
A ausência de dados de qualidade está limitando o crescimento da IA?
Publicados: 2020-12-23O futuro da IA está nas mãos dos dados de qualidade
Soa um pouco absurdo não é? O futuro não deveria estar nas mãos do homem? Mas se você observar o crescimento do Machine Learning e da Inteligência Artificial, poderá perceber que as últimas inovações pegaram carona na enorme quantidade de dados que são gerados por humanos e máquinas hoje. O crescimento das redes neurais e algoritmos de aprendizado profundo que estão sendo usados nas últimas inovações, como carros autônomos e processamento de linguagem natural, só foi possível devido ao crescimento da quantidade e qualidade dos dados. Quando você tem menos dados, quase todos os algoritmos de IA produzem resultados semelhantes, mas quando você tem petabytes de dados, você pode ver os algoritmos de aprendizado profundo brilharem.
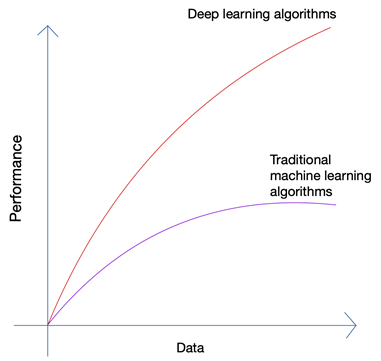
Os seres humanos só podem produzir uma quantidade limitada de dados, e a revolução do big data foi causada principalmente devido a cada vez mais dispositivos se conectando à Internet e produzindo mais dados. A revolução da IoT produziu mais dados do que nunca. Nenhum humano pode analisar dados tão enormes, que por sua vez levaram às bases do aprendizado profundo.
Os três principais problemas com dados
A quantidade não é o único problema quando você está coletando dados para seu projeto de IA de ponta. Não importa quantos dados você tenha, a qualidade, a limpeza e a variedade dos dados importam tanto se você deseja os melhores resultados do seu algoritmo.
uma). Quantidade
Se você está tentando criar um algoritmo para carros autônomos com apenas alguns milhares de linhas de dados, você enfrentará obstáculos. Para garantir que seu algoritmo produza resultados adequados em cenários do mundo real, você precisa treinar seu algoritmo em toneladas e toneladas de dados de treinamento. Graças à capacidade de acessar logs de quase qualquer dispositivo hoje, juntamente com o fluxo quase infinito de dados da Web, a coleta de dados não é muito difícil; contanto que você tenha as ferramentas certas e saiba como usá-las.
b). Variedade
Quando você está treinando seus algoritmos para resolver problemas do mundo real usando IA, seu sistema precisa entender toda a variedade possível de pontos de dados possíveis. Se você não conseguir obter uma variedade de dados, seu sistema terá um viés inerente e produzirá resultados incorretos.
Isso já aconteceu várias vezes, incluindo a famosa Pesquisa Presidencial de 1936 realizada pela The Literary Digest nos EUA . O candidato que havia previsto venceria a corrida presidencial, mas acabou perdendo por uma margem maciça de mais de 20%. No entanto, a revista entrevistou 10 milhões de pessoas, das quais 2,27 milhões responderam – um número astronômico mesmo para os padrões de hoje. Onde as coisas deram errado?
Bem, eles não conseguiram entender os sentimentos de uma porcentagem muito maior de leitores que simplesmente não respondeu junto com aqueles que não podiam pagar para assinar uma revista quando o país estava nas profundezas de uma grande depressão.
c). Qualidade
Embora os dois últimos fatores sejam realmente importantes e possam ser verificados com alguns esforços, a qualidade dos dados é mais fácil de perder e difícil de detectar, mesmo quando seus resultados não coincidem. A única maneira de saber se os dados estavam sujos é analisando os dados novamente depois de entrarem em produção.

Algumas maneiras simples de manter a qualidade dos dados é remover duplicatas, validar o esquema de cada linha que entra, ter certos limites rígidos para manter uma verificação dos valores que entram em cada linha e também acompanhar os valores discrepantes. Se certos fatores não puderem ser controlados via automação, intervenções manuais também podem ser necessárias. Um ponto importante onde os erros podem surgir são as conversões de dados . Especialmente quando você está acumulando dados de várias fontes, nem todos os pontos de dados teriam as mesmas unidades. Converter os valores usando as equações adequadas é uma obrigação e precisa ser implementada em toda a linha.
Os dados extraídos da Web também podem consistir em dados estruturados, semiestruturados e não estruturados , e quando você quiser usar essas diferentes formas de dados em seu projeto de IA, precisará converter todos eles em o mesmo formato.
Como a qualidade dos dados afeta os projetos de IA?
A qualidade dos dados pode afetar qualquer projeto de aprendizado de máquina ou IA. Dependendo da extensão do projeto, até mesmo erros simples nos dados podem levar a resultados que estão longe de acontecer. Caso você esteja criando um mecanismo de recomendação e seus dados de treinamento não estejam limpos o suficiente, as recomendações não farão muito sentido para os usuários.
No entanto, saber se os dados impuros desempenharam um papel nesse resultado pode ser difícil. Da mesma forma, se você estiver projetando um algoritmo de previsão e os dados tiverem certas falhas, algumas previsões ainda podem ser válidas, enquanto outras podem estar um pouco erradas. Conectar os pontos para perceber a diferença que os dados sujos trouxeram pode ser extremamente difícil de recriar.
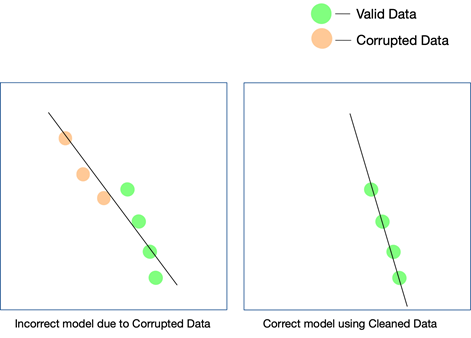
Todo projeto de IA cresce em fases. Uma decisão algorítmica inicial é tomada – ou seja, qual algoritmo funcionaria melhor, dado o conjunto de dados e o caso de uso específico, é decidido. Se seus dados tiverem inconsistências, sua escolha do algoritmo em si pode ser um lance, e você pode não perceber essa falácia até muito tempo depois.
A única maneira de garantir que seu modelo funcione no mundo real é garantir que dados limpos sejam fornecidos ao sistema de IA e continuar testando-os em mais e mais dados. Você também pode usar o aprendizado reforçado para corrigir o caminho do modelo quando ele se desviar.
O Web Scraping pode ser a solução?
O web scraping pode ser uma solução, mas somente se for usado em combinação com várias outras ferramentas para garantir que a variedade e a quantidade de dados que passam pelo pipeline sejam completamente limpas, verificadas e validadas antes de serem usadas em um projeto. Mesmo se você estiver usando uma ferramenta de raspagem da web , seja ela interna ou um software pago, para obter dados da web, é improvável que a ferramenta consiga realizar essas tarefas de pós-processamento nos dados para prepará-los usar.
O que você precisará é de um sistema de ponta a ponta que cuide de raspar os dados, limpá-los, validá-los e verificá-los, de modo que a saída final possa ser integrada diretamente aos fluxos de trabalho de negócios em um formato plug and play. Construir um sistema desse tipo do zero é tão difícil quanto escalar a montanha a partir de sua base.
Nossa equipe na PromptCloud fornece serviço de web scraping – ou seja, você nos fornece os requisitos e nós fornecemos os dados, o modelo DaaS (Data-as-a-Service). Basta acessar os dados (que estarão no formato e meio de armazenamento de sua preferência) e integrá-los ao seu sistema atual. Não apenas coletamos os dados de vários sites, mas também usamos várias verificações em vários níveis para garantir que os dados que fornecemos estejam limpos. Esses dados ajudam a capacitar nossos clientes em vários setores a usar tecnologias de ponta, como IA e aprendizado de máquina, para simplificar diferentes processos e entender melhor seus clientes.