
高品質データの欠如が AI の成長を制限しているのか?
公開: 2020-12-23AI の未来は質の高いデータの手の中にあります
少しばかげているようですね。 未来は人間の手の中にあるべきではありませんか? しかし、機械学習と人工知能の成長を見れば、最新のイノベーションが、今日の人間と機械によって生成される膨大な量のデータに便乗していることに気付くでしょう。 自動運転車や自然言語処理などの最新の技術革新で使用されているニューラル ネットワークとディープ ラーニング アルゴリズムの成長は、データの量と質の増加によってのみ可能になりました。 データが少ない場合、ほぼすべての AI アルゴリズムが同様の結果を生成しますが、ペタバイトのデータがある場合、ディープ ラーニング アルゴリズムが優れていることがわかります。
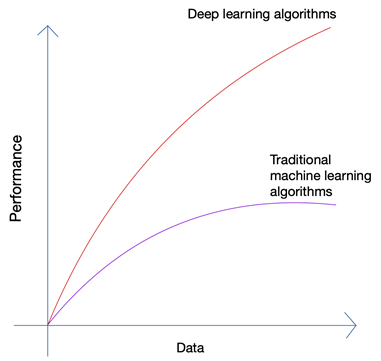
人間は限られた量のデータしか生成できません。ビッグデータ革命は主に、インターネットに接続するデバイスが増え、より多くのデータを生成することによって引き起こされました。 IoT 革命により、これまで以上に多くのデータが生成されました。 人間はこのような膨大なデータを解析することはできず、それがディープ ラーニングの基礎につながりました。
データの 3 つの主な問題
最先端の AI プロジェクトのためにデータを収集する場合、問題は量だけではありません。 アルゴリズムから最高の結果を得るには、データの量に関係なく、データの品質、クリーン度、および多様性が重要です。
a)。 量
数千行のデータしかない自動運転車用のアルゴリズムを作成しようとすると、必ず障害に直面します。 アルゴリズムが現実世界のシナリオで適切な結果を生成することを確認するには、大量のトレーニング データでアルゴリズムをトレーニングする必要があります。 現在、ほぼすべてのデバイスからログにアクセスできる機能と、Web からのほぼ無限のデータ ストリームのおかげで、データの収集はそれほど難しくありません。 適切なツールがあり、その使い方を知っている限り。
b)。 バラエティ
AI を使用して現実世界の問題に対処するためにアルゴリズムをトレーニングする場合、システムは可能な限りさまざまなデータ ポイントをすべて理解する必要があります。 さまざまなデータを取得できない場合、システムには固有のバイアスがあり、誤った結果が生成されます。
そのようなことは、米国の文学ダイジェストが開催した有名な 1936 年の大統領世論調査を含め、何度も起こっています。 それが予測した候補者は大統領選挙に勝つだろうが、最終的には 20% を超える大差で負けた。 しかし、同誌は 1,000 万人を対象に世論調査を行い、そのうち 227 万人が回答しました。これは、今日の基準から見ても天文学的な数です。 どこで問題が発生しましたか?

まあ、彼らは、国が大恐慌のどん底にあったときに雑誌を購読する余裕がなかった人々と一緒に、単に反応しなかった読者のはるかに多くの割合の感情を理解することができませんでした.
c)。 品質
最後の 2 つの要素は非常に重要であり、ある程度の努力でチェックし続けることができますが、データの品質は見逃しやすく、結果が一致しない場合でも検出するのは困難です。 データが汚れていたことを知る唯一の方法は、データが本番環境に入った後で再度分析することです。
データの品質を維持するいくつかの簡単な方法は、重複を削除し、入力される各行のスキーマを検証し、特定のハード リミットを設定して各行に入力される値をチェックし、外れ値を追跡することです。 自動化によって特定の要因をチェックできない場合は、手動による介入も必要になる場合があります。 エラーが忍び寄る主なポイントは、データ変換です。 特に、複数のソースからデータを蓄積している場合、すべてのデータ ポイントが同じ単位を持つとは限りません。 適切な方程式を使用して値を変換することは必須であり、全面的に実装する必要があります。
Web からスクレイピングされたデータは、構造化データ、半構造化データ、非構造化データで構成されている場合もあり、AI プロジェクトでこれらのさまざまな形式のデータを使用する場合は、それらすべてを確実に変換する必要があります。同じフォーマット。
データ品質は AI プロジェクトにどのように影響しますか?
データ品質は、あらゆる機械学習または AI プロジェクトに影響を与える可能性があります。 プロジェクトの規模によっては、データの単純なミスでさえ、予想外の結果につながる可能性があります。 レコメンデーション エンジンを作成していて、トレーニング データが十分にクリーンでない場合、レコメンデーションはユーザーにとってあまり意味がありません。
ただし、汚れたデータがこの結果に関与しているかどうかを把握することは困難な場合があります。 同様に、予測アルゴリズムを設計していて、データに特定の欠陥がある場合、一部の予測は依然として有効である可能性がありますが、一部はかなり外れている可能性があります. 点と点を結び付けて、ダーティ データがもたらした違いを実現することは、再現するのが非常に難しい場合があります。
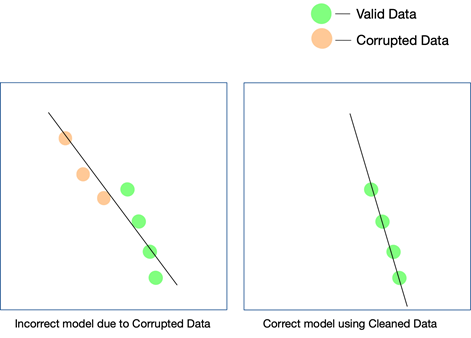
すべての AI プロジェクトは段階的に成長します。 最初のアルゴリズム決定が行われます。つまり、与えられたデータセットと特定のユース ケースに最適なアルゴリズムが決定されます。 データに矛盾がある場合、アルゴリズムの選択自体が失敗する可能性があり、しばらくしてからこの誤謬に気付くことになるかもしれません。
モデルが現実の世界で機能することを確認する唯一の方法は、クリーンなデータが AI システムに供給されるようにし、より多くのデータでテストを続けることです。 強化学習を使用して、モデルのパスが外れている場合にそれを修正することもできます。
Webスクレイピングは解決策になり得るか?
Webスクレイピングは解決策になる可能性がありますが、それは、プロジェクトで使用する前に、パイプラインを通過するさまざまな量のデータが完全にクリーニング、検証、および検証されていることを確認するために、他のいくつかのツールと組み合わせて使用 する場合に限られます. Web スクレイピング ツールを使用している場合でも、社内または有料のソフトウェアを問わず、Web からデータを取得するために、ツールがデータに対してこれらの後処理タスクを実行して準備を整えられる可能性は低いです。使用する。
必要なのは、データのスクレイピング、クリーニング、検証、および検証を処理するエンド ツー エンド システムであり、最終的な出力をプラグ アンド プレイ形式でビジネス ワークフローに直接統合できます。 このようなシステムをゼロから構築することは、山を根元から登るのと同じくらい困難です。
PromptCloudの私たちのチームは Web スクレイピング サービスを提供します。つまり、要件を提供すると、データ、DaaS (Data-as-a-Service) モデルが提供されます。 あなたがする必要があるのは、データ (選択した形式とストレージ メディアになります) にアクセスし、それを現在のシステムに統合することだけです。 複数の Web サイトからデータをスクレイピングするだけでなく、さまざまなレベルで複数のチェックを使用して、提供するデータがクリーンであることを確認します。 このデータは、さまざまな分野のクライアントが AI や機械学習などの最先端技術を使用して、さまざまなプロセスを合理化し、顧客をよりよく理解できるようにするのに役立ちます。