
¿La ausencia de datos de calidad limita el crecimiento de la IA?
Publicado: 2020-12-23El futuro de la IA está en manos de datos de calidad
Suena un poco absurdo, ¿no? ¿No debería estar el futuro en manos del hombre? Pero si observa el crecimiento del aprendizaje automático y la inteligencia artificial, podrá detectar que las últimas innovaciones se han aprovechado de la enorme cantidad de datos que generan los humanos y las máquinas en la actualidad. El crecimiento de las redes neuronales y los algoritmos de aprendizaje profundo que se utilizan en las últimas innovaciones, como los automóviles autónomos y el procesamiento del lenguaje natural, solo ha sido posible gracias al crecimiento en la cantidad y calidad de los datos. Cuando tiene menos datos, casi todos los algoritmos de IA producen resultados similares, pero cuando tiene petabytes de datos, puede ver brillar los algoritmos de aprendizaje profundo.
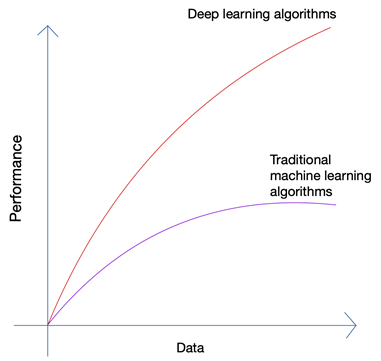
Los seres humanos solo pueden producir una cantidad limitada de datos, y la revolución de los grandes datos se debió principalmente a que cada vez más dispositivos se conectan a Internet y producen más datos. La revolución de IoT ha producido más datos que nunca. Ningún ser humano puede analizar datos tan enormes, lo que a su vez condujo a los cimientos del aprendizaje profundo.
Los tres problemas principales con los datos
La cantidad no es el único problema cuando recopila datos para su proyecto de inteligencia artificial de vanguardia. No importa cuántos datos tenga, la calidad, la limpieza y la variedad de los datos son igualmente importantes si desea obtener los mejores resultados de su algoritmo.
a). Cantidad
Si está tratando de crear un algoritmo para automóviles autónomos con solo unas pocas miles de filas de datos, seguramente se enfrentará a obstáculos. Para asegurarse de que su algoritmo produzca resultados adecuados en escenarios del mundo real, necesita entrenar su algoritmo en toneladas y toneladas de datos de entrenamiento. Gracias a la capacidad de acceder a los registros desde casi cualquier dispositivo hoy en día junto con el flujo casi infinito de datos de la web, la recopilación de datos no es muy difícil; siempre que tenga las herramientas adecuadas y sepa cómo usarlas.
b). Variedad
Cuando está entrenando sus algoritmos para abordar problemas del mundo real utilizando IA, su sistema necesita comprender toda la variedad posible de puntos de datos posibles. Si no puede obtener una variedad de datos, su sistema tendrá un sesgo inherente y producirá resultados incorrectos.
Esto ha sucedido varias veces, incluida la famosa encuesta presidencial de 1936 realizada por The Literary Digest en los EE . UU . El candidato que había pronosticado ganaría la carrera presidencial, finalmente perdió por un margen masivo de más del 20%. Sin embargo, la revista había encuestado a 10 millones de personas, de las cuales respondieron 2,27 millones , una cifra astronómica incluso para los estándares actuales. ¿Dónde habían salido mal las cosas?
Bueno, no habían logrado comprender los sentimientos del porcentaje mucho mayor de lectores que simplemente no respondieron junto con aquellos que no podían suscribirse a una revista cuando el país estaba en las profundidades de una gran depresión.
C). Calidad
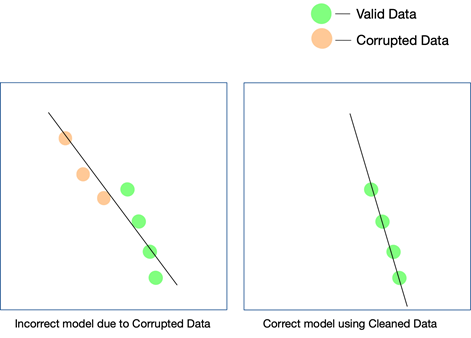
Si bien los dos últimos factores son realmente importantes y se pueden controlar con algunos esfuerzos, la calidad de los datos es más fácil de pasar por alto y difícil de detectar incluso cuando los resultados no coinciden. La única forma en que puede saber que los datos no estaban limpios es si los analiza nuevamente después de que hayan entrado en producción.

Algunas formas simples de mantener la calidad de los datos son eliminar duplicados, validar el esquema de cada fila que ingresa, tener ciertos límites estrictos para controlar los valores que ingresan en cada fila y también realizar un seguimiento de los valores atípicos. Si ciertos factores no pueden controlarse mediante la automatización, también pueden ser necesarias intervenciones manuales. Un punto importante en el que pueden aparecer errores es en las conversiones de datos . Especialmente cuando está acumulando datos de múltiples fuentes, no todos los puntos de datos tendrán las mismas unidades. Convertir los valores utilizando las ecuaciones adecuadas es imprescindible y debe implementarse en todos los ámbitos.
Los datos que se extraen de la web también pueden consistir en datos estructurados, semiestructurados y no estructurados , y cuando desee utilizar estas diferentes formas de datos en su proyecto de IA, deberá asegurarse de convertirlos todos a el mismo formato.
¿Cómo afecta la calidad de los datos a los proyectos de IA?
La calidad de los datos puede afectar cualquier proyecto de aprendizaje automático o IA. Dependiendo de qué tan vasto sea el proyecto, incluso los errores más simples en los datos pueden llevar a resultados que están fuera de lugar. En caso de que esté creando un motor de recomendaciones y sus datos de entrenamiento no estén lo suficientemente limpios, las recomendaciones no tendrán mucho sentido para los usuarios.
Sin embargo, puede ser difícil determinar si los datos no limpios han jugado un papel en este resultado. Del mismo modo, si está diseñando un algoritmo de predicción y los datos tienen ciertas fallas, algunas predicciones pueden seguir siendo buenas, mientras que otras pueden estar un poco equivocadas. Conectar los puntos para darse cuenta de la diferencia que han traído los datos sucios puede ser extremadamente difícil de recrear.
Cada proyecto de IA crece en fases. Se toma una decisión algorítmica inicial : se decide qué algoritmo funcionaría mejor dado el conjunto de datos y el caso de uso específico. Si sus datos tienen inconsistencias, su elección del algoritmo en sí puede fallar, y es posible que no se dé cuenta de esta falacia hasta mucho después.
La única forma de asegurarse de que su modelo funcione en el mundo real es asegurarse de que se alimenten datos limpios al sistema de IA y seguir probándolo con más y más datos. También puede utilizar el aprendizaje reforzado para corregir el camino del modelo cuando se desvía.
¿Puede Web Scraping ser la solución?
El web scraping puede ser una solución, pero solo si se usa en combinación con varias otras herramientas para garantizar que la variedad y la cantidad de datos que llegan a través de la tubería se limpien, verifiquen y validen a fondo antes de usarse en un proyecto. Incluso si está utilizando una herramienta de raspado web , ya sea interna o de pago, para obtener datos de la web, es poco probable que la herramienta pueda realizar estas tareas de posprocesamiento en los datos para que estén listos. usar.
Lo que necesitará es un sistema de extremo a extremo que se encargue de extraer los datos, limpiarlos, validarlos y verificarlos, de modo que el resultado final pueda integrarse directamente en los flujos de trabajo comerciales en un formato plug and play. Construir un sistema de este tipo desde cero es tan difícil como escalar la montaña desde su base.
Nuestro equipo en PromptCloud brinda un servicio de web scraping, es decir, usted nos brinda los requisitos y nosotros le brindamos los datos, el modelo DaaS (Data-as-a-Service). Todo lo que necesita hacer es acceder a los datos (que estarán en el formato y medio de almacenamiento de su elección) e integrarlos con su sistema actual. No solo extraemos los datos de varios sitios web, sino que utilizamos múltiples controles en varios niveles para asegurarnos de que los datos que proporcionamos estén limpios. Estos datos ayudan a capacitar a nuestros clientes en varios sectores para que utilicen tecnologías de vanguardia como IA y aprendizaje automático para optimizar diferentes procesos y comprender mejor a sus clientes.