
Web Scraping IMDB para las mejores películas y espectáculos
Publicado: 2020-12-08¿Te gustaría saber cuáles son las 250 mejores películas de todos los tiempos? ¿O los mejores programas de comedia que han llegado a las pantallas pequeñas? Para todas esas respuestas, reseñas, calificaciones y curiosidades relacionadas con el mundo de las películas y los programas, personas de todo el mundo usan IMDB, que es una base de datos en línea de dicha información. Si bien los fanáticos actualizan la información, la base de datos en sí es propiedad y está operada por una subsidiaria de Amazon. Inicialmente se creó como una base de datos en 1990 y se trasladó a la web en 1993. Si bien cualquiera puede acceder a la información en el sitio web, el registro es imprescindible en caso de que desee editar los datos o agregar reseñas. En este blog, echamos un vistazo a cómo se realiza el web scraping de datos IMDB usando Python.
Además de varios puntos de datos que se actualizan tanto para películas como para programas de pantalla pequeña, IMDB también permite a sus usuarios agregar calificaciones y estas calificaciones han formado la base de múltiples listas que utilizan los cinéfilos y otros para crear sus listas de observación. Si bien IMDB no proporciona una API para consultar sus datos, le permite descargar los datos en formato de texto. También puede raspar los datos usando un código de bricolaje.
¿Cómo se realiza el web scraping de datos IMDB?
Estaremos raspando 2 conjuntos de datos de IMDB
a). Las 250 mejores películas de IMDB
b). Los 250 mejores programas de televisión de IMDB
Estaremos raspando ciertos puntos de datos para cada película o programa en estas listas. Es posible que no desee raspar todos los datos a la vez y, por lo tanto, hemos brindado la opción de cambiar el valor de un parámetro, para extraer solo los primeros n resultados.
Necesitará Python3.7 o superior junto con la dependencia de BeautifulSoup y un editor de texto antes de comenzar. Luego puede ejecutar el código que se proporciona a continuación usando el comando python. No se requiere ninguna entrada del usuario ya que hemos codificado los enlaces de las dos listas que mencionamos anteriormente en el código.
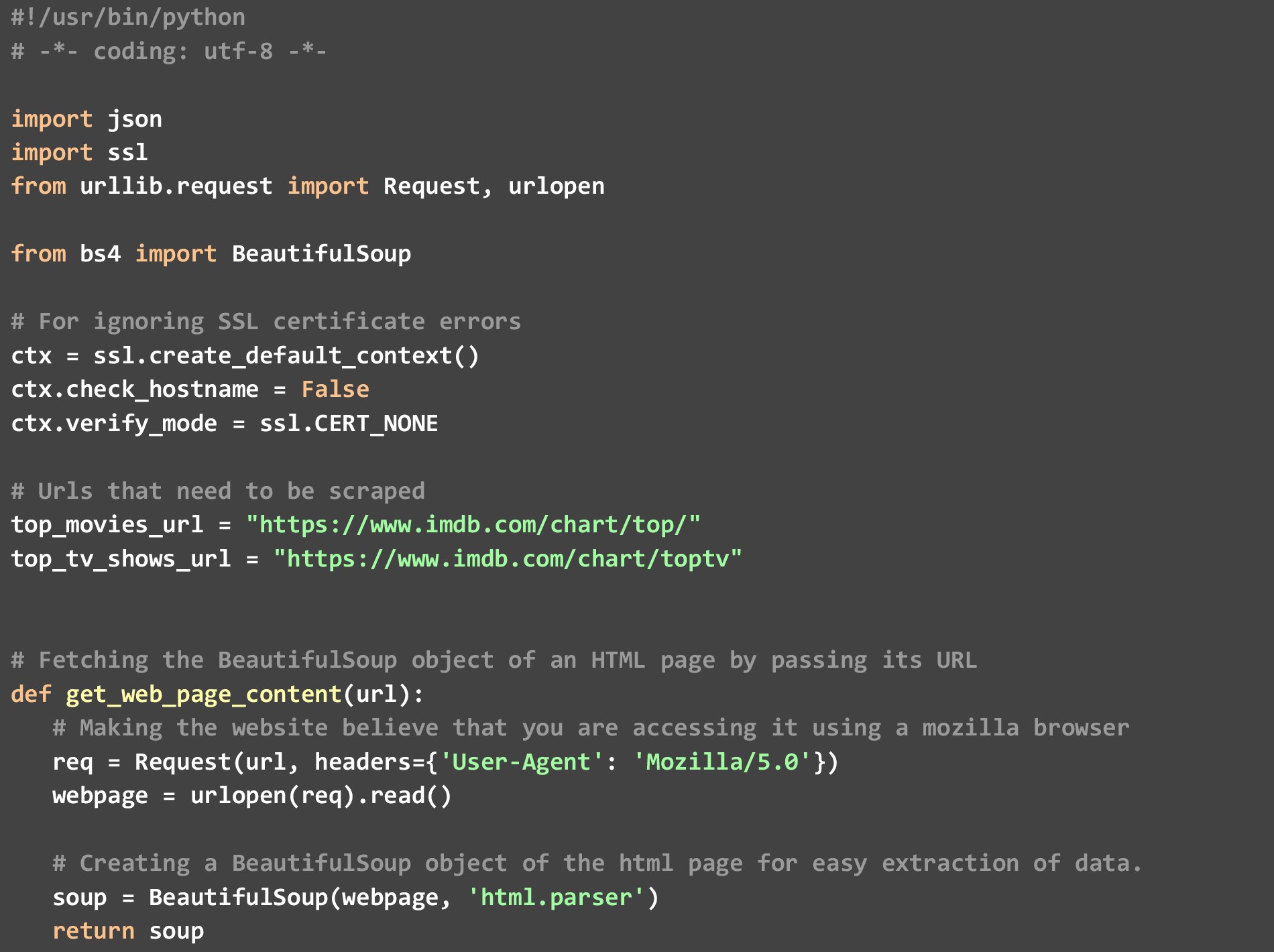
En el código, tenemos 3 funciones específicas.
a). get_top_rated_imdb_hits: aquí es donde comienza la ejecución. Como entrada a esta función, pasamos la URL de la lista en cuestión. Puede ser la URL de la lista de películas o la URL de la lista de programas de televisión. También pasamos el nombre del archivo en el que queremos el resultado JSON y la cantidad de resultados principales que queremos. Obtenemos ciertos puntos de datos, como el nombre de la película y las calificaciones que están disponibles en la propia página web, y luego llamamos a la función get_extra_details sin pasar por la URL específica de la película/programa para obtener puntos de datos adicionales.
b). get_web_page_content: esta función solía obtener el contenido HTML de la URL que se le pasó y convertirlo en un objeto BeautifulSoup que se puede analizar fácilmente. Este objeto es lo que devuelve esta función.
C). get_extra_details: esta función utiliza la URL específica de la película o del programa que le pasó la función get_top_rated_imdb_hits para obtener más detalles, como el resumen, el nombre de las principales estrellas y la información del director que no está disponible en la página web de la lista clasificada.
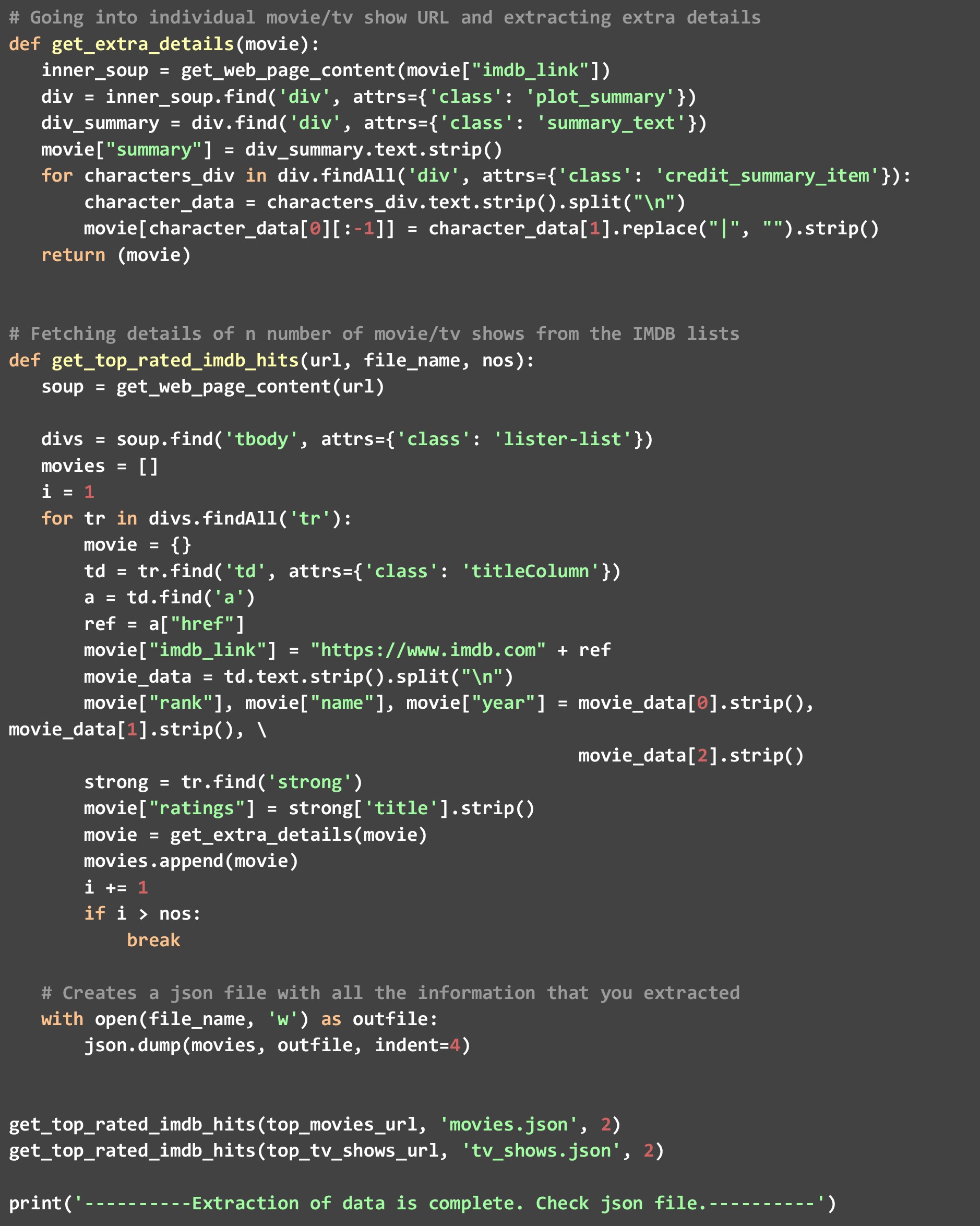
Como puede ver, hemos llamado a la función get_top_rated_imdb_hits dos veces, una con la URL de las películas y otra con la URL de los programas de televisión. También hemos superado el conteo como 2, ya que queremos los datos solo de los dos primeros candidatos en ambas listas. Una vez que se ejecute este código, verá dos archivos creados en su directorio: "movies.json" y "tv_shows.json".

Los puntos de datos que extrajimos
Para cada película o programa de televisión, extrajimos estos puntos de datos.
a). Enlace IMDB para el programa/película específico
b). Rango
C). Nombre
d). Año
mi). Calificaciones
F). Resumen
gramo). Director
h). escritores
i). Estrellas
Una cosa a tener en cuenta es que no todos los puntos de datos pueden estar disponibles para cada película o programa, pero cualquiera que esté disponible se descartará. El siguiente JSON muestra las 2 mejores películas en la lista de las 250 mejores películas en IMDB que obtuvimos al ejecutar el código anterior.
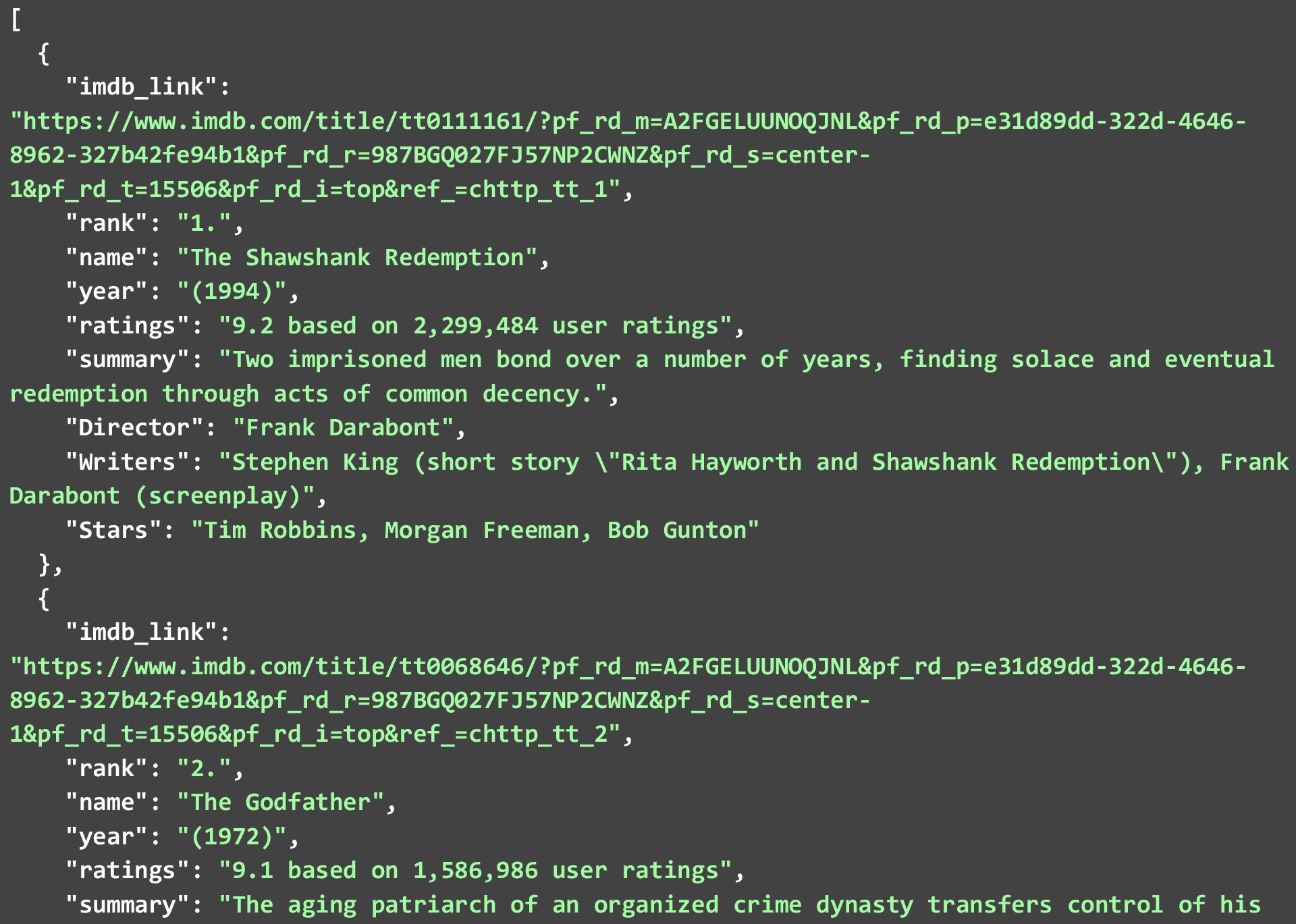

Si bien hemos extraído los datos tal como estaban y hemos realizado cambios mínimos en los datos en sí. Puede limpiar más los datos para que los puntos de datos sean más utilizables. Algunos ejemplos serían
a). Eliminación de los corchetes en el año.
b). Desglose de las calificaciones en 2 puntos de datos separados, las calificaciones y la cantidad de personas que enviaron sus calificaciones.
El JSON a continuación muestra los 2 mejores programas de televisión que extrajimos de la segunda página web. Dado que muchos de estos raspadores web están disponibles por ahí. Echemos un vistazo a cómo podemos extraer datos de IMDB de su sitio web para diferentes programas de televisión . El siguiente código es una explicación detallada de cómo se puede hacer.
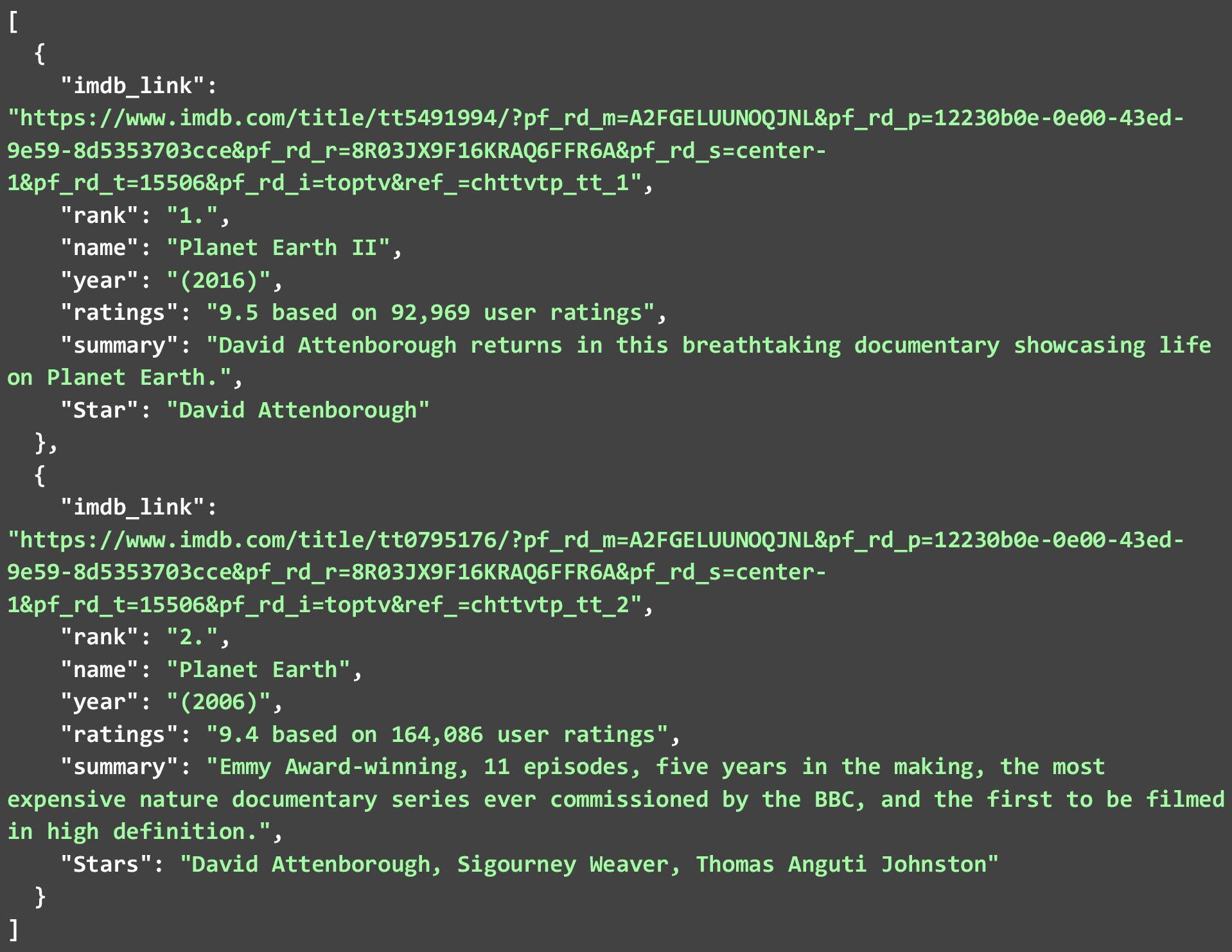
Si bien hemos extraído solo 2 de cada lista. Puede permitir que el código se ejecute para todos los 250 programas o películas y crear un archivo JSON masivo. Incluso puede almacenar los datos que extrae en una base de datos. Pero para ejecutar el código en tantos enlaces. Deberá seguir algunas de las mejores prácticas y tener en cuenta algunas restricciones al realizar el raspado web de datos de IMDB.
Restricciones y Mejores Prácticas
En caso de que haya ejecutado este código y haya cambiado el valor de "nos" para decir 250 y haya ejecutado el código en las 250 películas y programas de televisión. Existe una alta probabilidad de que el sitio web detecte tráfico automatizado de su IP y termine siendo bloqueado. Deberá usar herramientas como la rotación de IP. También puede crear un tiempo de espera de unos segundos entre raspar el contenido HTML de cada URL.
En cuanto a los datos que raspa, aunque la mayor parte de su contenido es creado por voluntarios. Puede haber ciertas restricciones en el uso comercial de los datos. Debe seguir las regulaciones dondequiera que esté utilizando datos extraídos de diferentes páginas web. Así es como se realiza el web scraping de datos IMDB usando Python.
Sin embargo, si desea una experiencia de web scraping sin complicaciones en la que alguien se encargue de los datos y usted pueda concentrarse en su modelo de negocio principal, nuestro equipo en PromptCloud está a su servicio. Nos enorgullecemos de nuestra solución DaaS donde nos encargamos de todo. Desde el raspado hasta el acceso a los datos raspados.
Si te gustó el contenido anterior, estamos seguros de que también te gustaría leer este . Por favor déjenos sus valiosos comentarios en la sección de comentarios a continuación.