
網絡抓取服務外包比內部更好
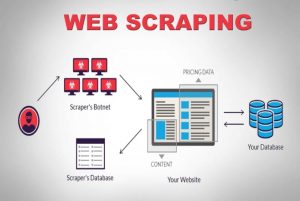
已發表: 2020-04-02我們生活在一個以數據為中心的世界中,數據是最強大的商品。 有了正確的數據,我們就能發揮作用。 它無處不在:機器學習、數據挖掘、市場研究、金融研究等等。 最大的問題仍然存在——您如何檢索所有可供消費的數據? 為了獲得如此規模和復雜的數據,我們爬取了源網站。 因此,網絡抓取服務不再是可選的。 如果您有任何可以想像的數據驅動策略,它們是必不可少的。
關於數據抓取的一個有趣事實是它說明了它的作用,它不是一個開箱即用的解決方案。 那麼,公司如何通過抓取網絡來獲取數據呢? 他們是建立內部團隊還是外包給專門的網絡抓取服務公司? 由於我們談論的是抓取大量不同複雜性的數據,因此 DIY 抓取工具是不可能的。
讓我們考慮第一個選項。 我們總是可以聘請該領域的專家團隊來培訓能夠理解網絡爬蟲細微差別的內部團隊。 這些公司不必擔心被抓取數據的隱私。 雖然這聽起來像是一個理想的選擇,但也有一些缺點。
建立和維護一個專門的內部團隊的絕對成本將是巨大的。 這可以通過將其完全外包給專業的數據抓取服務來完全繞過,該服務的專業知識主要在於網絡抓取項目。 您可以節省時間、精力,最重要的是金錢。
還是不服氣? 以下是選擇專用網絡抓取服務的其他一些原因。
一個)。 網站日益複雜:
需求法則也在這裡發揮作用。 需求越多,爬取它所涉及的複雜性就越大。 這不僅難倒了可用的 DIY 工具選項,甚至難倒了最近接受過網絡抓取培訓的人員。 最重要的是,許多網站正在採用基於 AJAX 的無限滾動來改善用戶體驗。 這使得抓取更加複雜。
這種動態編碼實踐將使大多數 DIY 工具甚至一些內部團隊變得低效和無用。 這裡需要的是完全可定制的設置和專用方法。 手動和自動層的組合用於確定網站如何接收 AJAX 調用以使用定制的爬蟲來模仿它們。 隨著網站的複雜性隨著時間的推移不斷增加,對可定制解決方案的需求變得非常明顯。


乙)。 提取過程的可擴展性:
許多企業家覺得有必要重新發明輪子。 他們有在內部執行流程而不是外包的衝動。 當然,有些流程最好在內部完成,客戶支持就是一個很好的例子。 由於與大規模 Web 數據提取相關的複雜性太小而無法由不專門從事此操作的公司掌握,因此這可能不是一個好主意。 最大的公司外包屬於技術領域的服務。 (s)
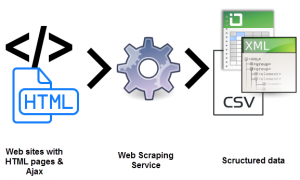
同時提取數百萬個網頁並將它們全部處理成結構化的機器可讀數據是一項真正的挑戰。 網絡爬蟲解決方案的 USP 之一是可擴展性。 由於高性能服務器集群分散在不同的地理位置, PromptCloud等服務已經建立了一個堅如磐石的基礎設施來提取大規模的 Web 數據。
C)。 數據質量和維護:
提取數據是一回事。 另一個將非結構化數據轉換為機器可讀數據。 像PromptCloud這樣的服務所提倡的是將抓取作為保持數據質量的一種手段。
如果數據不可讀,那麼抓取大量原始、非結構化數據將毫無意義。 同時,我們不能建立一個功能齊全的網絡爬蟲設置和放鬆。 萬維網是高度動態的。
保持數據質量需要持續努力並使用手動和自動層進行密切監控。 網站經常更改其結構,這會導致爬蟲出現故障或停止,這兩者都會影響輸出數據。 數據質量保證和及時維護對於運行網絡爬蟲設置是不可或缺的。 尋找對這些方面具有端到端所有權的服務。

d)。 借助 Web Scraping 輕鬆提取數據:
企業需要將全部精力集中在其核心產品上。 因此,需要聘請網絡抓取服務,將其全部精力集中在您所尋求的內容上。
Web 數據提取帶來的設置、持續維護和所有其他復雜性很容易占用您的內部資源,從而對您的業務造成影響。 陷阱實在太多了。

e)。 跨越技術壁壘:
Web 抓取需要一組開發人員在優化的服務器上設置和部署爬蟲以進行提取。 這對技術要求很高。 為什麼要在可以僱用時進行培訓? 成本的十分之一。 憑藉在網絡數據提取領域多年的專業知識,專門的服務可以承擔任何復雜性和規模的網站抓取項目。 這是一篇展示可用於任何項目的 Web 抓取服務模板的文章。
結論:
公司不可避免地要探索有效獲取大量數據和強大數據的方法。 有數據,有信息,然後是單數,知識。 知識是我們理解和組織信息的地方,這些信息是我們從隨機、非結構化和其他(看似)無用的數據中拼湊而成的。 為此和其他一切,有Promptcloud 。