
Apakah Ketiadaan Data Berkualitas Membatasi Pertumbuhan AI?
Diterbitkan: 2020-12-23Masa Depan AI terletak di Tangan Data Berkualitas
Kedengarannya agak tidak masuk akal bukan? Bukankah masa depan ada di tangan manusia? Tetapi jika Anda melihat pertumbuhan Pembelajaran Mesin dan Kecerdasan Buatan, Anda akan dapat melihat bahwa inovasi terbaru telah mendukung sejumlah besar data yang dihasilkan oleh manusia dan mesin saat ini. Pertumbuhan jaringan saraf dan algoritma pembelajaran mendalam yang digunakan dalam inovasi terbaru seperti mobil self-driving dan pemrosesan bahasa alami hanya dimungkinkan karena pertumbuhan kuantitas dan kualitas data. Saat Anda memiliki data yang lebih sedikit, hampir semua algoritme AI menghasilkan hasil yang serupa, tetapi bila Anda memiliki data Petabyte, Anda dapat melihat algoritme pembelajaran mendalam bersinar.
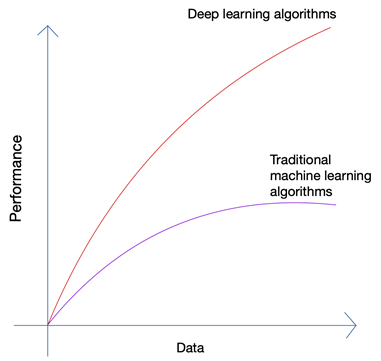
Manusia hanya dapat menghasilkan data dalam jumlah terbatas, dan revolusi data besar disebabkan terutama karena semakin banyak perangkat yang terhubung ke internet dan menghasilkan lebih banyak data. Revolusi IoT telah menghasilkan lebih banyak data daripada sebelumnya. Tidak ada manusia yang dapat menguraikan data sebesar itu, yang pada gilirannya mengarah pada fondasi pembelajaran yang mendalam.
Tiga Masalah Utama dengan Data
Kuantitas bukan satu-satunya masalah saat Anda mengumpulkan data untuk proyek AI canggih Anda. Tidak peduli berapa banyak data yang Anda miliki, kualitas, kebersihan, dan variasi data sama pentingnya jika Anda menginginkan hasil terbaik dari algoritme Anda.
sebuah). Kuantitas
Jika Anda mencoba membuat algoritme untuk mobil otonom dengan hanya beberapa ribu baris data, Anda pasti akan menghadapi hambatan. Untuk memastikan bahwa algoritme Anda menghasilkan hasil yang tepat dalam skenario dunia nyata, Anda perlu melatih algoritme Anda pada berton-ton data pelatihan. Berkat kemampuan untuk mengakses log dari hampir semua perangkat saat ini bersama dengan aliran data yang hampir tak terbatas dari web, mengumpulkan data tidak terlalu sulit; selama Anda memiliki alat yang tepat dan Anda tahu cara menggunakannya.
b). Variasi
Saat Anda melatih algoritme untuk mengatasi masalah dunia nyata menggunakan AI, sistem Anda perlu memahami semua kemungkinan variasi titik data. Jika Anda tidak bisa mendapatkan berbagai data, sistem Anda akan memiliki bias yang melekat dan menghasilkan hasil yang salah.
Hal tersebut telah terjadi beberapa kali, termasuk Jajak Pendapat Presiden tahun 1936 yang diadakan oleh The Literary Digest di Amerika Serikat . Kandidat yang telah diprediksi akan memenangkan pemilihan presiden, akhirnya kalah dengan selisih besar lebih dari 20%. Namun, majalah itu telah mensurvei 10 juta orang, di mana 2,27 juta di antaranya telah merespons — angka yang sangat besar bahkan menurut standar saat ini. Di mana ada yang salah?
Yah, mereka telah gagal untuk memahami sentimen dari persentase yang jauh lebih besar dari pembaca yang sama sekali tidak menanggapi bersama dengan mereka yang tidak mampu untuk berlangganan majalah ketika negara itu berada di kedalaman depresi yang hebat.
c). Kualitas
Sementara dua faktor terakhir sangat penting dan dapat terus diperiksa dengan beberapa upaya, kualitas data lebih mudah dilewatkan dan sulit dideteksi bahkan ketika hasil Anda tidak cocok. Satu-satunya cara Anda dapat mengetahui bahwa data tersebut tidak bersih adalah jika Anda menganalisis data lagi setelah masuk ke produksi.

Beberapa cara sederhana untuk menjaga kualitas data adalah dengan menghapus duplikat, memvalidasi skema setiap baris yang masuk, memiliki batasan keras tertentu untuk tetap memeriksa nilai yang masuk ke setiap baris, dan juga melacak outlier. Jika faktor-faktor tertentu tidak dapat dikendalikan melalui otomatisasi, intervensi manual mungkin juga diperlukan. Titik utama di mana kesalahan dapat merayap adalah konversi data . Terutama ketika Anda mengumpulkan data dari berbagai sumber, tidak semua titik data akan memiliki unit yang sama. Mengubah nilai menggunakan persamaan yang tepat adalah suatu keharusan, dan perlu diterapkan secara menyeluruh.
Data yang diambil dari web juga dapat terdiri dari data terstruktur, semi-terstruktur, dan tidak terstruktur , dan bila Anda ingin menggunakan berbagai bentuk data ini dalam proyek AI, Anda harus memastikan bahwa Anda mengonversi semuanya menjadi format yang sama.
Bagaimana Kualitas Data Mempengaruhi Proyek AI?
Kualitas data dapat memengaruhi pembelajaran mesin atau proyek AI apa pun. Bergantung pada seberapa luas proyeknya, bahkan kesalahan sederhana dalam data dapat menyebabkan hasil yang meleset. Jika Anda membuat mesin rekomendasi, dan data pelatihan Anda tidak cukup bersih, rekomendasi tidak akan masuk akal bagi pengguna.
Namun, mengetahui apakah data yang tidak bersih telah berperan dalam hasil ini mungkin sulit. Demikian pula, jika Anda merancang algoritme prediksi dan data memiliki kelemahan tertentu, beberapa prediksi mungkin masih berlaku sementara beberapa mungkin sedikit meleset. Menghubungkan titik-titik untuk menyadari perbedaan yang dibawa oleh data kotor mungkin sangat sulit untuk dibuat ulang.
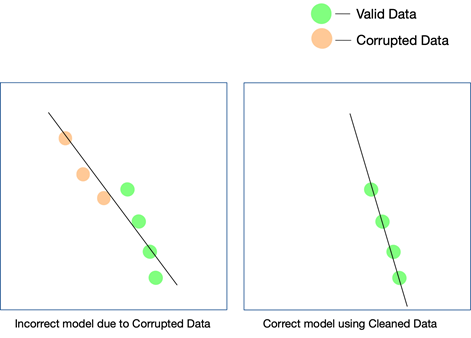
Setiap proyek AI tumbuh secara bertahap. Keputusan algoritmik awal dibuat — yaitu algoritme mana yang akan bekerja paling baik mengingat kumpulan data dan kasus penggunaan spesifik, diputuskan. Jika data Anda memiliki inkonsistensi, pilihan algoritme Anda sendiri mungkin akan gagal, dan Anda mungkin tidak menyadari kekeliruan ini sampai lama kemudian.
Satu-satunya cara untuk memastikan bahwa model Anda berfungsi di dunia nyata adalah memastikan data bersih diumpankan ke sistem AI dan terus mengujinya pada lebih banyak data. Anda juga dapat menggunakan pembelajaran yang diperkuat untuk memperbaiki jalur model saat menyimpang.
Bisakah Web Scraping menjadi Solusinya?
Pengikisan web dapat menjadi solusi, tetapi hanya jika digunakan dalam kombinasi dengan beberapa alat lain untuk memastikan bahwa variasi dan jumlah data yang datang melalui jalur pipa dibersihkan, diverifikasi, dan divalidasi secara menyeluruh sebelum digunakan dalam sebuah proyek. Bahkan jika Anda menggunakan alat pengikis web , baik itu perangkat lunak internal atau berbayar, untuk mendapatkan data dari web, kecil kemungkinan alat tersebut akan dapat melakukan tugas pasca-pemrosesan ini pada data untuk membuatnya siap menggunakan.
Yang Anda perlukan adalah sistem ujung ke ujung yang menangani pengikisan data, membersihkannya, memvalidasinya, dan memverifikasinya, sehingga hasil akhir dapat langsung diintegrasikan ke dalam alur kerja bisnis dalam format plug and play. Membangun sistem seperti itu dari awal sama sulitnya dengan mendaki gunung mulai dari dasarnya.
Tim kami di PromptCloud menyediakan layanan pengikisan web – yaitu Anda memberi kami persyaratan, dan kami memberi Anda data, model DaaS (Data-as-a-Service). Yang perlu Anda lakukan adalah mengakses data (yang akan dalam format dan media penyimpanan pilihan Anda), dan mengintegrasikannya dengan sistem Anda saat ini. Kami tidak hanya mengikis data dari beberapa situs web tetapi menggunakan beberapa pemeriksaan di berbagai tingkatan untuk memastikan bahwa data yang kami berikan bersih. Data ini membantu memberdayakan klien kami di berbagai sektor untuk menggunakan teknologi mutakhir seperti AI dan pembelajaran mesin untuk menyederhanakan berbagai proses dan memahami pelanggan mereka dengan lebih baik.