
L'assenza di dati di qualità limita la crescita dell'IA?
Pubblicato: 2020-12-23Il futuro dell'IA risiede nelle mani dei dati di qualità
Suona un po' assurdo no? Il futuro non dovrebbe essere nelle mani dell'uomo? Ma se osservi la crescita dell'apprendimento automatico e dell'intelligenza artificiale, sarai in grado di notare che le ultime innovazioni si sono basate sull'enorme quantità di dati che oggi vengono generati da esseri umani e macchine. La crescita delle reti neurali e degli algoritmi di deep learning utilizzati nelle ultime innovazioni come le auto a guida autonoma e l'elaborazione del linguaggio naturale è stata possibile solo grazie alla crescita della quantità e della qualità dei dati. Quando hai meno dati, quasi tutti gli algoritmi di intelligenza artificiale producono risultati simili, ma quando hai Petabyte di dati, puoi vedere brillare gli algoritmi di deep learning.
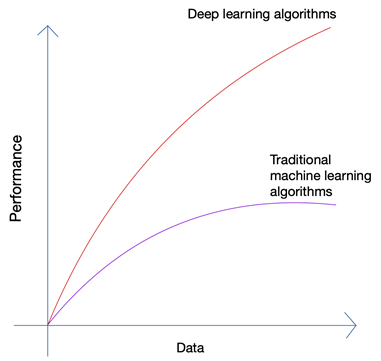
Gli esseri umani possono produrre solo una quantità limitata di dati e la rivoluzione dei big data è stata causata principalmente da un numero sempre maggiore di dispositivi che si connettono a Internet e producono più dati. La rivoluzione IoT ha prodotto più dati che mai. Nessun essere umano può analizzare dati così enormi, che a loro volta hanno portato alle basi del deep learning.
I tre problemi principali con i dati
La quantità non è l'unico problema quando stai raccogliendo dati per il tuo progetto di intelligenza artificiale all'avanguardia. Indipendentemente dalla quantità di dati che hai, la qualità, la pulizia e la varietà dei dati contano altrettanto se desideri i migliori risultati dal tuo algoritmo.
un). Quantità
Se stai cercando di creare un algoritmo per auto a guida autonoma con solo poche migliaia di righe di dati, sei destinato ad affrontare blocchi stradali. Per assicurarti che il tuo algoritmo produca risultati corretti in scenari del mondo reale, devi addestrare il tuo algoritmo su tonnellate e tonnellate di dati di addestramento. Grazie alla possibilità di accedere ai log da quasi tutti i dispositivi oggigiorno insieme al flusso quasi infinito di dati dal web, la raccolta dei dati non è molto difficile; purché tu abbia gli strumenti giusti e sai come usarli.
b). Varietà
Quando stai addestrando i tuoi algoritmi per affrontare i problemi del mondo reale utilizzando l'IA, il tuo sistema deve comprendere tutta la possibile varietà di punti dati possibili. Se non sei in grado di ottenere una varietà di dati, il tuo sistema avrà una distorsione intrinseca e produrrà risultati errati.
Tale è successo più volte, incluso il famoso sondaggio presidenziale del 1936 tenuto da The Literary Digest negli Stati Uniti . Il candidato che aveva previsto avrebbe vinto la corsa presidenziale, che alla fine ha perso con un enorme margine di oltre il 20%. Tuttavia, la rivista aveva intervistato 10 milioni di persone, di cui 2,27 milioni avevano risposto , un numero astronomico anche per gli standard odierni. Dove erano andate le cose storte?
Ebbene, non erano riusciti a capire i sentimenti della percentuale molto più ampia di lettori che semplicemente non rispondevano insieme a quelli che non potevano permettersi di abbonarsi a una rivista quando il paese era nel profondo di una grande depressione.
c). Qualità
Mentre gli ultimi due fattori sono davvero importanti e possono essere tenuti sotto controllo con alcuni sforzi, la qualità dei dati è più facile da perdere e difficile da rilevare anche quando i risultati non corrispondono. L'unico modo per sapere che i dati non erano puliti è se analizzi nuovamente i dati dopo che sono entrati in produzione.

Alcuni semplici modi per mantenere la qualità dei dati sono rimuovere i duplicati, convalidare lo schema di ogni riga che arriva, avere determinati limiti per mantenere un controllo sui valori che entrano in ogni riga e anche tenere traccia dei valori anomali. Se alcuni fattori non possono essere tenuti sotto controllo tramite l'automazione, possono essere necessari anche interventi manuali. Un punto importante in cui gli errori possono insinuarsi è la conversione dei dati . Soprattutto quando si accumulano dati da più fonti, non tutti i punti dati avrebbero le stesse unità. La conversione dei valori utilizzando le equazioni appropriate è un must e deve essere implementata su tutta la linea.
I dati che vengono prelevati dal Web possono anche essere costituiti da dati strutturati, semi-strutturati e non strutturati e , quando desideri utilizzare queste diverse forme di dati nel tuo progetto di intelligenza artificiale, dovrai assicurarti di convertirli tutti in lo stesso formato.
In che modo la qualità dei dati influisce sui progetti di intelligenza artificiale?
La qualità dei dati può influire su qualsiasi progetto di apprendimento automatico o intelligenza artificiale. A seconda della vastità del progetto, anche semplici errori nei dati possono portare a risultati di gran lunga lontani. Nel caso in cui si stia creando un motore di suggerimenti e i dati di allenamento non siano sufficientemente puliti, i consigli non avranno molto senso per gli utenti.
Tuttavia, potrebbe essere difficile capire se i dati sporchi hanno avuto un ruolo in questo risultato. Allo stesso modo, se stai progettando un algoritmo di previsione e i dati presentano alcuni difetti, alcune previsioni potrebbero comunque essere valide mentre altre potrebbero essere un po' storte. Collegare i punti per realizzare la differenza che i dati sporchi hanno portato può essere estremamente difficile da ricreare.
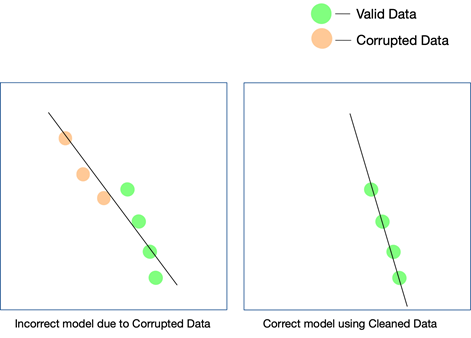
Ogni progetto di IA cresce per fasi. Viene presa una decisione algoritmica iniziale, ovvero quale algoritmo funzionerebbe meglio in base al set di dati e al caso d'uso specifico. Se i tuoi dati presentano incongruenze, la tua scelta dell'algoritmo stesso potrebbe essere oggetto di un lancio e potresti non renderti conto di questo errore se non molto tempo dopo.
L'unico modo per garantire che il tuo modello funzioni nel mondo reale è garantire che i dati puliti vengano inviati al sistema di intelligenza artificiale e continuare a testarlo su un numero sempre maggiore di dati. Puoi anche utilizzare l'apprendimento rinforzato per correggere il percorso del modello quando si allontana.
Il web scraping può essere la soluzione?
Il web scraping può essere una soluzione, ma solo se utilizzato in combinazione con molti altri strumenti per assicurarsi che la varietà e la quantità di dati che arrivano attraverso la pipeline siano accuratamente puliti, verificati e convalidati prima di essere utilizzati in un progetto. Anche se stai utilizzando uno strumento di scraping web , sia esso un software interno o a pagamento, per ottenere dati dal web, è improbabile che lo strumento sia in grado di eseguire queste attività di post-elaborazione sui dati per renderlo pronto usare.
Ciò di cui avrai bisogno è un sistema end-to-end che si occupi di raschiare i dati, pulirli, convalidarli e verificarli, in modo che l'output finale possa essere integrato direttamente nei flussi di lavoro aziendali in un formato plug and play. Costruire un sistema del genere da zero è difficile come scalare una montagna partendo dalla sua base.
Il nostro team di PromptCloud fornisce un servizio di web scraping, ovvero tu ci fornisci i requisiti e noi ti forniamo i dati, il modello DaaS (Data-as-a-Service). Tutto quello che devi fare è accedere ai dati (che saranno nel formato e nel supporto di archiviazione di tua scelta) e integrarli con il tuo sistema attuale. Non solo estraiamo i dati da più siti Web, ma utilizziamo più controlli a vari livelli per assicurarci che i dati che forniamo siano puliti. Questi dati aiutano i nostri clienti in vari settori a utilizzare tecnologie all'avanguardia come l'intelligenza artificiale e l'apprendimento automatico per semplificare diversi processi e comprendere meglio i loro clienti.