
缺乏高質量數據是否限制了人工智能的發展?
已發表: 2020-12-23人工智能的未來掌握在高質量數據的手中
聽起來有點荒謬,不是嗎? 未來不應該掌握在人的手中嗎? 但是,如果您查看機器學習和人工智能的發展,您將能夠發現最新的創新依賴於當今人類和機器生成的大量數據。 由於數據數量和質量的增長,自動駕駛汽車和自然語言處理等最新創新中使用的神經網絡和深度學習算法的增長成為可能。 當您擁有較少的數據時,幾乎所有 AI 算法都會產生類似的結果,但是當您擁有 PB 級的數據時,您可以看到深度學習算法大放異彩。
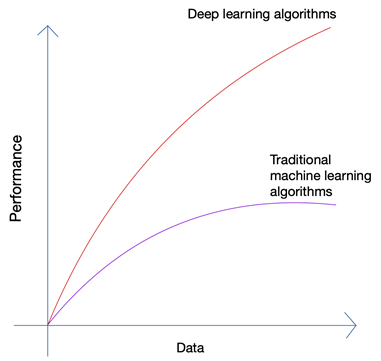
人類只能產生有限數量的數據,而大數據革命主要是由於越來越多的設備連接到互聯網並產生了更多的數據。 物聯網革命產生了比以往更多的數據。 沒有人可以解析如此龐大的數據,這反過來又導致了深度學習的基礎。
數據的三個主要問題
當您為尖端 AI 項目收集數據時,數量並不是唯一的問題。 無論您擁有多少數據,如果您想從算法中獲得最佳結果,數據的質量、清潔度和多樣性同樣重要。
一個)。 數量
如果你試圖為只有幾千行數據的自動駕駛汽車創建算法,你一定會遇到障礙。 為確保您的算法在實際場景中產生正確的結果,您需要在大量訓練數據上訓練您的算法。 由於當今幾乎可以從任何設備訪問日誌以及來自網絡的幾乎無限的數據流,因此收集數據並不是很困難; 只要您擁有正確的工具並且知道如何使用它們。
乙)。 種類
當您訓練算法以使用 AI 解決實際問題時,您的系統需要了解所有可能的數據點類型。 如果您無法獲得各種數據,您的系統將存在固有偏差並產生不正確的結果。
這種情況已經多次發生,包括美國《文學文摘》舉辦的著名的 1936 年總統選舉。 它預測的候選人將贏得總統競選,最終以超過 20% 的巨大差距落敗。 然而,該雜誌對 1000 萬人進行了調查,其中 227 萬人做出了回應——即使按照今天的標準,這也是一個天文數字。 哪裡出了問題?

好吧,當國家處於大蕭條的深淵時,他們無法理解大部分根本沒有回應的讀者以及那些無力訂閱雜誌的讀者的情緒。
C)。 質量
雖然最後兩個因素非常重要,並且可以通過一些努力來檢查,但即使您的結果不匹配,數據質量也更容易被遺漏並且難以檢測。 您知道數據不干淨的唯一方法是在數據投入生產後再次對其進行分析。
保持數據質量的一些簡單方法是刪除重複項、驗證傳入的每一行的架構、有一定的硬限制來檢查輸入每一行的值,以及跟踪異常值。 如果無法通過自動化控制某些因素,則可能還需要手動干預。 錯誤可能蔓延的一個主要點是數據轉換。 尤其是當您從多個來源累積數據時,並非所有數據點都具有相同的單位。 使用適當的方程式轉換值是必須的,並且需要全面實施。
從網絡上抓取的數據也可能包含結構化、半結構化和非結構化數據,當你想在你的 AI 項目中使用這些不同形式的數據時,你需要確保將它們全部轉換為相同的格式。
數據質量如何影響 AI 項目?
數據質量會影響任何機器學習或 AI 項目。 根據項目的規模,即使是數據中的簡單錯誤也可能導致結果大相徑庭。 如果您正在創建推薦引擎,並且您的訓練數據不夠乾淨,那麼推薦對用戶來說就沒有多大意義。
然而,掌握不干淨的數據是否在這一結果中發揮了作用可能很困難。 同樣,如果您正在設計預測算法並且數據存在某些缺陷,則某些預測可能仍然有效,而有些預測可能會有些偏差。 將這些點連接起來以實現臟數據帶來的差異可能很難重新創建。
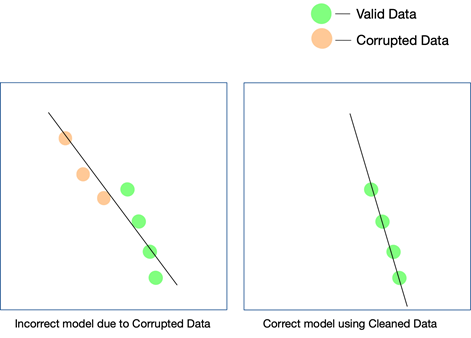
每個 AI 項目都是分階段發展的。 做出初始算法決策——即在給定數據集和特定用例的情況下,確定哪種算法效果最好。 如果您的數據存在不一致,您對算法本身的選擇可能會受到影響,並且您可能直到很久之後才會意識到這個謬誤。
確保您的模型在現實世界中有效的唯一方法是確保將乾淨的數據提供給 AI 系統,並繼續在越來越多的數據上對其進行測試。 您還可以使用強化學習來糾正模型偏離時的路徑。
網頁抓取可以成為解決方案嗎?
Web 抓取可以是一種解決方案,但前提是它與其他幾種工具結合使用,以確保在項目中使用之前徹底清理、驗證和驗證來自管道的數據的種類和數量。 即使您使用網絡抓取工具(無論是內部軟件還是付費軟件)從網絡獲取數據,該工具也不太可能對數據執行這些後處理任務以使其準備就緒使用。
您需要的是一個端到端的系統,它負責抓取數據、清理數據、驗證數據和驗證數據,以便最終輸出可以以即插即用的格式直接集成到業務工作流中。 從頭開始構建這樣的系統就像從山腳開始爬山一樣困難。
我們在 PromptCloud 的團隊提供網絡抓取服務——即您給我們要求,我們給您數據,即 DaaS(數據即服務)模型。 您需要做的就是訪問數據(將採用您選擇的格式和存儲介質),並將其與您當前的系統集成。 我們不僅從多個網站抓取數據,而且在各個級別使用多項檢查來確保我們提供的數據是乾淨的。 這些數據有助於使我們各個領域的客戶能夠使用人工智能和機器學習等尖端技術來簡化不同的流程並更好地了解他們的客戶。