
هل يحد غياب البيانات الجيدة من نمو الذكاء الاصطناعي؟
نشرت: 2020-12-23يكمن مستقبل الذكاء الاصطناعي في أيدي البيانات عالية الجودة
يبدو قليلا من السخف أليس كذلك؟ ألا يجب أن يكمن المستقبل في يد الإنسان؟ ولكن إذا نظرت إلى نمو التعلم الآلي والذكاء الاصطناعي ، فستتمكن من اكتشاف أن أحدث الابتكارات قد ركزت على الكم الهائل من البيانات التي تم إنشاؤها بواسطة البشر والآلات اليوم. لم يكن نمو الشبكات العصبية وخوارزميات التعلم العميق المستخدمة في أحدث الابتكارات مثل السيارات ذاتية القيادة ومعالجة اللغة الطبيعية ممكنًا إلا بسبب النمو في كمية البيانات وجودتها. عندما يكون لديك بيانات أقل ، فإن جميع خوارزميات الذكاء الاصطناعي تقريبًا تنتج نتائج مماثلة ، ولكن عندما يكون لديك بيتابايت من البيانات ، يمكنك رؤية خوارزميات التعلم العميق تتألق.
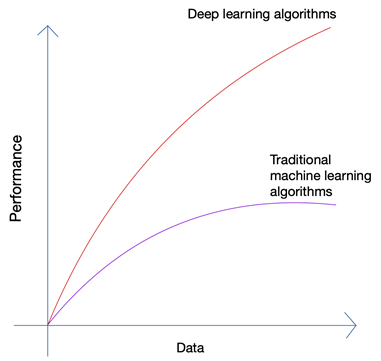
يمكن للبشر فقط إنتاج كمية محدودة من البيانات ، وكان السبب الرئيسي وراء ثورة البيانات الضخمة هو زيادة عدد الأجهزة المتصلة بالإنترنت وإنتاج المزيد من البيانات. أنتجت ثورة إنترنت الأشياء بيانات أكثر من أي وقت مضى. لا يمكن لأي إنسان تحليل مثل هذه البيانات الهائلة ، والتي أدت بدورها إلى أسس التعلم العميق.
القضايا الثلاث الرئيسية مع البيانات
الكمية ليست هي المشكلة الوحيدة عندما تقوم بجمع البيانات لمشروع الذكاء الاصطناعي المتطور الخاص بك. بغض النظر عن مقدار البيانات التي لديك ، فإن جودة البيانات ونظافتها وتنوعها مهمة بنفس القدر إذا كنت تريد أفضل النتائج من الخوارزمية الخاصة بك.
أ). كمية
إذا كنت تحاول إنشاء خوارزمية للسيارات ذاتية القيادة مع بضعة آلاف من صفوف البيانات فقط ، فأنت ملزم بمواجهة حواجز الطرق. للتأكد من أن الخوارزمية الخاصة بك تنتج نتائج مناسبة في سيناريوهات العالم الحقيقي ، تحتاج إلى تدريب الخوارزمية الخاصة بك على أطنان وأطنان من بيانات التدريب. بفضل القدرة على الوصول إلى السجلات من أي جهاز تقريبًا اليوم جنبًا إلى جنب مع تدفق البيانات اللانهائي تقريبًا من الويب ، فإن جمع البيانات ليس بالأمر الصعب ؛ طالما لديك الأدوات الصحيحة وتعرف كيفية استخدامها.
ب). متنوع
عندما تقوم بتدريب الخوارزميات الخاصة بك على معالجة مشاكل العالم الحقيقي باستخدام الذكاء الاصطناعي ، يحتاج نظامك إلى فهم كل التنوع المحتمل لنقاط البيانات الممكنة. إذا لم تكن قادرًا على الحصول على مجموعة متنوعة من البيانات ، فسيكون لنظامك تحيز متأصل ويؤدي إلى نتائج غير صحيحة.
لقد حدث هذا عدة مرات ، بما في ذلك الاستطلاع الرئاسي الشهير عام 1936 الذي أجرته The Literary Digest في الولايات المتحدة . المرشح الذي توقعت فوزه في السباق الرئاسي ، خسر في النهاية بهامش هائل يزيد عن 20٪. ومع ذلك ، استطلعت المجلة آراء 10 ملايين فرد ، استجاب منهم 2.27 مليون - وهو رقم فلكي حتى بمعايير اليوم. أين سارت الأمور بشكل خاطئ؟

حسنًا ، لقد فشلوا في فهم مشاعر النسبة الأكبر بكثير من القراء الذين لم يستجيبوا ببساطة إلى جانب أولئك الذين لا يستطيعون الاشتراك في مجلة عندما كانت البلاد في أعماق كساد شديد.
ج). جودة
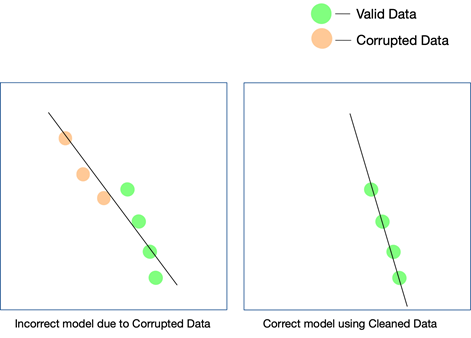
في حين أن العاملين الأخيرين مهمان حقًا ويمكن متابعتهما ببعض الجهود ، إلا أنه من الأسهل تفويت جودة البيانات ويصعب اكتشافها حتى عندما لا تتطابق نتائجك. الطريقة الوحيدة التي يمكنك من خلالها معرفة أن البيانات كانت غير نظيفة هي إذا قمت بتحليل البيانات مرة أخرى بعد أن دخلت حيز الإنتاج.
تتمثل بعض الطرق البسيطة للحفاظ على جودة البيانات في إزالة التكرارات ، والتحقق من صحة مخطط كل صف يأتي ، ووضع حدود صارمة معينة للحفاظ على التحقق من القيم التي تدخل كل صف ، وكذلك تتبع القيم المتطرفة. إذا كان لا يمكن السيطرة على عوامل معينة عن طريق الأتمتة ، فقد تكون التدخلات اليدوية ضرورية أيضًا. النقطة الرئيسية التي يمكن أن تتسلل فيها الأخطاء هي تحويلات البيانات . خاصة عندما تقوم بتجميع البيانات من مصادر متعددة ، لن تحتوي جميع نقاط البيانات على نفس الوحدات. يعد تحويل القيم باستخدام المعادلات المناسبة أمرًا ضروريًا ويجب تنفيذه في جميع المجالات.
قد تتكون البيانات التي يتم جمعها من الويب أيضًا من بيانات منظمة وشبه منظمة وغير منظمة ، وعندما تريد استخدام هذه الأشكال المختلفة من البيانات في مشروع الذكاء الاصطناعي الخاص بك ، ستحتاج إلى التأكد من تحويلها جميعًا إلى نفس الشكل.
كيف تؤثر جودة البيانات على مشاريع الذكاء الاصطناعي؟
يمكن أن تؤثر جودة البيانات على أي مشروع تعلم آلي أو ذكاء اصطناعي. اعتمادًا على مدى اتساع المشروع ، حتى الأخطاء البسيطة في البيانات يمكن أن تؤدي إلى نتائج بعيدة المنال. في حالة قيامك بإنشاء محرك توصيات ، ولم تكن بيانات التدريب الخاصة بك نظيفة بما يكفي ، فلن تكون التوصيات منطقية للمستخدمين.
ومع ذلك ، قد يكون من الصعب الحصول على ما إذا كانت البيانات غير النظيفة قد لعبت دورًا في هذه النتيجة. وبالمثل ، إذا كنت تصمم خوارزمية تنبؤ وكانت البيانات بها عيوب معينة ، فقد تظل بعض التوقعات جيدة بينما قد يكون بعضها بعيدًا بعض الشيء. قد يكون من الصعب للغاية إعادة إنشاء توصيل النقاط لإدراك الفرق الذي أحدثته البيانات القذرة.
ينمو كل مشروع من مشاريع الذكاء الاصطناعي على مراحل. يتم اتخاذ قرار خوارزمي مبدئي - أي الخوارزمية التي ستعمل بشكل أفضل في ضوء مجموعة البيانات وحالة الاستخدام المحددة ، يتم تحديدها. إذا كانت بياناتك تحتوي على تناقضات ، فقد يؤدي اختيارك للخوارزمية نفسها إلى إهمال ، وقد لا تدرك هذه المغالطة إلا بعد فترة طويلة.
الطريقة الوحيدة للتأكد من أن نموذجك يعمل في العالم الحقيقي هو ضمان تغذية البيانات النظيفة إلى نظام الذكاء الاصطناعي ومواصلة اختبارها على المزيد والمزيد من البيانات. يمكنك أيضًا استخدام التعلم المعزز لتصحيح مسار النموذج عندما يبتعد.
هل يمكن أن يكون تجريف الويب هو الحل؟
يمكن أن يكون تجريف الويب حلاً ، ولكن فقط إذا تم استخدامه مع العديد من الأدوات الأخرى للتأكد من أن تنوع وكمية البيانات التي تأتي عبر خط الأنابيب يتم تنظيفها والتحقق منها والتحقق من صحتها تمامًا قبل استخدامها في المشروع. حتى إذا كنت تستخدم أداة تجريف الويب ، سواء كانت داخلية أو برنامجًا مدفوعًا ، للحصول على البيانات من الويب ، فمن غير المرجح أن تكون الأداة قادرة على أداء مهام ما بعد المعالجة هذه على البيانات لجعلها جاهزة ليستخدم.
ما ستحتاج إليه هو نظام شامل يعتني بكشط البيانات وتنظيفها والتحقق من صحتها والتحقق منها ، بحيث يمكن دمج المخرجات النهائية مباشرة في سير عمل الأعمال في تنسيق التوصيل والتشغيل. إن بناء مثل هذا النظام من الصفر أمر صعب مثل تسلق الجبل بدءًا من قاعدته.
يوفر فريقنا في PromptCloud خدمة تجريف الويب - أي أنك تقدم لنا المتطلبات ، ونقدم لك البيانات ، نموذج DaaS (البيانات كخدمة). كل ما عليك فعله هو الوصول إلى البيانات (التي ستكون بالتنسيق ووسيلة التخزين التي تختارها) ، ودمجها مع نظامك الحالي. لا نقوم فقط بكشط البيانات من مواقع ويب متعددة ولكن نستخدم فحوصات متعددة على مستويات مختلفة للتأكد من أن البيانات التي نقدمها نظيفة. تساعد هذه البيانات في تمكين عملائنا في مختلف القطاعات من استخدام التقنيات المتطورة مثل الذكاء الاصطناعي والتعلم الآلي لتبسيط العمليات المختلفة وفهم عملائهم بشكل أفضل.