
已編入索引,但已被 Robots.txt 阻止:您需要知道的一切
已發表: 2021-07-01如果您的網站上有被 Google 編入索引但無法抓取的網頁,您將在 Google 搜索控制台 (GSC) 上收到“已編入索引,但已被 Robots.txt 阻止”消息。
雖然 Google 可以查看這些頁面,但它不會將它們顯示為目標關鍵字的搜索引擎結果頁面的一部分。
如果是這種情況,您將錯過為這些頁面獲得自然流量的機會。
這對於每月產生數千個自然訪問者的頁面尤其重要,只是遇到了這個問題。
此時,您可能對此錯誤消息有很多疑問。 你為什麼收到它? 這是怎麼發生的? 而且,更重要的是,如果這種情況發生在已經排名很好的頁面上,你如何修復它並恢復流量。
這篇文章將回答所有這些問題,並向您展示如何避免此問題再次在您的網站上發生。
如何知道您的網站是否存在此問題
通常,您應該會收到一封來自 Google 的電子郵件,通知您網站上的“索引覆蓋率問題”。 電子郵件如下所示:
該電子郵件不會具體說明受影響的頁面或 URL 是什麼。 您必須登錄到您的 Google Search Console 才能找到自己。
如果您沒有收到電子郵件,最好還是親自查看,以確保您的網站處於最佳狀態。
登錄 GSC 後,點擊 Index 下的 Coverage 進入 Index Coverage Report。 然後,在下一頁上,向下滾動以查看 GSC 報告的問題。
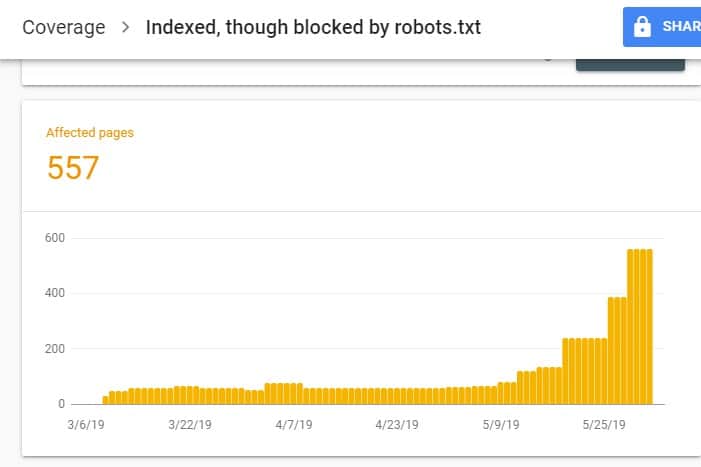
“已編入索引,但已被 robots.txt 阻止”標記在“有效但有警告”下。 這意味著 URL 本身沒有問題,但搜索引擎不會在搜索引擎結果中顯示頁面。
為什麼您的網站會出現此問題(以及如何解決)?
在開始考慮解決方案之前,您必須首先知道哪些頁面需要被索引並且必須出現在搜索結果中。
您在 GSC 上看到的帶有“已編入索引,但已被 robots.txt 阻止”問題的 URL 可能並非旨在為您的網站帶來自然流量。 例如,您的付費廣告活動的登陸頁面。 因此,修復頁面可能不值得您花費時間和精力。
以下是您的某些網頁出現此問題的原因以及您是否應該修復它們:
頁面 HTML 中的 Robots.txt和Noindex 元標記禁止規則
發生此問題的最常見原因是您或管理您網站的人在您網站的 robots.txt 上為該特定網址啟用了禁止規則,並在同一網址上添加了 noindex 元標記。
首先,網站所有者使用 robots.txt 通知搜索引擎抓取工具如何處理您的網站 URL。 在這種情況下,您在網站的 robots.txt 中的網站頁面和文件夾上添加了禁止規則。
當您打開網站的 robots.txt 文件時,您可能會看到以下內容:
用戶代理:* 禁止:/
在上面的示例中,這行代碼阻止所有網絡爬蟲 (*) 爬取您的網站頁面(禁止)包括您的主頁 (/)。 因此,所有搜索引擎都不會抓取或索引您的網站頁面。
您可以編輯 robots.txt 以挑選出網絡爬蟲(Googlebot、msnbot、magpie-crawler 等)並指定您不希望爬蟲觸及的頁面(/page1、/page2、/page3 等)。 )。
但是,如果您沒有對服務器的 root 訪問權限,則可以防止搜索引擎機器人使用 noindex 標記為您的網站頁面編制索引。
此方法與 robots.txt 上的禁止規則具有相同的效果。 但是,您不必在 robots.txt 文件中列出您網站上要防止出現在 SERP 上的不同頁面和文件夾,而是必須在您不想要的網站每個頁面上輸入 noindex 元標記出現在搜索結果中。
這是一個比以前的方法更耗時的過程,但它可以讓您更精細地控制要阻止的 URL。 這也意味著您的錯誤餘地較小。
修復:同樣,當您網站上的頁面對 robots.txt 文件和 noindex 標記有禁止規則時,就會出現 GSC 中的問題。
為了讓搜索引擎知道是否要索引頁面,它應該能夠從您的站點抓取它。 但是,如果您通過 robots.txt 阻止搜索引擎這樣做,它就不會知道如何處理該頁面。
通過使用 robots.txt 和 noindex 標籤來相互補充而不是相互競爭,您的網站將有更清晰和更直接的規則供搜索引擎機器人在處理其頁面時遵循。
為此,您必須編輯 robots.txt 文件。 對於 WordPress 網站所有者,使用帶有 robots.txt 編輯器(如 Yoast SEO 或 Rank Math)的 SEO 插件是最方便的。
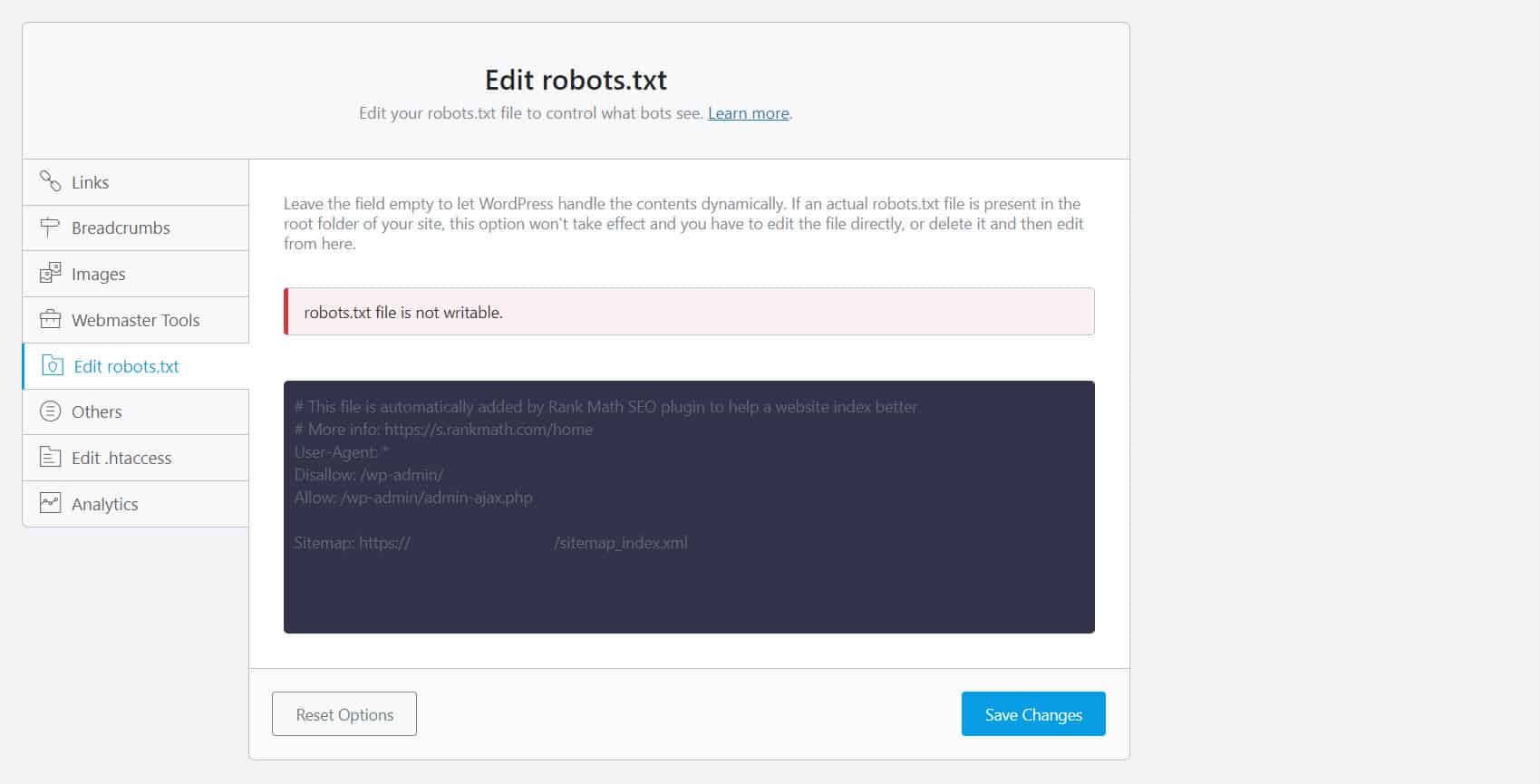

如果您無法寫入 robots.txt,您必須聯繫您的託管服務提供商以更改您的文件和文件夾的權限。
另一種方法是登錄到您的 FTP 客戶端或託管服務提供商的文件管理器。 這是開發人員的首選方法,因為他們可以完全控制如何編輯文件等。
錯誤的網址格式
您網站中嚴格意義上的並非真正“頁面”的 URL 可能會收到“已編入索引,但已被 robots.txt 阻止”消息。
例如,https://example.com?s=what+is+seo 是網站上的一個頁面,顯示查詢“什麼是 seo”的搜索結果。 此 URL 在站點範圍內啟用了搜索功能的 WordPress 站點中很普遍。
修復:通常情況下,無需解決此問題,假設 URL 是無害的並且不會嚴重影響您的搜索流量。
你不想被索引的頁面有內部鏈接
即使您不想索引的頁面上有 noindex 標記,Google 也可能會將它們視為建議而不是規則。 當您鏈接到具有 noindex 指令的頁面或在您的網站上搜索引擎抓取和索引的頁面上禁止規則的頁面時,這一點很明顯。
因此,即使您不想,您也可能會看到這些頁面出現在 SERP 上。
修復:您必須刪除指向此特定頁面的鏈接,並將它們引導至類似頁面。
為此,您必須使用 Screaming Frog(對 500 個 URL 的網站免費)或 Ahrefs 網站管理員工具(更好的免費替代品)等工具運行 SEO 審核來識別其內部鏈接,以確定哪些頁面鏈接到您的被阻止頁面。
使用 Ahrefs,在運行審計後轉到報告 > 內部頁面。 查找您已阻止網絡爬蟲和未編入索引的頁面,並在“鏈接數量”列中查看哪些頁面鏈接到它們。
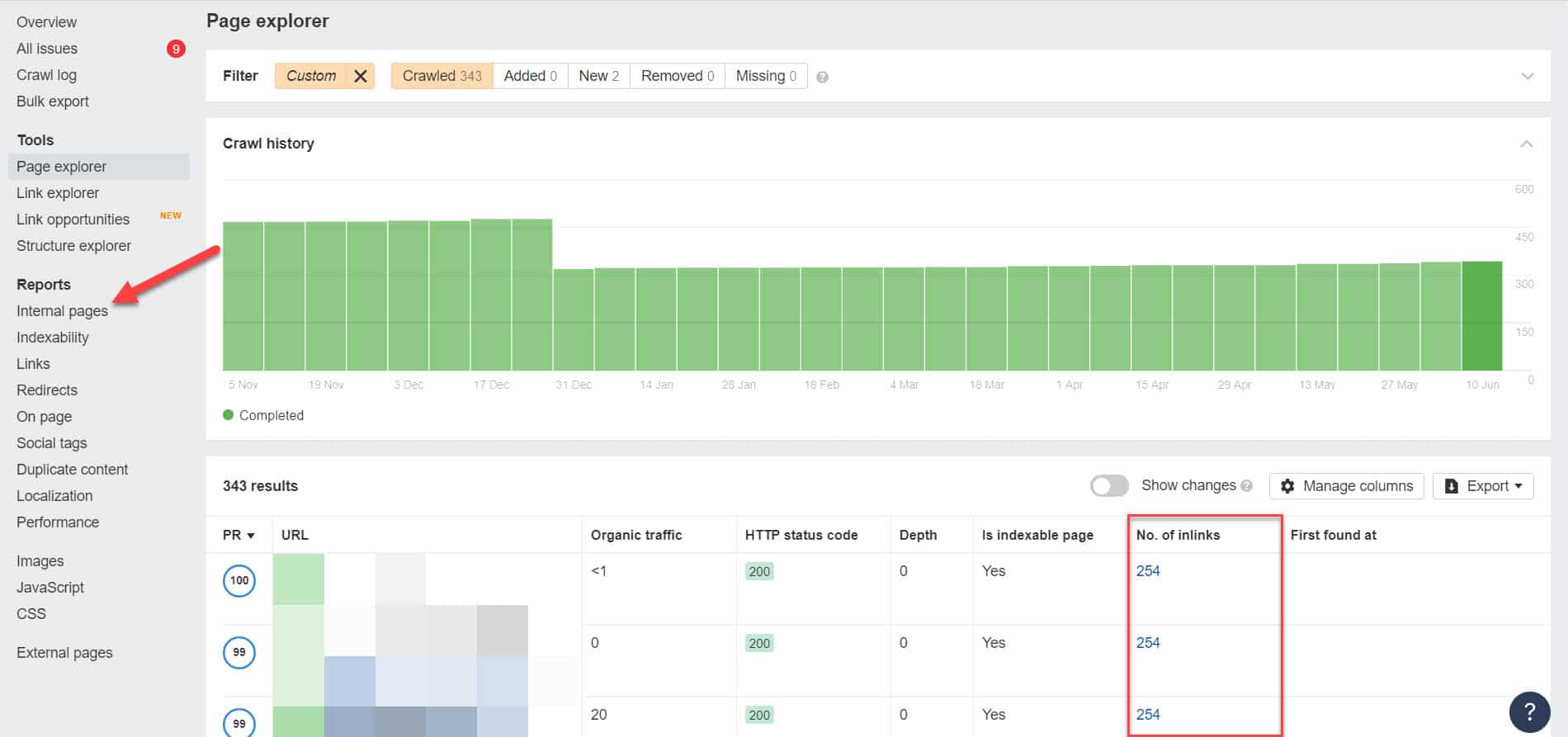
從這裡,一次編輯這些頁面的鏈接。 或者,您可以將它們替換為帶有 noindex 標記的頁面鏈接。
指向重定向鏈
如果您網站上的鏈接指向無窮無盡的重定向流,那麼 Googlebot 將在找到該頁面的實際 URL 之前停止通過每個鏈接。
這些重定向鏈也可能導致重複的內容問題,從而導致更大的 SEO 問題。 解決此問題的唯一方法是使用規範標籤標識您的首选和規範頁面,以便 Google 知道它應該抓取和索引的眾多頁面中的哪個頁面。
此外,請考慮鏈接到重定向而不是規範頁面會耗盡您的抓取預算。 如果重定向鏈接指向多個重定向,則您無法在網站中重要的頁面上使用抓取預算。 當它到達最重要的頁面時,Google 將無法在一段時間後正確抓取它們並將其編入索引。
修復:從您的站點中刪除重定向鏈接,並改為鏈接到規範頁面。
再次使用 Ahrefs 網站管理員工具,您可以在工具 > 鏈接瀏覽器頁面上查看您的重定向鏈接。 然後過濾結果以僅顯示您網站中的重定向鏈接。
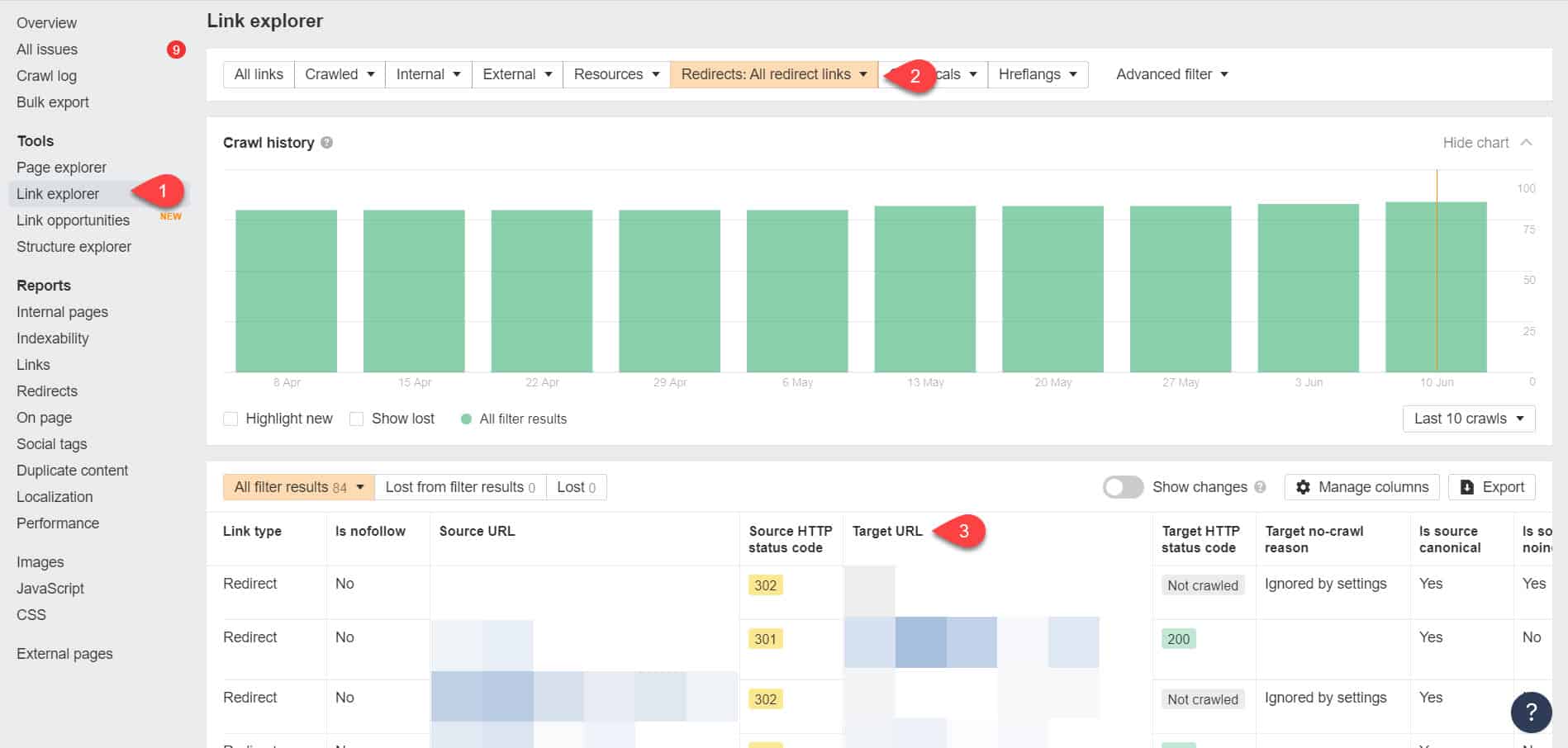
從結果中,確定哪些鏈接形成了無限的重定向鏈。 然後通過找到鏈接到重定向的每個頁面應該鏈接到的正確頁面來打破鏈。
解決此問題後該怎麼辦
對具有“已編入索引,但被 Robots.txt 阻止”問題的重要頁面實施上述解決方案後,您需要驗證更改,以便 Google Search Console 將其標記為已解決。
返回 GSC 中的索引覆蓋率報告,單擊您已修復的與此問題相關的鏈接。 在下一個屏幕上,單擊 Validate Fix 按鈕。
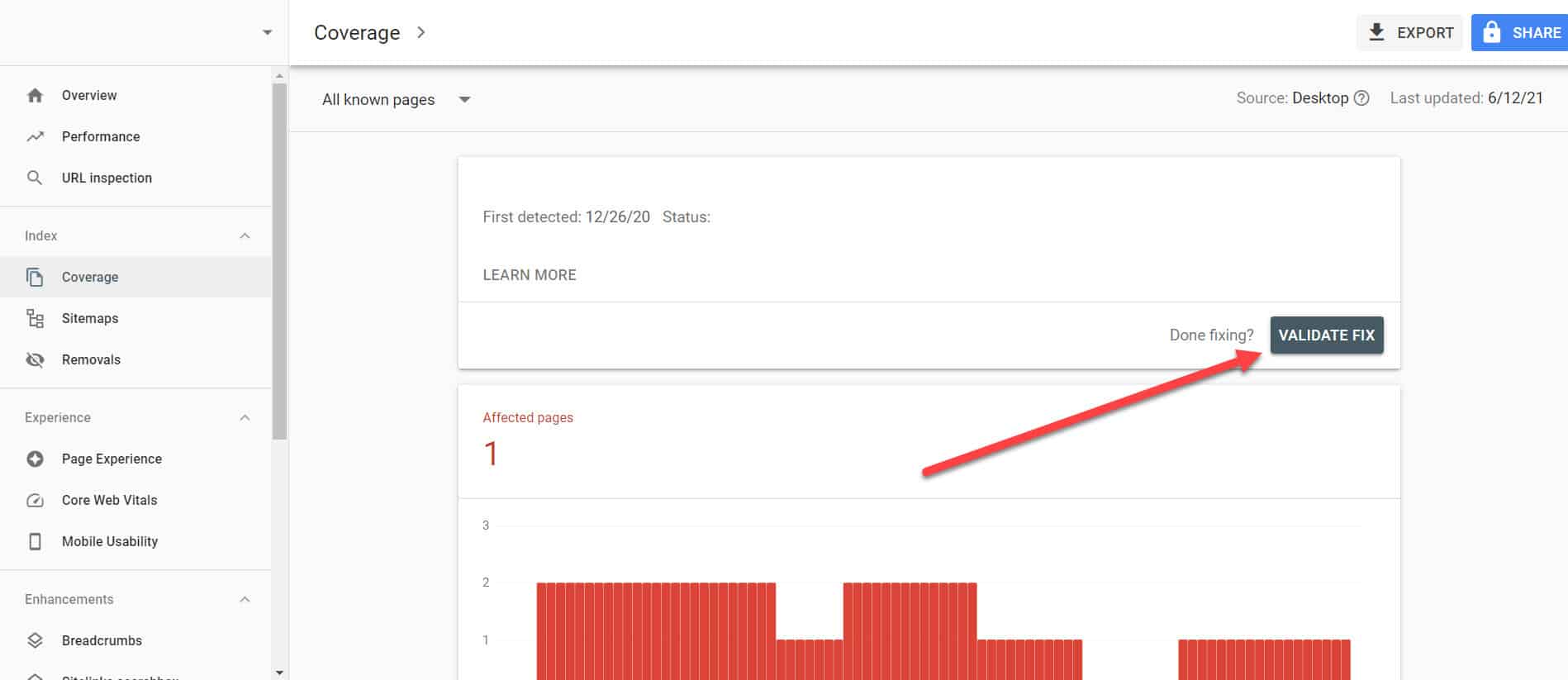
這將要求 Google 驗證該頁面是否不再存在問題。
結論
與 Google Search Console 發現的其他問題不同,“已編入索引,但已被 robots.txt 阻止”似乎是杯水車薪。 但是,這些下降可能會累積成整個網站的大量問題,這將阻止它產生自然流量。
通過遵循上述關於如何解決最重要頁面上的問題的指南,您可以通過優化您的網站以供 Google 正確抓取和索引,從而防止您的網站失去寶貴的流量。