
Czy brak wysokiej jakości danych ogranicza rozwój sztucznej inteligencji?
Opublikowany: 2020-12-23Przyszłość sztucznej inteligencji leży w rękach wysokiej jakości danych
Brzmi trochę absurdalnie, prawda? Czy przyszłość nie powinna leżeć w rękach człowieka? Ale jeśli przyjrzysz się rozwojowi uczenia maszynowego i sztucznej inteligencji, zauważysz, że najnowsze innowacje wykorzystały ogromną ilość danych, które są obecnie generowane przez ludzi i maszyny. Rozwój sieci neuronowych i algorytmów głębokiego uczenia, które są wykorzystywane w najnowszych innowacjach, takich jak autonomiczne samochody i przetwarzanie języka naturalnego, był możliwy tylko dzięki wzrostowi ilości i jakości danych. Gdy masz mniej danych, prawie wszystkie algorytmy sztucznej inteligencji dają podobne wyniki, ale gdy masz petabajty danych, możesz zobaczyć, jak świecą algorytmy głębokiego uczenia.
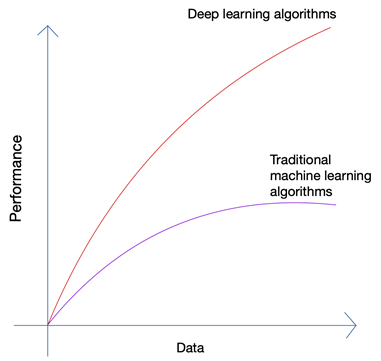
Ludzie mogą wytwarzać tylko ograniczoną ilość danych, a rewolucja big data została spowodowana głównie przez coraz większą liczbę urządzeń łączących się z Internetem i wytwarzających więcej danych. Rewolucja IoT wygenerowała więcej danych niż kiedykolwiek wcześniej. Żaden człowiek nie może przeanalizować tak ogromnych danych, co z kolei doprowadziło do powstania podstaw głębokiego uczenia się.
Trzy główne problemy z danymi
Ilość nie jest jedynym problemem, gdy zbierasz dane do swojego nowatorskiego projektu AI. Bez względu na to, ile masz danych, jakość, czystość i różnorodność danych mają takie samo znaczenie, jeśli chcesz uzyskać najlepsze wyniki swojego algorytmu.
a). Ilość
Jeśli próbujesz stworzyć algorytm dla autonomicznych samochodów z zaledwie kilkoma tysiącami wierszy danych, na pewno napotkasz przeszkody. Aby upewnić się, że twój algorytm daje prawidłowe wyniki w rzeczywistych scenariuszach, musisz wytrenować swój algorytm na tonach danych treningowych. Dzięki możliwości dostępu do logów z niemal każdego urządzenia w dzisiejszych czasach wraz z niemal nieskończonym strumieniem danych z sieci, zbieranie danych nie jest bardzo trudne; o ile masz odpowiednie narzędzia i wiesz, jak z nich korzystać.
b). Różnorodność
Kiedy szkolisz swoje algorytmy, aby rozwiązywać rzeczywiste problemy za pomocą sztucznej inteligencji, twój system musi zrozumieć całą możliwą różnorodność możliwych punktów danych. Jeśli nie jesteś w stanie uzyskać różnych danych, Twój system będzie miał wrodzoną stronniczość i da nieprawidłowe wyniki.
Zdarzyło się to wielokrotnie, m.in. w słynnym plebiscycie prezydenckim z 1936 r. przeprowadzonym przez The Literary Digest w USA . Kandydat, którego przewidywała, wygra wyścig prezydencki, ostatecznie przegrany z ogromną przewagą ponad 20%. Jednak magazyn przepytał 10 milionów osób, z czego 2,27 miliona odpowiedziało – to astronomiczna liczba nawet jak na dzisiejsze standardy. Gdzie coś poszło nie tak?
Cóż, nie zrozumieli nastrojów znacznie większego odsetka czytelników, którzy po prostu nie reagowali, podobnie jak tych, których nie było stać na prenumeratę czasopisma, gdy kraj był pogrążony w wielkiej depresji.
c). Jakość
Chociaż dwa ostatnie czynniki są naprawdę ważne i można je kontrolować przy pewnym wysiłku, jakość danych jest łatwiejsza do przeoczenia i trudna do wykrycia, nawet jeśli wyniki nie są zgodne. Jedynym sposobem, aby dowiedzieć się, że dane były nieczyste, jest ponowne przeanalizowanie danych po ich wprowadzeniu do produkcji.

Niektóre proste sposoby na utrzymanie jakości danych to usuwanie duplikatów, weryfikowanie schematu każdego przychodzącego wiersza, ustalanie pewnych sztywnych limitów, aby kontrolować wartości wprowadzane do każdego wiersza, a także śledzenie wartości odstających. Jeśli pewnych czynników nie można kontrolować za pomocą automatyzacji, konieczne mogą być również ręczne interwencje. Głównym punktem, w którym mogą pojawić się błędy, jest konwersja danych . Zwłaszcza, gdy gromadzisz dane z wielu źródeł, nie wszystkie punkty danych będą miały te same jednostki. Konwersja wartości za pomocą odpowiednich równań jest koniecznością i musi być wdrożona we wszystkich obszarach.
Dane pobierane z sieci mogą również składać się z danych ustrukturyzowanych, częściowo ustrukturyzowanych i nieustrukturyzowanych , a jeśli chcesz użyć tych różnych form danych w swoim projekcie AI, musisz upewnić się, że przekonwertujesz je wszystkie na ten sam format.
Jak jakość danych wpływa na projekty AI?
Jakość danych może mieć wpływ na każdy projekt związany z uczeniem maszynowym lub sztuczną inteligencją. W zależności od tego, jak rozległy jest projekt, nawet proste błędy w danych mogą prowadzić do wyników, które są dalekie od wyników. Jeśli tworzysz silnik rekomendacji, a Twoje dane treningowe nie są wystarczająco czyste, rekomendacje nie będą miały sensu dla użytkowników.
Jednak ustalenie, czy nieczyste dane odegrały rolę w tym wyniku, może być trudne. Podobnie, jeśli projektujesz algorytm przewidywania, a dane mają pewne wady, niektóre prognozy mogą nadal się sprawdzać, a niektóre mogą być nieco nietrafione. Łączenie kropek w celu uświadomienia sobie różnicy, jaką przyniosły brudne dane, może być niezwykle trudne do odtworzenia.
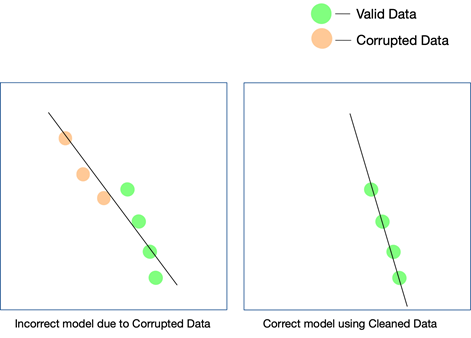
Każdy projekt AI rozwija się etapami. Podejmowana jest wstępna decyzja algorytmiczna — to znaczy, który algorytm będzie działał najlepiej, biorąc pod uwagę zbiór danych i konkretny przypadek użycia. Jeśli twoje dane są niespójne, twój wybór samego algorytmu może być chybiony i możesz nie zdać sobie sprawy z tego błędu dopiero długo po tym.
Jedynym sposobem, aby upewnić się, że Twój model działa w świecie rzeczywistym, jest dostarczanie czystych danych do systemu AI i ciągłe testowanie ich na coraz większej ilości danych. Możesz również użyć wzmocnionego uczenia się, aby skorygować ścieżkę modelu, gdy się oddala.
Czy czyszczenie sieci może być rozwiązaniem?
Web scraping może być rozwiązaniem, ale tylko wtedy, gdy jest używany w połączeniu z kilkoma innymi narzędziami, aby upewnić się, że różnorodność i ilość danych, które przechodzą przez rurociąg, są dokładnie oczyszczone, zweryfikowane i zweryfikowane przed użyciem w projekcie. Nawet jeśli używasz narzędzia do skrobania stron internetowych , czy to wewnętrznego, czy płatnego oprogramowania, do pobierania danych z sieci, jest mało prawdopodobne, że narzędzie będzie w stanie wykonać te zadania przetwarzania końcowego na danych, aby były gotowe używać.
Potrzebny będzie kompleksowy system, który zajmie się zeskrobywaniem danych, czyszczeniem ich, weryfikowaniem i weryfikacją, tak aby końcowy wynik mógł zostać bezpośrednio zintegrowany z przepływami pracy w biznesie w formacie plug and play. Zbudowanie takiego systemu od podstaw jest równie trudne, jak wejście na górę zaczynając od jej podstawy.
Nasz zespół w PromptCloud świadczy usługę web scrapingu – to znaczy Ty podajesz nam wymagania, a my dajemy Ci dane, model DaaS (Data-as-a-Service). Wszystko, co musisz zrobić, to uzyskać dostęp do danych (które będą w wybranym przez Ciebie formacie i nośniku danych) i zintegrować je z obecnym systemem. Nie tylko zbieramy dane z wielu witryn internetowych, ale przeprowadzamy wiele kontroli na różnych poziomach, aby upewnić się, że dostarczane przez nas dane są czyste. Dane te pomagają naszym klientom w różnych sektorach korzystać z najnowocześniejszych technologii, takich jak sztuczna inteligencja i uczenie maszynowe, aby usprawnić różne procesy i lepiej zrozumieć swoich klientów.