
การไม่มีข้อมูลคุณภาพจำกัดการเติบโตของ AI หรือไม่?
เผยแพร่แล้ว: 2020-12-23อนาคตของ AI อยู่ในมือของข้อมูลคุณภาพ
ฟังดูไร้สาระนิดหน่อยใช่ไหม? อนาคตไม่ควรอยู่ในมือของมนุษย์หรือ? แต่ถ้าคุณดูที่การเติบโตของแมชชีนเลิร์นนิงและปัญญาประดิษฐ์ คุณจะเห็นว่านวัตกรรมล่าสุดได้ดึงข้อมูลจำนวนมหาศาลที่มนุษย์และเครื่องจักรสร้างขึ้นมาในปัจจุบัน การเติบโตของโครงข่ายประสาทเทียมและอัลกอริธึมการเรียนรู้เชิงลึกที่ใช้ในนวัตกรรมล่าสุด เช่น รถยนต์ที่ขับเคลื่อนด้วยตัวเองและการประมวลผลภาษาธรรมชาตินั้นเกิดขึ้นได้ก็ต่อเมื่อปริมาณและคุณภาพของข้อมูลเพิ่มขึ้นเท่านั้น เมื่อคุณมีข้อมูลน้อยกว่า อัลกอริธึม AI เกือบทั้งหมดจะให้ผลลัพธ์ที่คล้ายคลึงกัน แต่เมื่อคุณมีข้อมูลเป็นเพตาไบต์ คุณจะเห็นว่าอัลกอริธึมการเรียนรู้เชิงลึกเปล่งประกาย
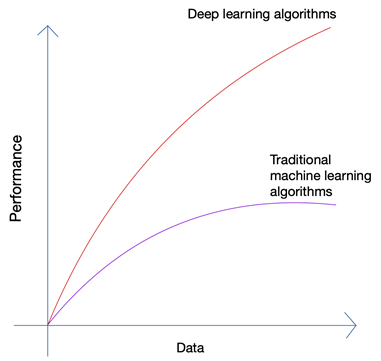
มนุษย์สามารถผลิตข้อมูลได้ในปริมาณที่จำกัด และการ ปฏิวัติข้อมูลขนาดใหญ่ ส่วนใหญ่เกิดจากอุปกรณ์ที่เชื่อมต่อกับอินเทอร์เน็ตมากขึ้นเรื่อยๆ และผลิตข้อมูลมากขึ้น การปฏิวัติ IoT ได้ผลิตข้อมูลมากกว่าที่เคยเป็นมา ไม่มีมนุษย์คนใดสามารถแยกวิเคราะห์ข้อมูลจำนวนมหาศาลดังกล่าวได้ ซึ่งจะนำไปสู่รากฐานของการเรียนรู้เชิงลึก
สามประเด็นหลักเกี่ยวกับข้อมูล
ปริมาณไม่ใช่ปัญหาเดียวเมื่อคุณกำลังรวบรวมข้อมูลสำหรับโครงการ AI ที่ทันสมัยของคุณ ไม่ว่าคุณจะมีข้อมูลมากแค่ไหน คุณภาพ ความสะอาด และความหลากหลายของข้อมูลก็มีความสำคัญไม่แพ้กัน หากคุณต้องการผลลัพธ์ที่ดีที่สุดจากอัลกอริทึมของคุณ
ก) ปริมาณ
หากคุณกำลังพยายามสร้างอัลกอริทึมสำหรับรถยนต์ขับเคลื่อนอัตโนมัติที่มีข้อมูลเพียงไม่กี่พันแถว คุณจะต้องเผชิญสิ่งกีดขวางบนถนน เพื่อให้แน่ใจว่าอัลกอริทึมของคุณให้ผลลัพธ์ที่เหมาะสมในสถานการณ์จริง คุณต้องฝึกอัลกอริทึมของคุณกับข้อมูลการฝึกอบรมจำนวนมาก ต้องขอบคุณความสามารถในการเข้าถึงบันทึกจากอุปกรณ์เกือบทุกชนิดในปัจจุบัน พร้อมกับกระแสข้อมูลจากเว็บที่แทบจะไม่มีที่สิ้นสุด การรวบรวมข้อมูลจึงไม่ใช่เรื่องยาก ตราบใดที่คุณมีเครื่องมือที่เหมาะสมและรู้วิธีใช้งาน
ข) ความหลากหลาย
เมื่อคุณกำลังฝึกอัลกอริทึมของคุณเพื่อจัดการกับปัญหาในโลกแห่งความเป็นจริงโดยใช้ AI ระบบของคุณต้องเข้าใจจุดข้อมูลที่หลากหลายที่เป็นไปได้ทั้งหมด หากคุณไม่สามารถรับข้อมูลได้หลากหลาย ระบบของคุณจะมีอคติโดยธรรมชาติและให้ผลลัพธ์ที่ไม่ถูกต้อง
เหตุการณ์ดังกล่าวเกิดขึ้นหลายครั้ง รวมถึงการ สำรวจความคิดเห็นของประธานาธิบดีที่มีชื่อเสียงในปี 1936 ซึ่งจัดโดย The Literary Digest ใน สหรัฐอเมริกา ผู้สมัครที่คาดการณ์ไว้จะชนะการแข่งขันชิงตำแหน่งประธานาธิบดี ซึ่งท้ายที่สุดแล้วแพ้ด้วยอัตรากำไรขั้นต้นที่มากกว่า 20% อย่างไรก็ตาม นิตยสารดังกล่าวได้สำรวจความคิดเห็นของผู้คน 10 ล้านคน โดยในจำนวนนี้มีผู้ตอบแบบสอบถาม 2.27 ล้านคน ซึ่ง เป็นตัวเลขทางดาราศาสตร์แม้แต่ตามมาตรฐานในปัจจุบัน มีอะไรผิดพลาดไปบ้าง?
พวกเขาล้มเหลวที่จะเข้าใจความรู้สึกของผู้อ่านส่วนใหญ่ที่ไม่ตอบสนองพร้อมกับผู้ที่ไม่สามารถสมัครรับนิตยสารเมื่อประเทศอยู่ในภาวะเศรษฐกิจตกต่ำครั้งใหญ่

ค). คุณภาพ
แม้ว่าปัจจัยสองประการสุดท้ายจะมีความสำคัญจริงๆ และสามารถตรวจสอบได้ด้วยความพยายามบางอย่าง แต่คุณภาพของข้อมูลนั้นง่ายกว่าที่จะพลาดและตรวจจับได้ยาก แม้ว่าผลลัพธ์ของคุณจะไม่ตรงกันก็ตาม วิธีเดียวที่คุณจะรู้ได้ว่าข้อมูลนั้นไม่สะอาดคือถ้าคุณวิเคราะห์ข้อมูลอีกครั้งหลังจากที่ได้เข้าสู่ขั้นตอนการผลิตแล้ว
วิธีง่ายๆ ในการรักษาคุณภาพของข้อมูลคือการลบข้อมูลที่ซ้ำกัน ตรวจสอบสคีมาของแต่ละแถวที่เข้ามา มีขีดจำกัดที่แน่นอนเพื่อตรวจสอบค่าที่ป้อนแต่ละแถว และติดตามค่าผิดปกติ หากปัจจัยบางอย่างไม่สามารถตรวจสอบได้ผ่านระบบอัตโนมัติ อาจจำเป็นต้องมีการแทรกแซงด้วยตนเอง จุดสำคัญที่ข้อผิดพลาดอาจเกิดขึ้นได้คือ การแปลง ข้อมูล โดยเฉพาะอย่างยิ่งเมื่อคุณกำลังรวบรวมข้อมูลจากหลายแหล่ง ไม่ใช่ทุกจุดข้อมูลจะมีหน่วยเดียวกัน การแปลงค่าโดยใช้สมการที่เหมาะสมนั้นเป็นสิ่งที่จำเป็น และจำเป็นต้องนำไปใช้ทั่วทั้งกระดาน
ข้อมูลที่คัดลอกมาจากเว็บอาจประกอบด้วยข้อมูลที่มี โครงสร้าง กึ่งมีโครงสร้าง และไม่มีโครงสร้าง และเมื่อคุณต้องการใช้ข้อมูลรูปแบบต่างๆ เหล่านี้ในโครงการ AI ของคุณ คุณจะต้องแน่ใจว่าคุณแปลงข้อมูลทั้งหมดเป็น รูปแบบเดียวกัน
คุณภาพข้อมูลส่งผลต่อโครงการ AI อย่างไร
คุณภาพของข้อมูลอาจส่งผลต่อการเรียนรู้ของเครื่องหรือโครงการ AI ขึ้นอยู่กับขนาดของโครงการ ข้อผิดพลาดง่ายๆ ในข้อมูลอาจนำไปสู่ผลลัพธ์ที่หายไปในระยะไกล ในกรณีที่คุณกำลังสร้างเอ็นจิ้นการแนะนำ และข้อมูลการฝึกของคุณไม่สะอาดเพียงพอ คำแนะนำจะไม่สมเหตุสมผลสำหรับผู้ใช้มากนัก
อย่างไรก็ตาม การพิจารณาว่าข้อมูลที่ไม่สะอาดมีส่วนในผลลัพธ์นี้อาจเป็นเรื่องยากหรือไม่ ในทำนองเดียวกัน หากคุณกำลังออกแบบอัลกอริธึมการทำนายและข้อมูลมีข้อบกพร่อง การคาดคะเนบางอย่างอาจยังดีอยู่ในขณะที่บางส่วนอาจผิดไปเล็กน้อย การเชื่อมต่อจุดต่าง ๆ เพื่อทำความเข้าใจความแตกต่างที่ข้อมูลสกปรกนำมาอาจเป็นเรื่องยากมากที่จะสร้างใหม่
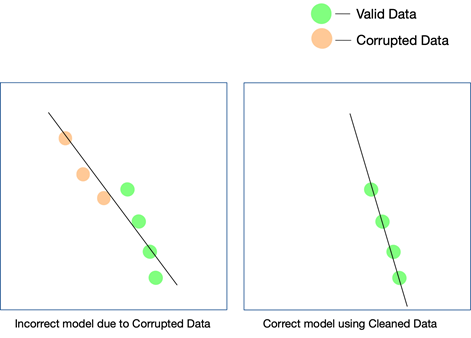
ทุกโครงการ AI เติบโตเป็นระยะ มีการตัดสินใจอัลกอริทึมเบื้องต้น ซึ่ง เป็นอัลกอริทึมที่ทำงานได้ดีที่สุดเมื่อพิจารณาจากชุดข้อมูลและกรณีการใช้งานเฉพาะจะถูกตัดสินใจ หากข้อมูลของคุณมีความไม่สอดคล้องกัน ตัวเลือกอัลกอริทึมของคุณอาจต้องหยุดชะงัก และคุณอาจไม่ได้ตระหนักถึงความเข้าใจผิดนี้อีกนานหลังจากนั้น
วิธีเดียวที่จะทำให้แน่ใจว่าแบบจำลองของคุณใช้งานได้จริงคือต้องแน่ใจว่ามีการป้อนข้อมูลที่สะอาดเข้าสู่ระบบ AI และทดสอบกับข้อมูลมากขึ้นเรื่อยๆ คุณยังสามารถใช้การเรียนรู้เสริมเพื่อแก้ไขเส้นทางของโมเดลเมื่อหลงทาง
Web Scraping สามารถแก้ปัญหาได้หรือไม่?
การขูดเว็บอาจเป็นวิธีแก้ปัญหา แต่ถ้าใช้ร่วมกับเครื่องมืออื่นๆ เพื่อให้แน่ใจว่าข้อมูลที่หลากหลายและปริมาณที่มาจากไปป์ไลน์ได้รับการทำความสะอาด ตรวจสอบ และตรวจสอบอย่างถี่ถ้วนก่อนนำไปใช้ในโปรเจ็กต์ แม้ว่าคุณจะใช้ เครื่องมือขูดเว็บ ไม่ว่าจะเป็นภายในองค์กรหรือซอฟต์แวร์แบบชำระเงิน เพื่อรับข้อมูลจากเว็บ ไม่น่าเป็นไปได้ที่เครื่องมือนี้จะสามารถทำงานหลังการประมวลผลเหล่านี้กับข้อมูลเพื่อให้พร้อม ใช้.
สิ่งที่คุณต้องการคือระบบแบบครบวงจรที่ดูแลการขูดข้อมูล ล้างข้อมูล ตรวจสอบความถูกต้อง และยืนยันข้อมูล เพื่อให้ผลลัพธ์สุดท้ายสามารถรวมเข้ากับเวิร์กโฟลว์ทางธุรกิจได้โดยตรงในรูปแบบพลักแอนด์เพลย์ การสร้างระบบดังกล่าวตั้งแต่เริ่มต้นนั้นยากพอๆ กับการปีนเขาโดยเริ่มจากฐาน
ทีมงานของเราที่ PromptCloud ให้บริการขูดเว็บ นั่นคือคุณให้ข้อกำหนดแก่เรา และเราให้ข้อมูลแก่คุณ เช่น โมเดล DaaS (Data-as-a-Service) สิ่งที่คุณต้องทำคือเข้าถึงข้อมูล (ซึ่งจะอยู่ในรูปแบบและสื่อจัดเก็บข้อมูลที่คุณเลือก) และรวมเข้ากับระบบปัจจุบันของคุณ เราไม่เพียงแต่ขูดข้อมูลจากหลาย ๆ เว็บไซต์แต่ใช้การตรวจสอบหลายครั้งในระดับต่างๆ เพื่อให้แน่ใจว่าข้อมูลที่เราให้นั้นสะอาด ข้อมูลนี้ช่วยให้ลูกค้าของเราในภาคส่วนต่างๆ ใช้เทคโนโลยีที่ทันสมัย เช่น AI และการเรียนรู้ของเครื่อง เพื่อทำให้กระบวนการต่างๆ มีความคล่องตัวและเข้าใจลูกค้าได้ดีขึ้น