
Ограничивает ли отсутствие качественных данных рост ИИ?
Опубликовано: 2020-12-23Будущее ИИ — в руках качественных данных
Звучит немного абсурдно, не так ли? Разве будущее не должно быть в руках человека? Но если вы посмотрите на рост машинного обучения и искусственного интеллекта, вы сможете заметить, что последние инновации основаны на огромном количестве данных, которые сегодня генерируются людьми и машинами. Рост нейронных сетей и алгоритмов глубокого обучения, которые используются в последних инновациях, таких как самоуправляемые автомобили и обработка естественного языка, стал возможен только благодаря росту количества и качества данных. Когда у вас меньше данных, почти все алгоритмы ИИ дают одинаковые результаты, но когда у вас есть петабайты данных, вы можете увидеть сияние алгоритмов глубокого обучения.
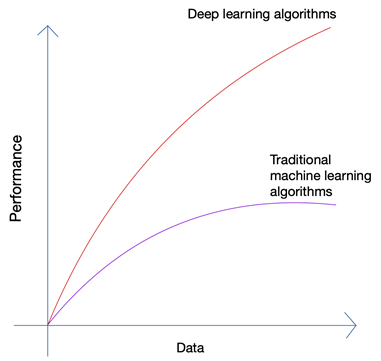
Люди могут производить только ограниченное количество данных, и революция больших данных была вызвана главным образом тем, что все больше и больше устройств подключаются к Интернету и производят больше данных. Революция IoT произвела больше данных, чем когда-либо прежде. Ни один человек не может проанализировать такие огромные данные, что, в свою очередь, привело к основам глубокого обучения.
Три основные проблемы с данными
Количество — не единственная проблема, когда вы собираете данные для своего передового проекта ИИ. Независимо от того, сколько у вас данных, качество, чистота и разнообразие данных имеют не меньшее значение, если вы хотите получить наилучшие результаты от своего алгоритма.
а). Количество
Если вы пытаетесь создать алгоритм для автономных автомобилей всего с несколькими тысячами строк данных, вы обязательно столкнетесь с препятствиями. Чтобы убедиться, что ваш алгоритм дает правильные результаты в реальных сценариях, вам нужно обучить свой алгоритм на множестве и множестве обучающих данных. Благодаря возможности доступа к журналам практически с любого устройства сегодня, а также почти бесконечному потоку данных из Интернета, сбор данных не представляет большой сложности; пока у вас есть нужные инструменты и вы знаете, как их использовать.
б). Разнообразие
Когда вы обучаете свои алгоритмы решению реальных проблем с помощью ИИ, ваша система должна понимать все возможное разнообразие возможных точек данных. Если вы не можете получить разнообразные данные, ваша система будет иметь врожденную предвзятость и будет давать неверные результаты.
Такое случалось несколько раз, включая знаменитый президентский опрос 1936 года, проведенный The Literary Digest в США . Кандидат, которого он предсказывал, выиграет президентскую гонку, но в конечном итоге проиграл с огромным отрывом более чем на 20%. Однако журнал опросил 10 миллионов человек, из которых ответили 2,27 миллиона — астрономическое число даже по сегодняшним меркам. Где что-то пошло не так?
Что ж, они не смогли понять настроения гораздо большего процента читателей, которые просто не ответили, а также тех, кто не мог позволить себе подписаться на журнал, когда страна находилась в гуще великой депрессии.
в). Качественный
В то время как последние два фактора действительно важны и их можно контролировать, приложив некоторые усилия, качество данных легче не заметить и трудно обнаружить, даже если ваши результаты не совпадают. Единственный способ узнать, что данные были нечистыми, — это снова проанализировать данные после того, как они были запущены в производство.

Некоторые простые способы поддержания качества данных — это удаление дубликатов, проверка схемы каждой входящей строки, установление определенных жестких ограничений для проверки значений, входящих в каждую строку, а также отслеживание выбросов. Если определенные факторы нельзя контролировать с помощью автоматизации, может потребоваться ручное вмешательство. Основным моментом, в котором могут возникнуть ошибки, является преобразование данных . Особенно, когда вы накапливаете данные из нескольких источников, не все точки данных будут иметь одинаковые единицы измерения. Преобразование значений с использованием правильных уравнений является обязательным и должно быть реализовано повсеместно.
Данные, извлеченные из Интернета, также могут состоять из структурированных, частично структурированных и неструктурированных данных . тот же формат.
Как качество данных влияет на проекты ИИ?
Качество данных может повлиять на любой проект машинного обучения или искусственного интеллекта. В зависимости от того, насколько велик проект, даже простые ошибки в данных могут привести к далеко не верным результатам. Если вы создаете механизм рекомендаций, а ваши обучающие данные недостаточно чистые, рекомендации не будут иметь особого смысла для пользователей.
Однако выяснить, сыграли ли нечистые данные какую-то роль в этом исходе, может быть сложно. Точно так же, если вы разрабатываете алгоритм прогнозирования, а данные имеют определенные недостатки, некоторые прогнозы могут все еще быть верными, а некоторые могут быть немного ошибочными. Соединить точки, чтобы понять разницу, которую принесли грязные данные, может быть чрезвычайно сложно воссоздать.
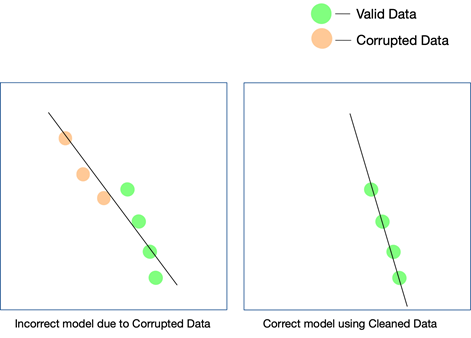
Каждый проект ИИ развивается поэтапно. Принимается начальное алгоритмическое решение — то есть решается, какой алгоритм будет работать лучше всего с учетом набора данных и конкретного варианта использования. Если в ваших данных есть несоответствия, ваш выбор самого алгоритма может оказаться неудачным, и вы можете не осознавать эту ошибку до тех пор, пока не осознаете эту ошибку.
Единственный способ убедиться, что ваша модель работает в реальном мире, — обеспечить подачу чистых данных в систему ИИ и постоянно тестировать ее на все большем количестве данных. Вы также можете использовать усиленное обучение, чтобы исправить траекторию движения модели, когда она отклоняется.
Может ли веб-скрейпинг быть решением?
Веб-скрапинг может быть решением, но только в том случае, если он используется в сочетании с несколькими другими инструментами, чтобы убедиться, что разнообразие и количество данных, которые проходят через конвейер, тщательно очищаются, проверяются и проверяются перед использованием в проекте. Даже если вы используете инструмент веб-скрапинга , будь то собственное или платное программное обеспечение, для получения данных из Интернета, маловероятно, что инструмент сможет выполнять эти задачи постобработки данных, чтобы сделать их готовыми. использовать.
Вам понадобится комплексная система, которая позаботится об извлечении данных, их очистке, проверке и проверке, чтобы конечный результат можно было напрямую интегрировать в бизнес-процессы в формате plug and play. Построить такую систему с нуля так же сложно, как взобраться на гору, начиная с ее основания.
Наша команда в PromptCloud предоставляет услугу парсинга веб-страниц, то есть вы даете нам требования, а мы предоставляем вам данные, модель DaaS (данные как услуга). Все, что вам нужно сделать, это получить доступ к данным (которые будут в формате и на выбранном вами носителе) и интегрировать их в вашу текущую систему. Мы не только собираем данные с нескольких веб-сайтов, но и используем несколько проверок на разных уровнях, чтобы убедиться, что данные, которые мы предоставляем, чисты. Эти данные помогают нашим клиентам в различных секторах использовать передовые технологии, такие как искусственный интеллект и машинное обучение, для оптимизации различных процессов и лучшего понимания своих клиентов.