzii, evaluări și trivia legate de lumea filmelor și emisiunilor, oamenii din întreaga lume folosesc IMDB, care este o bază de date online cu astfel de informații. În timp ce informațiile sunt actualizate de fani, baza de date în sine este deținută și operată de o filială a Amazon. A fost creată inițial ca bază de date în 1990 și mutată pe web în 1993. Deși oricine poate accesa informațiile de pe site, înregistrarea este obligatorie în cazul în care doriți să faceți modificări la fapte sau să adăugați recenzii. În acest blog, aruncăm o privire asupra modului în care se realizează scrapingul web a datelor IMDB folosind Python.
Pe lângă diferitele puncte de date care sunt actualizate atât pentru filme, cât și pentru emisiunile pe ecran mic, IMDB le permite utilizatorilor săi să adauge evaluări, iar aceste evaluări au stat la baza mai multor liste care sunt folosite de pasionații de film și de alții pentru a-și crea listele de vizionare. Deși IMDB nu oferă un API pentru a-și interoga datele, vă permite să descărcați datele în format textual. De asemenea, puteți răzui datele folosind un cod DIY.
Cum se face scrapingul web a datelor IMDB?
Vom extrage 2 seturi de date de la IMDB
A). Top 250 de filme IMDB
b). Top 250 de emisiuni de televiziune IMDB
Vom analiza anumite puncte de date pentru fiecare film sau emisiune din aceste liste. Este posibil să nu doriți să răzuiți toate datele simultan și, prin urmare, am oferit opțiunea de a schimba valoarea unui parametru, pentru a extrage doar cele n rezultate de top.
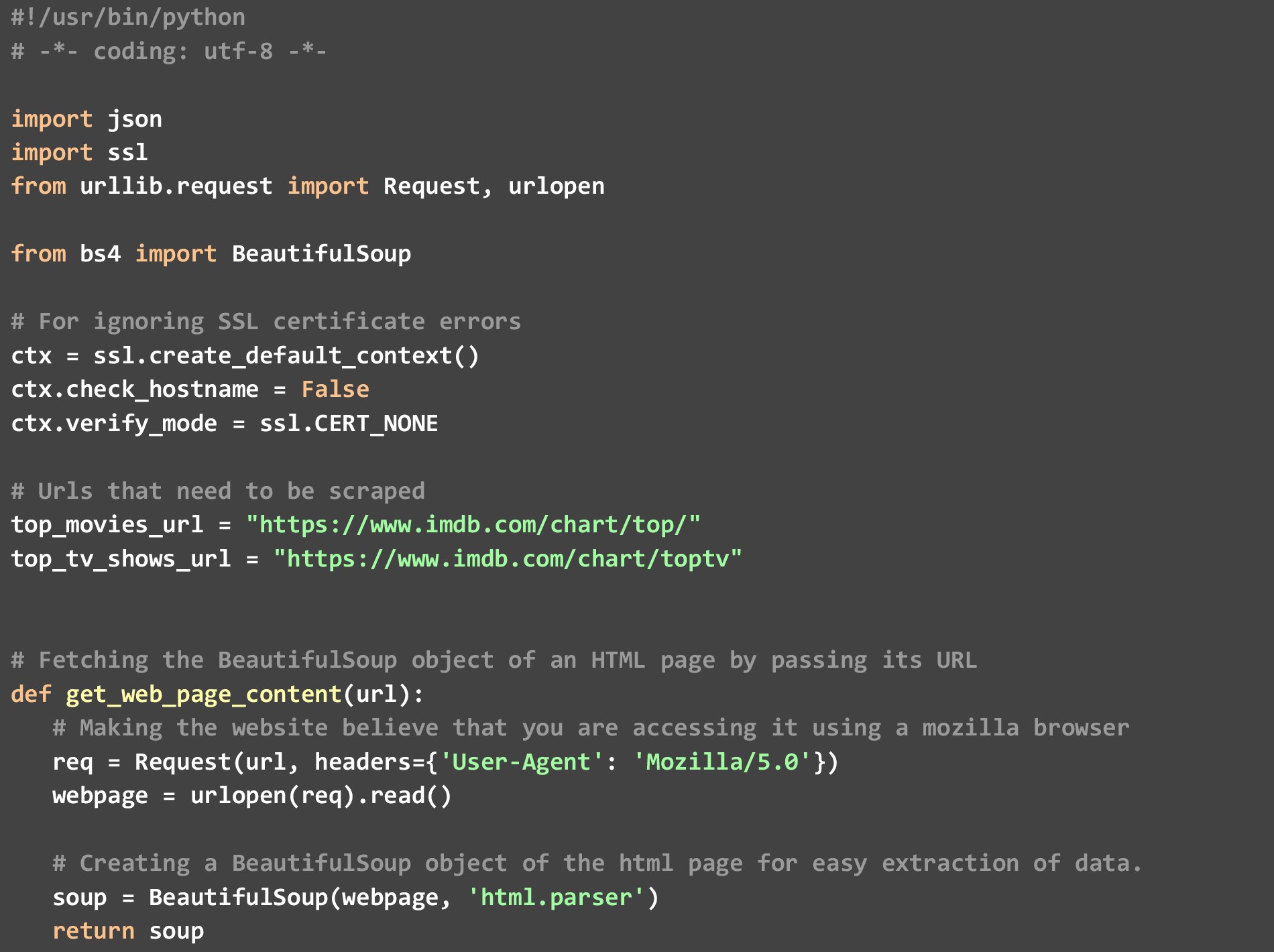
Veți avea nevoie de Python 3.7 sau mai mare, împreună cu dependența BeautifulSoup și un editor de text înainte de a începe. Apoi puteți rula codul de mai jos folosind comanda python în sine. Nu este necesară introducerea utilizatorului, deoarece am codificat legăturile celor două liste pe care le-am menționat mai devreme în cod.
În cod, avem 3 funcții specifice
A). get_top_rated_imdb_hits- Aici începe execuția. Ca intrare pentru această funcție, transmitem adresa URL a listei în cauză. Poate fi adresa URL a listei de filme sau URL-ul listei de emisiuni TV. De asemenea, trecem numele fișierului în care dorim rezultatul JSON și numărul de rezultate de top pe care le dorim. Preluăm anumite puncte de date, cum ar fi numele filmului și evaluările care sunt disponibile pe pagina web însăși, apoi apelăm funcția get_extra_details ocolind adresa URL specifică filmului/afișării pentru a obține puncte de date suplimentare.
b). get_web_page_content- Această funcție folosită pentru a prelua conținutul HTML al adresei URL transmise în acesta și pentru a-l converti într-un obiect BeautifulSoup care poate fi analizat cu ușurință. Acest obiect este ceea ce returnează această funcție.
c). get_extra_details- Această funcție folosește adresa URL specifică filmului sau emisiunii transmisă de funcția get_top_rated_imdb_hits pentru a obține mai multe detalii, cum ar fi rezumatul, numele vedetelor de top și informațiile despre regizor care nu sunt disponibile în pagina web cu clasare.
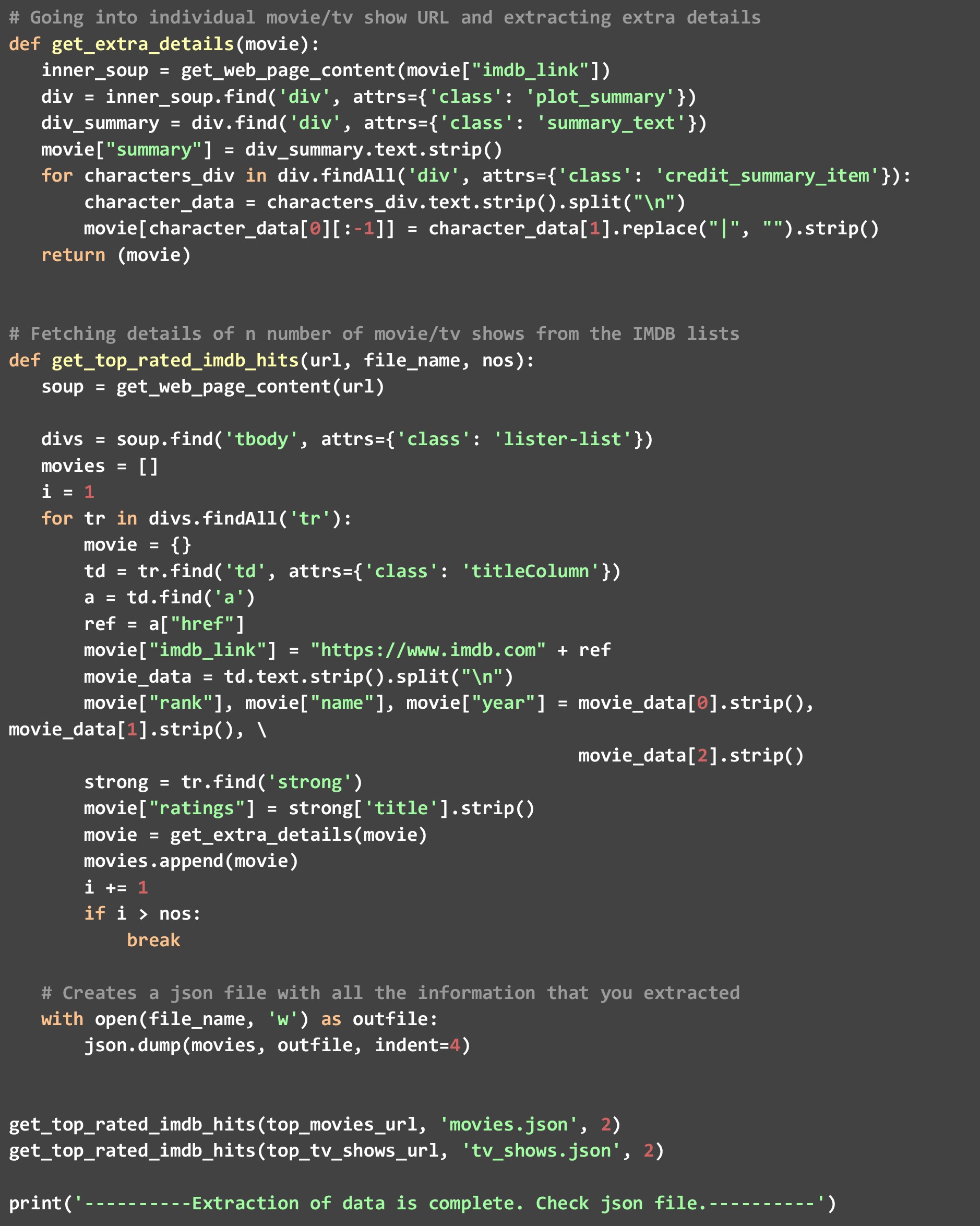
După cum puteți vedea, am apelat funcția get_top_rated_imdb_hits de două ori, o dată cu URL-ul filmelor și o dată cu URL-ul emisiunilor tv. De asemenea, am trecut de numărul 2, deoarece dorim datele numai pentru primii doi candidați din ambele liste. Odată ce acest cod rulează, veți vedea două fișiere create în directorul dvs. - „movies.json” și „tv_shows.json”.

Punctele de date pe care le-am extras
Pentru fiecare film sau emisiune TV, am extras aceste puncte de date.
A). Link IMDB pentru emisiunea/filmul specific
b). Rang
c). Nume
d). An
e). Evaluări
f). rezumat
g). Director
h). Scriitori
i). Stele
Un lucru de reținut este că nu toate punctele de date pot fi disponibile pentru fiecare film sau emisiune, dar oricare dintre acestea este disponibil va fi eliminat. JSON de mai jos arată primele 2 filme din lista de top-250 de filme din IMDB pe care le-am obținut la rularea codului de mai sus.
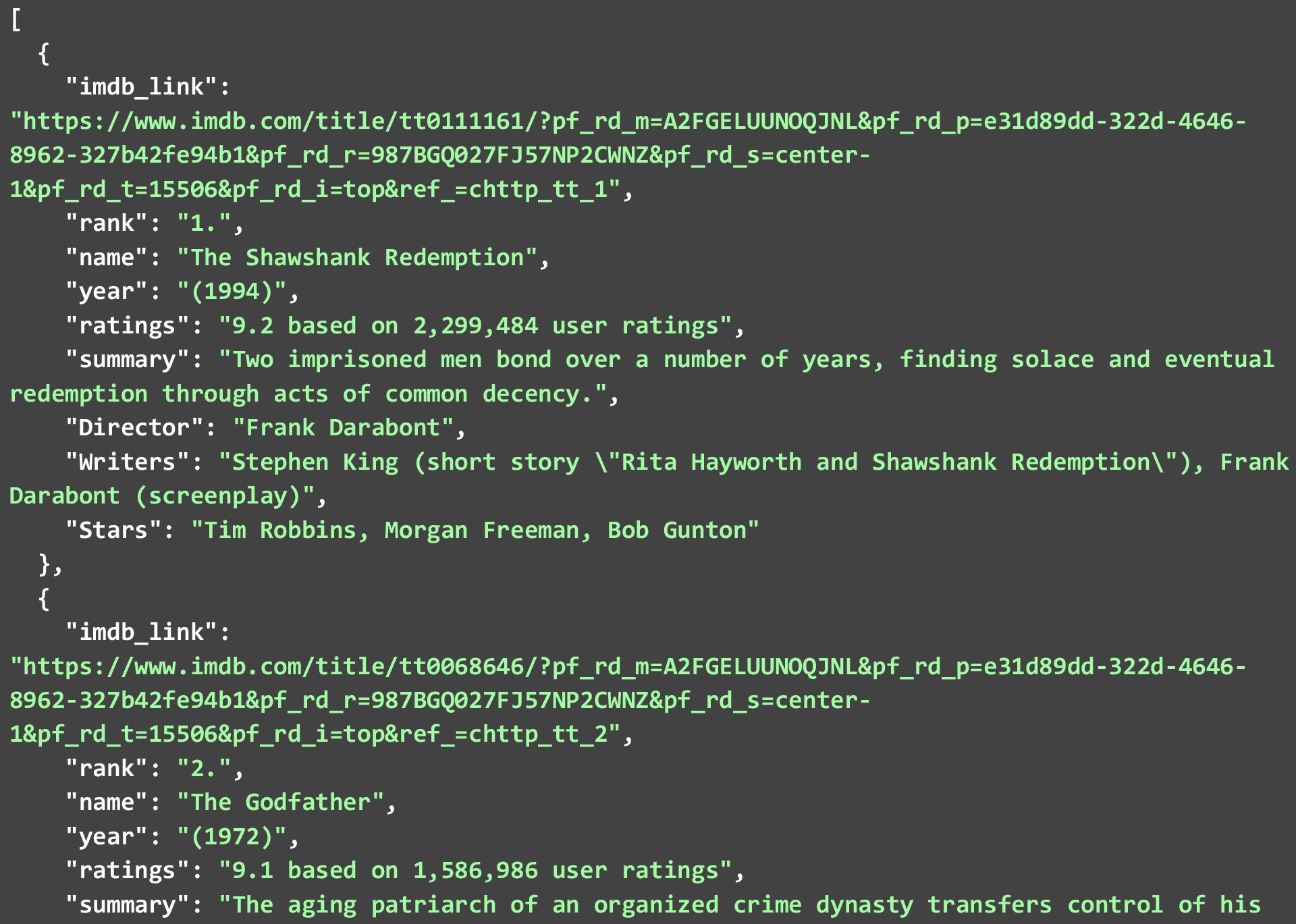

În timp ce am răzuit datele așa cum erau și am făcut modificări minime la datele în sine. Puteți curăța datele în continuare pentru a face punctele de date mai utilizabile. Câteva exemple ar fi
A). Scoaterea parantezelor pe an.
b). Împărțirea evaluărilor în 2 puncte de date separate, evaluările și numărul de persoane care și-au trimis evaluările.
JSON de mai jos arată primele 2 emisiuni TV pe care le-am extras din a doua pagină web. Deoarece multe astfel de răzuitoare web sunt disponibile acolo. Să aruncăm o privire la modul în care putem extrage datele IMDB de pe site-ul lor pentru diferite emisiuni TV . Codul de mai jos este o explicație detaliată a modului în care se poate face.
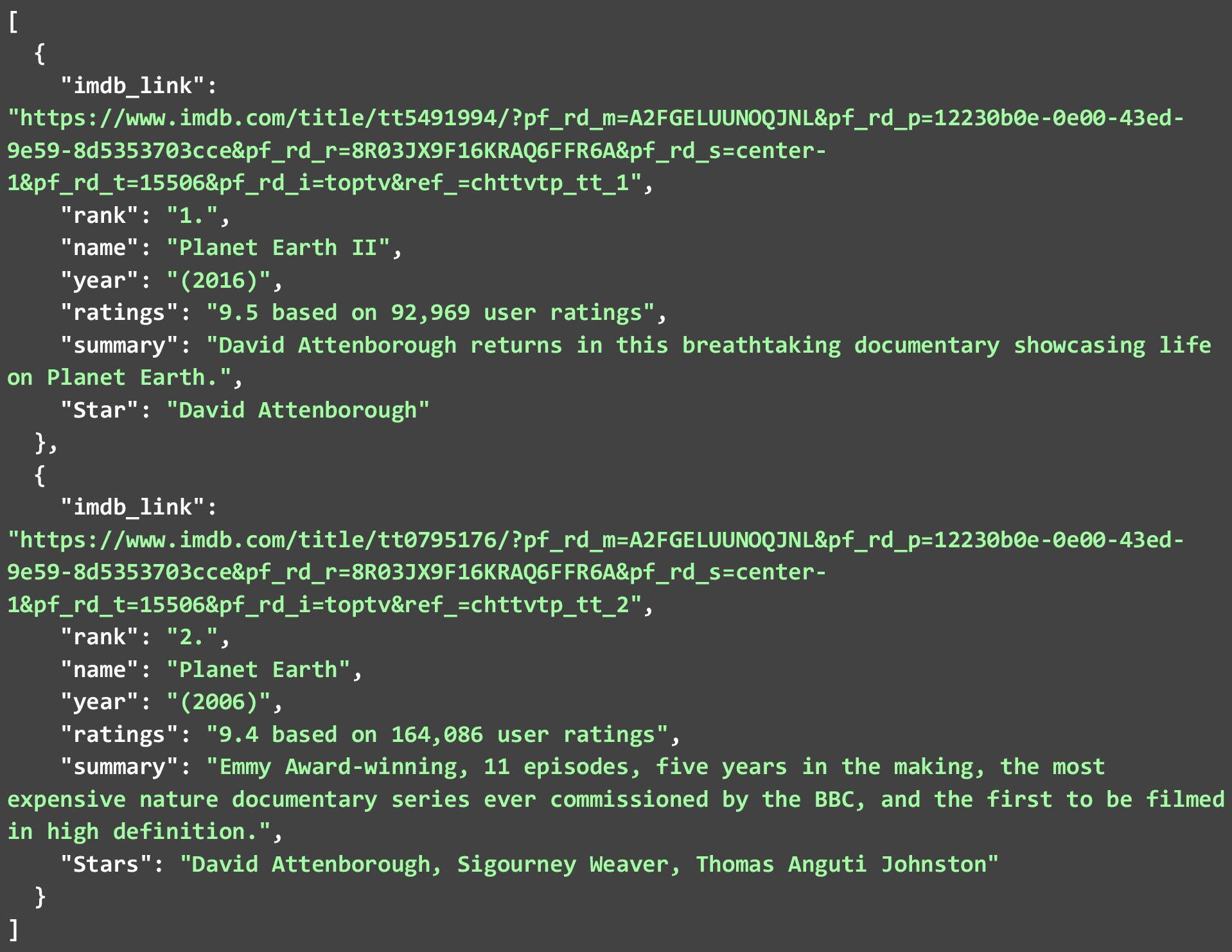
În timp ce noi am extras doar 2 din fiecare listă. Puteți permite rularea codului pentru toate cele 250 de emisiuni sau filme și puteți crea un fișier JSON masiv. Puteți chiar să stocați datele pe care le extrageți într-o bază de date. Dar pentru rularea codului pe atât de multe link-uri. Va trebui să urmați câteva bune practici și să țineți cont de unele constrângeri în timp ce răzuiți datele IMDB pe web.
Constrângeri și bune practici
În cazul în care ați rulat acest cod și ați schimbat valoarea „nos” pentru a spune 250 și ați rulat codul în toate cele 250 de filme și emisiuni TV. Există șanse mari ca site-ul web să detecteze trafic automat de la IP-ul tău și să ajungi să fii blocat. Va trebui să utilizați instrumente precum rotația IP. De asemenea, puteți crea un timp de așteptare de câteva secunde între răzuirea conținutului HTML al fiecărei adrese URL.
În ceea ce privește datele pe care le răzuiești, chiar dacă majoritatea conținutului lor este creat de voluntari. Pot exista anumite restricții privind utilizarea comercială a datelor. Trebuie să respectați reglementările oriunde utilizați date extrase din diferite pagini web. Acesta este modul în care web scraping datele IMDB folosind Python.
Cu toate acestea, dacă doriți o experiență de web scraping fără probleme, în care cineva are grijă de date și vă puteți concentra pe modelul dvs. de afaceri de bază, echipa noastră de la PromptCloud vă stă la dispoziție. Ne mândrim cu soluția noastră DaaS, unde ne ocupăm de tot. Chiar de la scraping până la accesarea datelor scraped.
Dacă ți-a plăcut conținutul de mai sus, suntem siguri că ți-ar plăcea să citești și asta . Vă rugăm să ne lăsați feedbackul dumneavoastră valoros în secțiunea de comentarii de mai jos.